NVIDIA NeMo has released the T5-TTS model, a significant advancement in text-to-speech (TTS) technology. Based on large language models (LLMs), T5-TTS produces more accurate and natural-sounding speech. By improving alignment between text and audio, T5-TTS eliminates hallucinations such as repeated spoken words and skipped text. Additionally, T5-TTS makes up to 2x fewer word pronunciation errors compared to other open-source models such as Bark and SpeechT5.
Listen to T5-TTS model audio samples.
NVIDIA NeMo is an end-to-end platform for developing multimodal generative AI models at scale anywhere—on-premises and on any cloud.
The role of LLMs in speech synthesis
LLMs have revolutionized natural language processing (NLP) with their remarkable ability to understand and generate coherent text. Recently, LLMs have been widely adopted in the speech domain, using vast amounts of data to capture the nuances of human speech patterns and intonations. LLM-based speech synthesis models produce speech that is not only more natural, but also more expressive, opening up a world of possibilities for applications in various industries.
However, similar to their use in text domain, speech LLMs face the hallucinations challenges, which can hinder their real-world deployment.
T5-TTS model overview
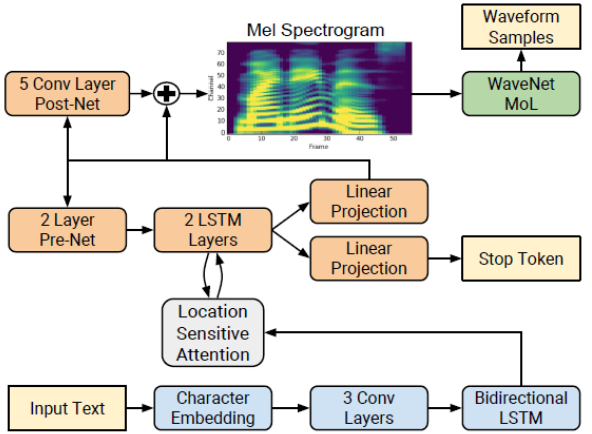
The T5-TTS model leverages an encoder-decoder transformer architecture for speech synthesis. The encoder processes text input, and the auto-regressive decoder takes a reference speech prompt from the target speaker. The auto-regressive decoder then generates speech tokens by attending to the encoder’s output through the transformer’s cross-attention heads. These cross-attention heads implicitly learn to align text and speech. However, their robustness can falter, especially when the input text contains repeated words.

Addressing the hallucination challenge
Hallucination in TTS occurs when the generated speech deviates from the intended text, causing errors ranging from minor mispronunciations to entirely incorrect words. These inaccuracies can compromise the reliability of TTS systems in critical applications like assistive technologies, customer service, and content creation.
The T5-TTS model addresses this issue by more efficiently aligning textual inputs with corresponding speech outputs, significantly reducing hallucinations. By applying monotonic alignment prior and connectionist temporal classification (CTC) loss, the generated speech closely matches the intended text, resulting in a more reliable and accurate TTS system. For word pronunciation, the T5-TTS model makes 2x fewer errors compared to Bark, 1.8x fewer errors compared to VALLE-X (open-source implementation), and 1.5x fewer errors compared to SpeechT5 (Figure 2).

Implications and future considerations for research
The release of the T5-TTS model by NVIDIA NeMo marks a significant advancement in TTS systems. By effectively addressing the hallucination problem, the model sets the stage for more reliable and high-quality speech synthesis, enhancing user experiences across a wide range of applications.
Looking forward, the NVIDIA NeMo team plans to further refine the T5-TTS model by expanding language support, improving its ability to capture diverse speech patterns, and integrating it into broader NLP frameworks.
Explore the NVIDIA NeMo T5-TTS model
The T5-TTS model represents a major breakthrough in achieving more accurate and natural text-to-speech synthesis. Its innovative approach to learning robust text and speech alignment sets a new benchmark in the field, promising to transform how we interact with and benefit from TTS technology.
To access the T5-TTS model and start exploring its potential, visit NVIDIA/NeMo on GitHub. Whether you’re a researcher, developer, or enthusiast, this powerful tool offers countless possibilities for innovation and advancement in the realm of text-to-speech technology. To learn more, see Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment.
Acknowledgments
We extend our gratitude to all the model authors and collaborators who contributed to this work, including Paarth Neekhara, Shehzeen Hussain, Subhankar Ghosh, Jason Li, Boris Ginsburg, Rafael Valle, and Rohan Badlani.