
Stunning audio content is an essential component of virtual worlds. Audio generative AI plays a key role in creating this content, and NVIDIA is continuously pushing the limits in this field of research. BigVGAN, developed in collaboration with the NVIDIA Applied Deep Learning Research and NVIDIA NeMo teams, is a generative AI model specialized in audio waveform synthesis that achieves state-of-the-art results. BigVGAN generates waveforms orders of magnitude faster than real time and shows strong robustness with various audio types, including speech, environmental sounds, and music.
This post discusses BigVGAN v2, which delivers significant improvements in speed and quality, empowering a future where generated audio is indiscernible from real audio. BigVGAN v2 highlights include:
- State-of-the-art audio quality measured by diverse metrics across many audio types.
- Up to 3x faster synthesis speed by leveraging optimized CUDA kernels.
- Ready-to-use pretrained checkpoints supporting diverse audio configurations.
- Support for a sampling rate of up to 44 kHz, which covers the highest sound frequency humans can hear.
BigVGAN: A universal neural vocoder
BigVGAN is a universal neural vocoder specialized in synthesizing audio waveforms using Mel spectrograms as inputs. Neural vocoders are a cornerstone method in audio generative AI that generate sound waves from compact acoustic features, such as Mel spectrogram. BigVGAN is available as open source through NVIDIA/BigVGAN on GitHub.
BigVGAN is a fully convolutional architecture (Figure 1) with several upsampling blocks using transposed convolution followed by multiple residual dilated convolution layers. It features a novel module, called anti-aliased multiperiodicity composition (AMP), which is specifically designed for generating waveforms.
AMP is specialized in synthesizing high-frequency and periodic sound waves, drawing inspiration from audio signal processing principles. It applies a periodic activation function, called Snake, which provides an inductive bias to the architecture in generating periodic sound waves. It also applies anti-aliasing filters to reduce undesired artifacts in the generated waveforms. To learn more, see BigVGAN: A Universal Neural Vocoder with Large-Scale Training.

Generating every sound in the world
Waveform audio generation, a crucial component in building virtual worlds, has long been an active research area. Despite its importance, current vocoding methods often produce audio lacking fine details in high-frequency sound waves. BigVGAN v2 effectively addresses this issue, providing high-quality audio with enhanced fine details.
BigVGAN v2 is trained using NVIDIA A100 Tensor Core GPUs and up to more than 100x larger audio data than its predecessor. Aimed at encapsulating every sound in the world, the dataset includes speech in multiple languages, environmental sounds from everyday objects, and diverse instruments. As a result, BigVGAN v2 can generate high-quality sound waves from numerous domains with a single model.
Below, listen to audio comparisons of real recordings and generated samples from BigVGAN and BigVGAN v2 at the 24 kHz sampling rate. BigVGAN v2 generates high-quality sound waves.
Recordings (24 kHz)
BigVGAN
BigVGAN v2
Reaching the highest frequency sound the human ear can detect
Previous waveform synthesizers were limited to sampling rates between 22 kHz and 24 kHz. BigVGAN v2, however, expands this range to a 44 kHz sampling rate, encapsulating the entire human auditory spectrum. This matches the highest frequencies the human ear can detect, which do not exceed a sampling rate of 40 kHz. As a result, BigVGAN v2 can reproduce comprehensive soundscapes, capturing everything from the robust reverberations of drums to the crisp shimmer of crash cymbals in music, for example.
Below, listen to audio comparisons of real recordings and generated samples from two BigVGAN v2 models, one for the 24 kHz sampling rate and another for the 44 kHz sampling rate.
Recordings (44 kHz)
BigVGAN v2 (24 kHz)
BigVGAN v2 (44 kHz)
Faster synthesis with custom CUDA kernels
Compared to its predecessor, BigVGAN v2 also features accelerated synthesis speed by using custom CUDA kernels, with up to 3x faster inference speed than the original BigVGAN. The optimized inference CUDA kernels written for BigVGAN v2 can generate audio waveforms up to 240x faster than real time on a single NVIDIA A100 GPU.
BigVGAN v2 audio quality results
BigVGAN v2 24 kHz shows better audio quality for speech and general audio compared to its open-sourced predecessor—and by a significant margin (Figures 2 and 3).

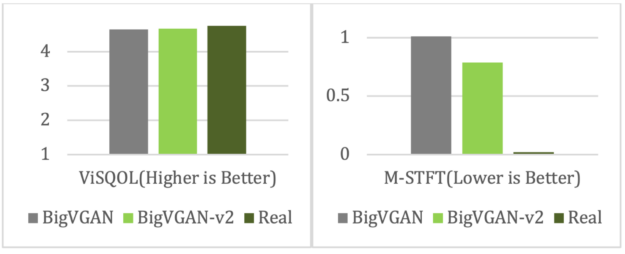
In addition, the new BigVGAN v2 44 kHz model shows comparable audio quality to Descript Audio Codec (.dac), an open-source high-quality neural audio codec (Figures 4 and 5).


All results show the quality of generated waveforms with respect to the following metrics:
- Perceptual Evaluation of Speech Quality (PESQ)
- Virtual Speech Quality Objective Listener (ViSQOL)
- Multi-Resolution Short-Time Fourier Transform (M-STFT)
- Periodicity Root Mean Square Error (Periodicity)
- Voice/Unvoiced F1 Score (V/UV F1)
Conclusion
NVIDIA is committed to delivering the best audio generative AI accessible to all. The release of BigVGAN v2 pushes neural vocoder technology and audio quality to new heights, even reaching the limits of human auditory perception.
BigVGAN v2 sets a new standard in audio synthesis, delivering state-of-the-art quality across all audio types, covering the full range of human hearing. Its synthesis is now up to 3x faster than the original BigVGAN, ensuring efficient processing for diverse audio configurations.
Before diving into BigVGAN v2, we encourage users to review the model card for a seamless experience.
