Compression can improve performance in a variety of use cases such as DL workloads, databases, and general HPC. On the GPU, compression can accelerate inter-GPU communications for collaborative workflows. It can increase the size of datasets that a single GPU can handle by compressing data before it’s stored to global memory. It can also accelerate the data link between the CPU and GPU.
For any of these workflows to be beneficial, compression and decompression must be fast and operate at a high enough compression ratio on a given dataset to be useful. However, compression ratios and throughputs of different algorithms vary widely from dataset to dataset. It can be difficult to select the best one without a lot of specialized knowledge about the algorithms and data statistics.
The NVIDIA nvCOMP library enables you to incorporate high-performance GPU compression and decompression in your applications. The library provides a set of unified APIs that allow you to quickly swap compression formats to achieve best performance on your datasets with minimal changes to code.
With nvCOMP, you can quickly and easily experiment with different algorithms to find the one with the best performance for your use case. In recent releases, we’ve updated nvCOMP to further improve and unify the interfaces. As of the newly released version 2.2, we provide an easy-to-use, high-level C++ API and a versatile low-level batch C API. In this post, we cover both interfaces in detail. You also learn how to use them effectively and when you should choose one over the other.
High-level API
The high-level API is easier to use and abstracts the work of exposing parallelism to the GPU. It is most useful when you have to compress a contiguous buffer into a contiguous, compressed buffer. This works well, for example, when compressing a buffer before sending it over a network or saving it to disk.
The following examples use the high throughput GDeflate compression format. GDeflate is deflate-like and can be mapped efficiently to data parallel architectures, such as GPUs. It is a good starting point if you that don’t have constraints on the compression format to use.
The high-level interface is a C++ API based on the nvcompManagerBase class hierarchy. Each derived Manager class is declared in its associated header in nvcomp/include. For example, the GDeflateManager used in this post is declared in nvcomp/include/gdeflate.hpp.
To get started, construct the desired Manager class. Each Manager constructor has a unique set of arguments; however, a few arguments are generally shared. All subclasses allow construction with a specified stream ID to use for all kernels and memory transfers. You can also specify the device ID to use. If you don’t specify values for these two arguments, the default stream and device are used.
Another common input is the uncompressed chunk size. This is used during compression to split the buffer into independent chunks for processing. Larger chunk sizes typically lead to higher compression ratios at the expense of less parallelism exposed to the GPU. A good starting chunk size is 64 KB, but feel free to experiment with these values to explore the associated tradeoffs for your datasets.
The Manager classes are also constructed with format-specific arguments. You can check the associated header in nvcomp/include for a description of the arguments to the Manager class constructor and to see how to construct the Manager object for your chosen format.
const size_t uncomp_chunk_size = 64 * 1024;
cudaStream_t stream;
cudaStreamCreate(&stream));
const int gdeflate_algorithm = 0; // Use standard GDeflate
const int device_id = 0; // Use the default device
GdeflateManager gdeflate_manager{chunk_size, gdeflate_algorithm, stream, device_id};
nvcompManager requires a temporary scratch workspace to do compression and decompression. This required scratch space is of fixed size based on the particular compression format arguments and the maximum occupancy of the compression and decompression kernels. If it makes sense for your use case, you can provide a scratch buffer to the nvcompManager object after construction, using set_scratch_buffer.
size_t scratch_buffer_size = gdeflate_manager.get_required_scratch_buffer_size(); uint8_t* scratch_buffer; cudaMalloc(&scratch_buffer, scratch_buffer_size); gdeflate_manager.set_scratch_buffer(scratch_buffer);
Manually setting the scratch buffer may be desirable to control the memory allocation scheme used for this allocation. If you’re OK with the default, we suggest skipping this step and enabling the nvcompManager object to handle the allocation.
This buffer is reused for all compression and decompression operations that nvcompManager performs. If the nvcompManager object allocates the scratch buffer, it is freed when the object is destroyed.
Compression
Now you’re ready to compress a buffer. First, configure the compression using the configure_compression API. This asynchronous operation returns a CompressionConfig object.
