
Today, in partnership with NVIDIA, Google Cloud announced Dataflow is bringing GPUs to the world of big data processing to unlock new possibilities. With Dataflow GPU, users can now leverage the power of NVIDIA GPUs in their machine learning inference workflows. Here we show you how to access these performance benefits with BERT.
Google Cloud’s Dataflow is a managed service for executing a wide variety of data processing patterns including both streaming and batch analytics. It has recently added GPU support can now accelerate machine learning inference workflows, which are running on Dataflow pipelines.
Please check out Google Cloud’s launch post for more exciting new features. In this post, we will showcase the performance benefits and TCO improvement with NVIDIA GPU acceleration by deploying a Bidirectional Encoder Representations from Transformers (BERT) model fine-tuned on “Question Answering” tasks on Dataflow. We show TensorFlow inference in Dataflow with CPU, how to run the same code on GPU with a significant performance boost, showcase the best performance after we convert the model through NVIDIA TensorRT, and deploy through TensorRT’s python API with Dataflow. Check out NVIDIA sample code to try now.
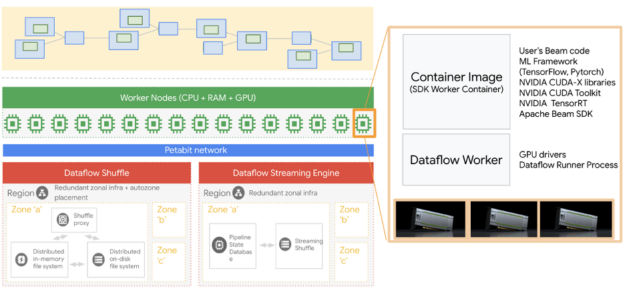
There are several steps we will be touching on in this post. We start by creating an environment on our local machine to run all of these Dataflow jobs. For additional details, please refer to the Dataflow Python quick start guide.
Creating an environment
It is recommended to create a virtual environment for Python, we use virtualenv here:
virtualenv -p <point_to_python3.6_version> <env_name>
When using Dataflow, it is required to align the Python version in your development environment with the Dataflow runtime Python version. More specifically, when running a Dataflow pipeline, you should use the same Python version and Apache Beam SDK version to avoid unexpected errors.
Now, we activate the virtual environment.
source <env_name>/bin/activate
One of the most important things to pay attention to before activating a virtual environment is to be sure that you are not operating in another virtual environment, as this usually causes issues.
After activating our virtual environment, we are ready to install the required packages. Even though our jobs are running on Dataflow, we still need a couple of packages locally so that Python does not complain when we run our code locally.
pip install apache-beam[gcp]
pip install TensorFlow==2.3.1
You can experiment with different versions of TensorFlow but the key here is to align the version you have here and the version that you will be using in the Dataflow environment. Apache Beam and its Google Cloud components are also required.
Getting the fine-tuned BERT model
NVIDIA NGC has plenty of resources ranging from GPU-optimized containers to fine-tuned models. We explore several NGC resources.
The first resource we will be using is a BERT large model that is fine-tuned for the SquadV2 question answering task and contains 340 million parameters. The following command will download the BERT model.
wget --content-disposition
https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_savedmodel_large_qa_squad2_amp_384/versions/19.03.0/zip -O bert_tf_savedmodel_large_qa_squad2_amp_384_19.03.0.zip
With the BERT model we just downloaded, automatic mixed precision (AMP) is used during training and the sequence length is 384.
We also need a vocabulary file and we get it from a BERT checkpoint that can be obtained from NGC with the following command:
wget --content-disposition
https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad2_amp_128/versions/19.03.1/zip -O bert_tf_ckpt_large_qa_squad2_amp_128_19.03.1.zip
After getting these resources, we just need to uncompress them and locate them in our working folder. We will be using a custom docker container and these models will be included in our image.
Custom Dockerfile
We will be using a custom Dockerfile that is derived from a GPU-optimized NGC TensorFlow container. NGC TensorFlow (TF) containers are the best option when accelerating TF models using NVIDIA GPUs.
We then add a couple of more steps to copy these models and the files we have. You can find the Dockerfile here and below is a snapshot of the Dockerfile.
FROM nvcr.io/nvidia/tensorflow:20.11-tf2-py3
RUN pip install --no-cache-dir apache-beam[gcp]==2.26.0 ipython pytest pandas && \
mkdir -p /workspace/tf_beam
COPY --from=apache/beam_python3.6_sdk:2.26.0 /opt/apache/beam /opt/apache/beam
ADD. /workspace/tf_beam
WORKDIR /workspace/tf_beam
ENTRYPOINT [ "/opt/apache/beam/boot"]
The next steps are to build the docker file and push it to the Google Container Registry (GCR). You can do this with the following command. Alternatively, you can use the script we created here. If you are using the script from our repo, you can simply do bash build_and_push.sh
project_id="<your_project_id>"
docker build . -t "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
docker push "gcr.io/${project_id}/tf-dataflow-${USER}:latest"
Running jobs
If you have already authenticated your Google account, you can simply run the Python files we provided here by calling the run_cpu.sh and run_gpu.sh scripts are available in the same repo.
