
This post covers best practices for async compute and overlap on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
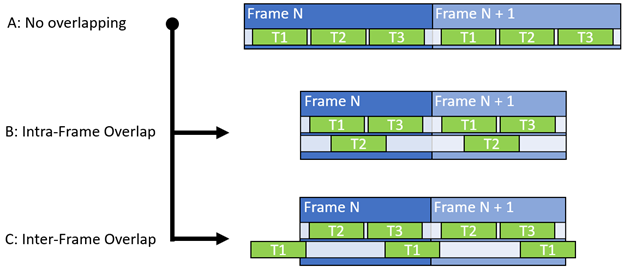
The general principle behind async compute is to increase the overall unit throughput by reducing the number of unused warp slots and to facilitate the simultaneous use of nonconflicting datapaths. The most basic communication setup towards the GPU uses a single queue to synchronously push and execute graphics, compute, and copy workloads (Figure 1-A).
Under ideal circumstances, all workloads generate high unit throughputs (Figure 2-A) and use all available warp slots (Figure 2-B) and different datapaths. In practice, only a fraction of the maximum unit throughput is truly used. Async compute offers you an opportunity to increase the hardware unit use by processing multiple workloads in parallel and effectively raising the overall processing throughput.
A classic mistake is to focus only on SM occupancy (unused warp slots) to identify potential async compute workloads. The GPU is a complex beast and other metrics such as top unit throughputs (SOL) play an equal if not more important role than SM occupancy alone. For more information, see The Peak-Performance-Percentage Analysis Method for Optimizing Any GPU Workload.
Thus, in addition to SM occupancy, you should also consider unit throughputs, register file occupancy, group shared memory, and different datapaths. After the ideal pair is identified, the compute workload is moved to the async queue (Figure 1, B and C). It is synchronized with the sync/main queue using fences to ensure the correct execution order.
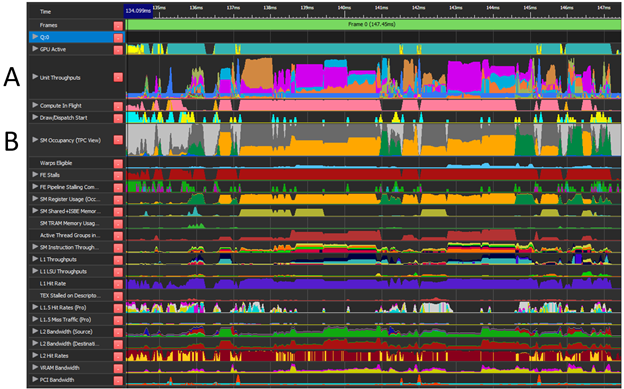
NVIDIA Nsight Graphics offers the GPU Trace feature (Figure 2), which provides detailed performance information of various GPU units sampled across the frame. This performance information is critical in identifying potential workload overlaps.
Knowing where to start looking is the key to identifying potential overlap opportunities. Always consider unit throughput first, as it represents a theoretical maximum percentage (SOL) at which a certain unit type can operate. It also helps to identify the type of datapath being used.
Attempting to stack workloads and unit throughputs over the maximum percentage (100%) doesn’t work and it also degrades the overall performance.
When you are looking at unit throughputs and SM occupancy, also consider resource barriers and pipeline changes. The GPU is perfectly capable of processing a batch of tiny draw calls simultaneously across different SMs, where each call is responsible for a small number of warps individually. It even coalesces them into a single block if the conditions are right.
A change to the graphics, compute, or copy workload type (also known as a subchannel switch) or the usage of a UAV barrier on the same queue triggers a wait for the idle (WFI) task. WFI forces all warps on the same queue to be fully drained, leaving a workload gap in the unit throughputs and SM occupancy.
If WFI is unavoidable and causes a large throughput gap, filling that gap with async compute could be a good solution. The common source of barriers and WFIs are as follows:
- Resource transitions (barriers) between draw, dispatch, or copy calls
- UAV barriers
- Raster state changes
- Back-to-back mixing of draw, dispatch, and copy calls on the same queue
- Descriptor heap changes
Recommended
- Use GPU Trace provided by NVIDIA Nsight Graphics to identify potential overlap pairs:
- Look for a combination of low top unit throughput metrics.
- If the SM occupancy shows a significant portion of unused warp slots, then it’s potentially an effective overlap. SM Idle % without conflicting high throughput units is almost always a guaranteed improvement.
- Capture another GPU Trace to confirm the result.
- Try overlapping different datapaths. For example, FP, ALU, Memory Requests, RT Core, Tensor Core, Graphics-pipe.
- FP, ALU, and Tensor share a different register file.
- Overlap compute workloads with other compute workloads. This scenario is very efficient on NVIDIA Ampere Architecture GPUs.
- Consider converting some of the graphics work such as post-processing passes to compute: this can present new overlap opportunities.
- Consider running async work between frames (Figure 1-C).
- Measure the performance difference over the whole frame or average over multiple frames if intraframe async compute is implemented.
- Verify the behavior across different GPU tiers. High-end GPUs have more SM units, so more potential for overlap.
- Verify the behavior at different resolutions. Low resolution usually means less pixel warps and thus more idle time for the SMs and more overlap potential.
Not recommended
- Don’t only focus purely on the SM warp occupancy, start by looking at unit throughputs.
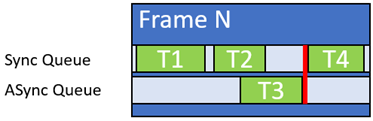
- Don’t use long async compute workloads unless they can finish comfortably before the dependency on the sync queue (Figure 3).
- Don’t overlap workloads that use the same resource for reading and writing, as it causes data hazards.