The configuration step only requires the size of the input-uncompressed buffer. You must allocate a GPU-accessible memory buffer of at least this size to serve as the result buffer for the compression routine. With this information, compression can be performed, as shown in the following code example:
CompressionConfig comp_config = gdeflate_manager.configure_compression(input_buffer_len); uint8_t* comp_buffer; cudaMallocAsync(&comp_buffer, comp_config.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer, comp_buffer, comp_config);
You can also queue up additional compressions on the GPU.
uint8_t* comp_buffer1, comp_buffer2; CompressionConfig comp_config1 = gdeflate_manager.configure_compression(input_buffer_len1); cudaMallocAsync(&comp_buffer1, comp_config1.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer1, comp_buffer1, comp_config1); CompressionConfig comp_config2 = gdeflate_manager.configure_compression(input_buffer_len2); cudaMallocAsync(&comp_buffer2, comp_config2.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer2, comp_buffer2, comp_config2); cudaStreamSynchronize(stream);
Decompression
The buffer that results from high-level interface compression includes a header before the compressed data (Figure 1). This header includes information about how the buffer was compressed, so that you can construct an nvcompManager object from a compressed buffer without knowing how it was compressed. This enables you to decompress a buffer without knowing how it was compressed.

To do this, use the create_manager API declared in nvcompManagerFactory.hpp. This synchronous API takes as input the compressed buffer along with optional stream and device IDs.
auto decomp_nvcomp_manager = create_manager(comp_buffer, stream);
If you already have the information about how the buffer was compressed, you can construct a new manager using that configuration as described earlier. You can also reuse the same nvcompManager object that was used for compression to perform decompression. These approaches have the advantage that they don’t require synchronizing the stream.
Given an nvcompManager object and a compressed buffer, decompression is performed similarly to compression with a couple of minor differences. For one, there are two possible ways to do the decompression configuration. If you have the CompressionConfig object used for the compression, you can configure the decompression completely asynchronously.
DecompressionConfig decomp_config = gdeflate_manager->configure_decompression(comp_config);
One example use case for this API is in the training of large neural networks. The size of the neural network or the size of the training set that you can use is limited based on the memory capacity of the GPU. Using compression, you can effectively increase this capacity without having to offload data to the CPU or use multiple GPUs.
Specifically, backpropagation-based training involves computing activation maps during the forward pass and then reusing them in the computation of the backward pass. These activation maps are large and relatively sparse, making them good fits for compression. Use the gdeflate_manager to compress the maps and hold in memory the compressed buffers and the CompressionConfig objects from each layer of the network. This enables fully asynchronous backpropagation, including decompression.
You can also configure the decompression using the compressed buffer if you don’t have the CompressionConfig object that was used. This is a synchronous operation that must perform a cudaMemcpyAsync operation from the device. All synchronization is on the stream specified in the nvcompManager constructor and is not device-wide.
DecompressionConfig decomp_config = gdeflate_manager->configure_decompression(comp_buffer);
As with compression, you can queue many decompression items at one time before synchronizing the stream.
uint8_t* res_decomp_buffer1, res_decomp_buffer2; DecompressionConfig decomp_config1 = gdeflate_manager->configure_decompression(comp_config1); DecompressionConfig decomp_config2 = gdeflate_manager->configure_decompression(comp_config2); cudaMallocAsync(&res_decomp_buffer1, decomp_config1.decomp_data_size, stream); cudaMallocAsync(&res_decomp_buffer2, decomp_config2.decomp_data_size, stream); gdeflate_manager->decompress(res_decomp_buffer1, comp_buffer1, decomp_config1); gdeflate_manager->decompress(res_decomp_buffer2, comp_buffer2, decomp_config2); cudaStreamSynchronize(stream));
Finally, there are two types of error checking in the high-level API: std::runtime_error exceptions and checking the nvcompStatus_t value.
If any CUDA APIs fail, these raise std::runtime_error exceptions. You can catch these in your application or leave them unhandled, in which case your application fails with a descriptive error message of what went wrong. This can happen if, for example, the output buffer that you provided was of insufficient size or wasn’t accessible on the GPU.
The second form of error-checking is to check the nvcompStatus_t value in the CompressionConfig or DecompressionConfig object. This status is set during the associated kernel call. Corrupt input buffers and other errors trigger it.
Low-level API
The low-level API provides a C API for more advanced workflows. The low-level API simultaneously compresses and decompresses batches of independent chunks that you provided. It’s up to you to chunk the data and to provide a sufficient number of chunks to exploit the GPU’s parallel processing capabilities.
