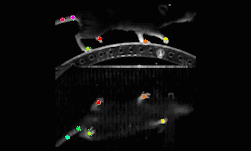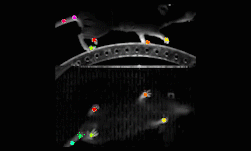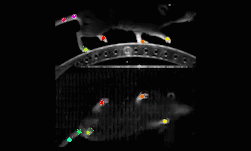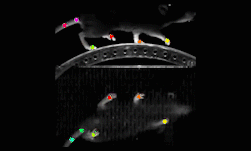
Researchers from Harvard University along with other collaborators in academia developed a deep learning-based method called DeepLabCut to automatically track and label body parts of moving species with human-like accuracy.
“Videography provides easy methods for the observation and recording of animal behavior in diverse settings, yet extracting particular aspects of a behavior for further analysis can be highly time-consuming,” the researchers stated in their paper. “We present an efficient method for markerless pose estimation based on transfer learning with deep neural networks that achieves excellent results with minimal training data,” the team explained.

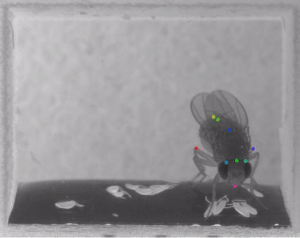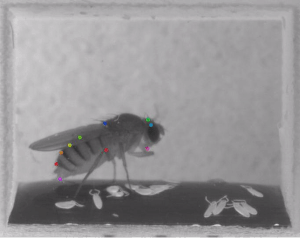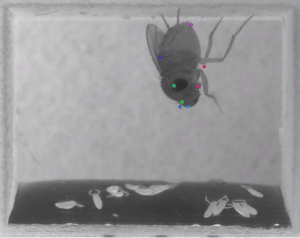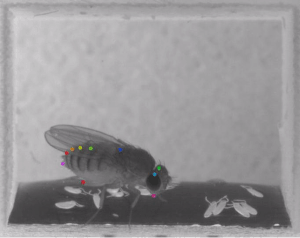
Using NVIDIA GeForce GTX 1080 Ti and NVIDIA TITAN Xp GPUs with the cuDNN-accelerated TensorFlow deep learning framework, the team trained their neural networks to perform pose estimation and body part detection on hundreds of images from the ImageNet dataset.
“We demonstrate the versatility of this framework by tracking various body parts in multiple species across a broad collection of behaviors. Remarkably, even when only a small number of frames are labeled (~200), the algorithm achieves excellent tracking performance on test frames that is comparable to human accuracy,” the team said.

The toolbox works on mice and Drosophila, however, there are no limitations on the framework and the toolbox can be applied to other organisms, the researchers said.
Tracking animals via motion capture can reveal new clues about their biomechanics as well as offer a glimpse into how their brain works. In humans, motion capture and tracking can aid in physical therapy and help athletes achieve records that were unimaginable in the past.
“This solution requires no computational body-model, stick figure, time-information, or sophisticated inference algorithm,” the researchers said. “Thus, it can also be quickly applied to completely different behaviors that pose qualitatively distinct challenges to computer vision, like skilled reaching or egg-laying in Drosophila.”
One case study shows the project implemented on a horse.

The code is available on GitHub and the paper was recently published in Nature.
AI-Generated Summary
- Researchers from Harvard University developed DeepLabCut, a deep learning-based method to track and label body parts of moving species with human-like accuracy.
- Using NVIDIA GPUs and the cuDNN-accelerated TensorFlow framework, the team trained neural networks to perform pose estimation and body part detection on hundreds of images.
- DeepLabCut can be applied to various organisms and behaviors, and its code is available on GitHub, with the paper published in Nature.
AI-generated content may summarize information incompletely. Verify important information. Learn more