CPU TensorFlow Inference in Dataflow (TF-CPU)
The bert_squad2_qa_cpu.py file in the repo is designed to answer questions based on a description text document. The batch size is 16, meaning that we will be answering 16 questions at each inference call and there are 16,000 questions (1,000 batches of questions). Note that BERT could be fine-tuned for other tasks given a specific use case.
When running a job on Dataflow, by default it auto-scales based on real-time CPU usage. If you want to disable this feature you need to set autoscaling_algorithm to NONE. This will let you pick how many workers to use throughout the life of your job. Alternatively, you can let Dataflow auto-scale your job and limit the maximum number of workers to be used by setting the max_num_workers parameter.
We recommend setting a job name rather than using the auto-generated name to better follow your jobs by setting the job_name parameter. This job name will be the prefix for the compute instance that is running your job.
Accelerating with GPU (TF-GPU)
To execute the same dataflow TensorFlow inference job with GPU support, we need to set the following parameters. For additional information, please refer to Dataflow GPU documentation. For additional information, please refer to Dataflow GPU documentation.
--experiment "worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver"
The parameter preceding enables us to have an NVIDIA T4 Tensor Core GPU attached to the Dataflow worker VM, which is also visible as a Compute VM instance running our job. Dataflow will automatically install required NVIDIA drivers that support CUDA11.
The bert_squad2_qa_gpu.py file is almost the same as the bert_squad2_qa_cpu.py file. This means that with very little to no changes we can have our jobs running using NVIDIA GPUs. In our examples, we have a couple of additional GPU setups such as setting the memory growth with the code below.
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
Inference with NVIDIA optimized libraries
NVIDIA TensorRT optimizes Deep Learning models for inference and provides low latency and high throughput (for more information). Here, we use the NVIDIA TensorRT optimization to BERT model and use it to answer questions on a Dataflow pipeline with GPU at the speed of light. Users could follow the TensorRT demo BERT github repository.
We also use Polygraphy, which is a high-level python API for TensorRT to load the TensorRT engine file and run inference. In Dataflow code, the TensorRT model is encapsulated with a shared utility class, allowing all threads from a Dataflow worker process to make use of it.
Comparing CPU and GPU runs
In Table 10, we provided total run times and resources used for sample runs. The final cost for a Dataflow job is a linear combination of total vCPU time, total memory time, and total hard disk usage. For the GPU case, there is a GPU component as well.
| Framework | Machine | Workers Count | Total execution time | Total vCPU time | Total memory time | Total HDD PD time | TCO Improvement |
| TF-CPU | n1-standard-8 | 2 | 2:46:00 | 43.5 | 163.13 | 1359.4 | 1x |
| TF-GPU | N1-standard-4 + T4 | 1 | 0:35:51 | 2.25 | 8.44 | 140.64 | 9.2x |
| TensorRT | N1-standard-4 + T4 | 1 | 0:09:51 | 0.53 | 1.99 | 33.09 | 38x |
Table. Total run time and resource usage for sample TF-CPU, TF-GPU, and TensorRT runs.
Note that the table preceding is compiled based on a run and the exact number might slightly fluctuate but according to our experiments the ratios did not change much.
The total savings including the cost and run-time savings is more than 10x when accelerating our model with NVIDIA GPUs (TF-GPU) compared to using CPUs (TF-CPU). This means that when we use NVIDIA GPUs for inference on this task, we can have faster run times and lower costs compared to running your model using only CPUs.
With NVIDIA optimized inference libraries such as TensorRT, the user could run more complex and bigger models on GPU in Dataflow. TensorRT further accelerates the same job 3.6x faster compared to running it with TF-GPU, which yields 4.2x cost saving. Compare TensorRT with TF-CPU, we get 17x less execution time that provides around 38x less bill.
Summary
In this post, we compared TF-CPU, TF-GPU, and TensorRT inference performance for the question answering task running on Google Cloud Dataflow. Dataflow users can get great benefits by leveraging GPU workers and NVIDIA optimized libraries.
Accelerating deep learning model inference with NVIDIA GPUs and NVIDIA software is super easy. By adding or changing a couple of lines, we can run models using TF-GPU or TensorRT. We provided scripts and source files here and here for reference.
Acknowledgments
We would like to thank Shan Kulandaivel, Valentyn Tymofieiev, and Reza Rokni from the Google Cloud Dataflow team, and Jill Milton and Fraser Gardiner from NVIDIA for their support and invaluable feedback.