This is the most efficient way to process the data if you have many independent, discontiguous buffers. The low-level API avoids the workload of packing the resulting compressed chunks into a single contiguous-compressed buffer. It also avoids the compression ratio overhead associated with saving information about how the buffer was compressed as in the high-level API.
This workflow fits well with database applications, for example, where you tend to have many independent columns to compress or decompress. This API is used in RAPIDS and in the NVIDIA Spark implementation.
Compression
For compression in the low-level API, you must allocate a temporary scratch buffer. The temporary buffer is similar to that described in the high-level API. However, the buffer size is dependent on the size of the input buffer so it must be redefined and possibly reallocated with each new set of user inputs.
size_t temp_bytes; nvcompBatchedGdeflateCompressGetTempSize(batch_size, chunk_size, nvcompBatchedGdeflateDefaultOpts, &temp_bytes); void* device_temp_ptr; cudaMalloc(&device_temp_ptr, temp_bytes);
Next, the maximum size of a compressed chunk in the batch should be computed. This allows you to allocate a collection of result buffers. In the following example, batch_size is the number of chunks to process. The device array of result pointers is constructed in pinned host memory before copying to the device.
size_t max_out_bytes;
nvcompBatchedGdeflateCompressGetMaxOutputChunkSize(chunk_size, nvcompBatchedGdeflateDefaultOpts, &max_out_bytes);
// Allocate output space on the device
void ** host_compressed_ptrs;
cudaMallocHost((void**)&host_compressed_ptrs, sizeof(size_t) * batch_size);
for(size_t ix_chunk = 0; ix_chunk < batch_size; ++ix_chunk) {
cudaMalloc(&host_compressed_ptrs[ix_chunk], max_out_bytes);
}
void** device_compressed_ptrs;
cudaMalloc(&device_compressed_ptrs, sizeof(size_t) * batch_size);
cudaMemcpy(
device_compressed_ptrs, host_compressed_ptrs,
sizeof(size_t) * batch_size,cudaMemcpyHostToDevice);
With all these inputs computed, you can now do compression asynchronously as shown.
nvcompStatus_t comp_res = nvcompBatchedGdeflateCompressAsync(
device_uncompressed_ptrs,
device_uncompressed_bytes,
chunk_size,
batch_size,
device_temp_ptr,
temp_bytes,
device_compressed_ptrs,
device_compressed_bytes,
nvcompBatchedGdeflateDefaultOpts,
Decompression
To begin work towards decompression, pre-compute the decompressed sizes based on the compressed buffer. If you already have this information, skip this step.
nvcompBatchedGdeflateGetDecompressSizeAsync(
device_compressed_ptrs,
device_compressed_bytes,
device_uncompressed_bytes,
batch_size,
stream);
Similar to compression, you must also compute the required temporary size and allocate a temporary scratch buffer.
size_t decomp_temp_bytes; nvcompBatchedGdeflateDecompressGetTempSize(batch_size, chunk_size, &decomp_temp_bytes); void * device_decomp_temp; cudaMalloc(&device_decomp_temp, decomp_temp_bytes);
Finally, you can do the asynchronous decompression.
nvcompStatus_t decomp_res = nvcompBatchedGdeflateDecompressAsync(
device_compressed_ptrs,
device_compressed_bytes,
device_uncompressed_bytes,
device_actual_uncompressed_bytes,
batch_size,
device_decomp_temp,
decomp_temp_bytes,
device_uncompressed_ptrs,
device_statuses,
stream);
Benchmarking
nvCOMP provides a set of benchmarks for each of the formats in the low-level and high-level format. Figure 2 compares the performance of high-level and low-level on a few different datasets, with large contiguous buffers. The results were collected using the A100 GPU.