- Don’t overlap workloads with high L1 and L2 usage and VRAM throughput metrics. Oversubscription or reduction in cache hit-rate will result in performance degradation.
- Be careful with more than two queues if hardware-accelerated GPU scheduling is disabled. Software scheduled workloads from more than two queues (copy queue aside) may result in workload serialization.
- Be careful with overlapping compute-over-compute workloads where both cause WFIs. WFIs during simultaneous compute on both queues can result in synchronization across the workloads. Frequent descriptor heap changes on the async queue may cause additional WFIs.
- Don’t use DX12 command queue priorities to influence async and sync workload priorities. The interface simply dictates the queue from which the commands are consumed first and does not affect warp priorities in any meaningful way.
- Don’t overlap RTCore workloads. Both share the same throughput units and due to interference will degrade performance.
Examples with GPU Trace
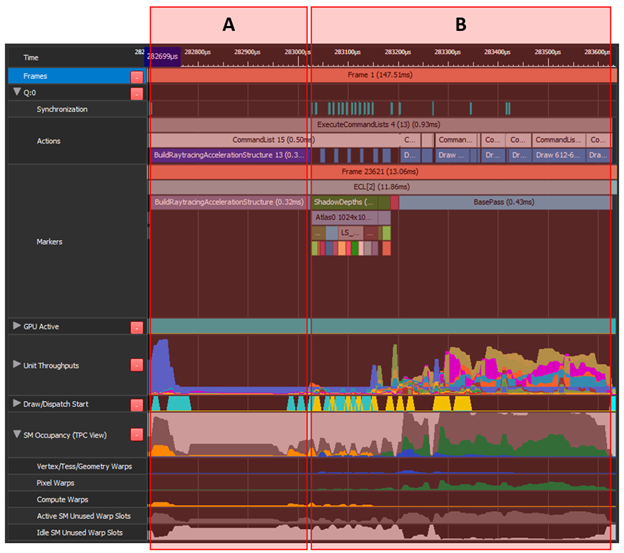
Move “A” (Build Acceleration Structure) to async compute over “B” (shadow mapping and gbuffer). “A” has a low top unit throughput and many unused warp slots. The same applies for the first ~40% of “B”, which combined can be an efficient overlap.
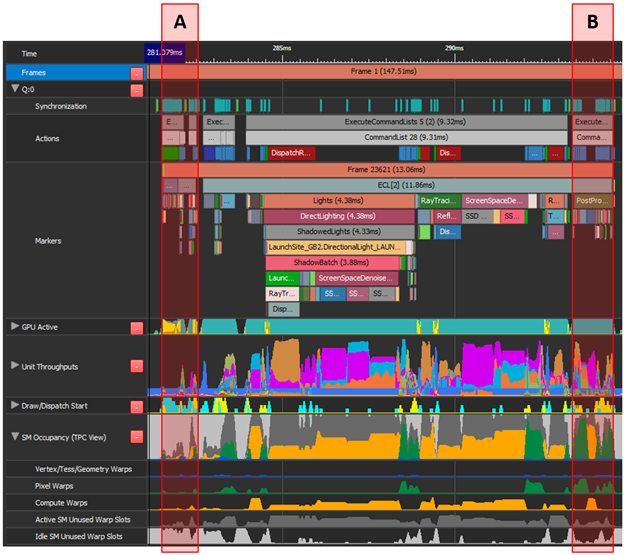
“A” consists of character skinning, copy calls, and some graphics. The highest throughput unit is PCI 12.7%. “B” performs post-processing, a mix of graphics and compute work, with the highest average throughput metric SM 37.6%.
Both areas have no conflicting highest throughput units and overlapping “B” over the next frame’s “A” also makes use of wasted warp slots between the frames. However, the challenging part is to convert all graphics work to compute and trigger frame-present from the async queue.
Potential overlap combinations
Table 1 shows a few common overlap combinations with the provided rationale. Always consider your application’s unit throughput first before implementing any of these.
| Workload A | Workload B | Rational |
| Math-limited compute | Shadow map rasterization | Shadow maps are usually graphics-pipe dominated (CROP, PROP, ZROP, VPC, RASTER, PD, VAF, and so on) and have little interference with heavy compute work. |
| Ray tracing | Math-limited compute | If RT is RTCore dominated, the time spent traversing triangles in the BVH can be overlapped with something like denoising for the previous ray tracing pass or some other math-limited post-processing pass. |
| DLSS | Build Acceleration Structure | The majority of the DLSS workload is executed on Tensor Cores, leaving the FP and ALU datapaths mostly unused. Building acceleration structures usually has a low throughput impact and mostly depends on FP and ALU datapaths, making it an ideal overlap-candidate for DLSS. |
| Any long workload | Many short workloads with back-to-back resource synchronization or UAV barriers. | Back-to-back resource synchronization is usually damaging for efficient unit throughput and SM warp occupancy, which provides an opportunity to be overlapped with async compute. |
| Post-process at the end of previous frame | G-buffer fills at the start of next frame | Inter-frame overlap can provide substantial perf gains, provided the application is able to invoke Present() from the compute queue. |
| Build acceleration structure | G-Buffer, shadow maps, and so on | Both workloads A and B are common to underuse the throughput units or to use non-conflicting paths. In addition, build acceleration structure is a compute workload and is fairly easy to move onto the async queue. |
| Ray tracing | Shadow map rasterization | RTCore / FP overlaps Graphics (ZROP/PROP/RASTER) datapath. See Example 1. |
Acknowledgements
Special thanks for reviewing and providing valuable feedback to Alexey Panteleev, Leroy Sikkes, Louis Bavoil, and Patrick Neill.