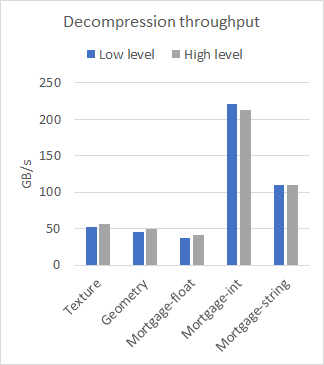
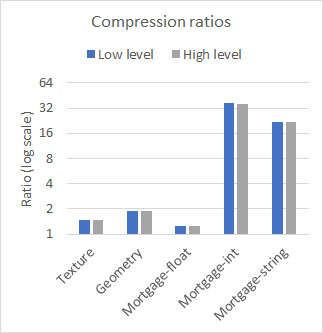
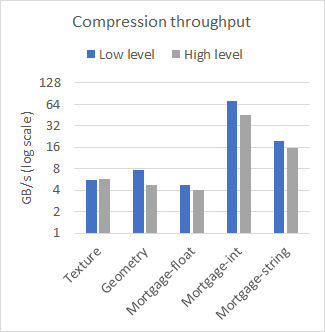
As you can see from the results, the difference in performance between the low– and high-level APIs is negligible when working with large contiguous buffers. The choice of which to use then comes down to your use case. Use the low-level API if you have many small buffers or to avoid the memory footprint associated with the high-level API.
Figure 3 shows performance across different buffer sizes in log-scale. To produce these results, the mortgage-int dataset presented as part of Figure 2 was split into many batches of batchSize as shown. The file is over 314 MB. For the 1 MB batch size, 315 compression and decompression operations are performed. At a 400 MB batch size, a single compression and decompression operation is performed.
Batching the data in this way doesn’t affect the low-level batch API.
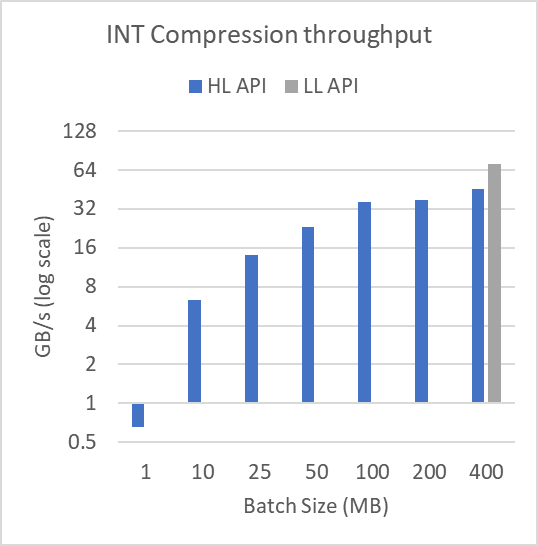
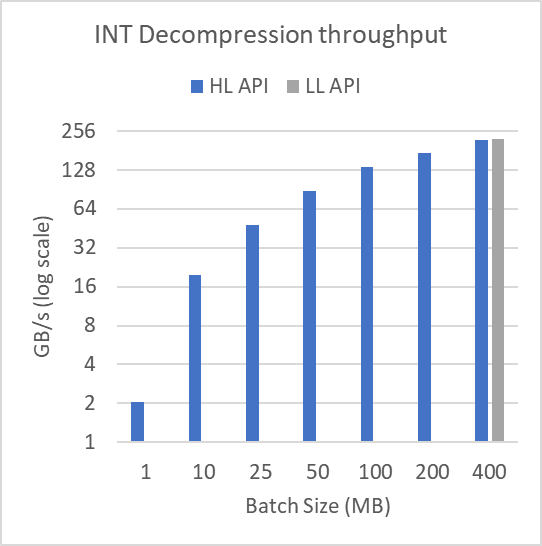
As demonstrated, the performance of the high-level interface degrades heavily for small batch sizes. This shows the utility of using the low-level batch API when compressing or decompressing many smaller buffers. The low-level batch API can do the operations using fewer, higher-occupancy kernels, while the high-level API requires many small kernel launches with associated tail effects and occupancy concerns.
We include benchmark applications with the library so that you can try out different compression formats and see which works best on your data. The provided benchmarks are benchmark_hlif and benchmark_<format>_chunked. For more information, see the nvCOMP README.
Summary
Now you’ve learned how to use the high-level nvCOMP API for easy compression and decompression. You’ve learned when it may be better to use the low-level API as well as how to use it.
For more information, see the latest version of the NVIDIA/nvcomp GitHub repo. For fully worked, compilable examples that you can adapt to your use cases, see the lowlevel_c_quickstart.md and highlevel_cpp_quickstart.md walkthroughs along with the associated example files.
If you have any questions, please comment below. You can also join us at the Connect with the Experts: nvCOMP: GPU Compression/Decompression GTC session on Monday, March 21 at 10AM PT.
