
高性能计算(HPC)为模拟和建模、医疗健康、生命科学、工业和工程等领域的应用提供支持。在现代数据中心,HPC 与 AI 协同工作,以变革性的新方式利用数据。
新一代 HPC 应用程序对性能和吞吐量的需求催生了一个能够处理多种工作负载并在 CPU 和 GPU 之间实现紧密协作的加速计算平台。NVIDIA Grace CPU 和 NVIDIA Hopper GPU 构成了用于 HPC 开发的行业领先硬件生态系统。
NVIDIA 提供了一系列工具、库和编译器,帮助开发者充分利用 NVIDIA Grace 和 NVIDIA Grace Hopper 架构的潜力。这些资源支持创新,并助力应用程序最大化地利用加速计算的优势。此基础软件堆栈不仅提供了 GPU 加速的方法,还包括在基于 NVIDIA Grace 的系统上移植和优化应用程序的策略。了解更多关于 NVIDIA Grace 编译器、工具、库等信息,请访问 Grace 开发者产品页面。
NVIDIA HPC SDK 23.11
NVIDIA GPU 在硬件方面的新进展,NVIDIA Grace Hopper 系统能够显著改变开发者的 GPU 编程方式。最值得注意的是,CPU 和 GPU 显存之间的双向、高带宽和缓存一致性连接,意味着用户可以在使用单个统一地址空间的同时,为两个处理器开发应用程序。
每个处理器都保留自己的物理内存,该内存的带宽、延迟和容量特性与最适合每个处理器的工作负载相匹配。为现有的独立显存 GPU 系统编写的代码可以继续高性能运行,而无需针对新的 Grace Hopper 架构进行修改。
所有应用程序线程(GPU 或 CPU)都可以直接访问应用程序的系统分配显存,从而无需在处理器之间复制数据。这种直接读取或写入整个应用程序显存地址空间的新功能显著提高了程序员使用基于 GPU 或 CPU 的所有编程模型构建程序的工作效率,包括 NVIDIA CUDA:CUDA C++、CUDA Fortran、ISO C++ 中的标准并行度、ISO Fortran、OpenACC、OpenMP 等。
NVIDIA HPC SDK 23.11 引入了新的统一内存编程支持,这使得原本受限于主机到设备或设备到主机传输的工作负载能够实现高达 7 倍的速度提升,得益于 Grace Hopper 系统中的芯片到芯片 (C2C) 互连技术。此外,由于系统会自动处理数据的位置和迁移,应用程序开发过程得以大幅简化。
阅读《借助 NVIDIA Grace Hopper 超级芯片简化 HPC 的 GPU 编程》,深入了解 NVIDIA 如何利用HPC 编译器和这些新的硬件功能,通过 ISO C++、ISO Fortran、OpenACC 和 CUDA Fortran 来简化 GPU 编程。
立即免费开始使用 NVIDIA HPC SDK,下载版本 23.11。
NVIDIA 性能库
NVIDIA 现已发展成为一家全栈企业平台提供商,不仅提供 GPU,还提供 CPU 和 DPUs。除了现有以 GPU 为中心的解决方案外,NVIDIA 的数学软件产品现在还支持仅依赖 CPU 的工作负载。
NVIDIA 性能库 (NVPL) 是针对 Arm 64 位架构优化的基本数学库的集合。许多 HPC 应用程序都依赖于数学 API (例如 BLAS 和 LAPACK),这对其性能至关重要。NVPL 数学库是这些标准化数学 API 的直接替代品。
它们针对 NVIDIA Grace CPU 进行了优化。在基于 Grace 的平台上移植或构建的应用程序可以充分利用高性能和高效率的架构。NVPL 的一个主要目标是为开发者和系统管理员提供非常流畅的体验,将现有 HPC 应用程序移植和部署到 Grace 平台无需更改源代码,以在使用基于 CPU 的标准化数学库时实现更高的性能。
NVPL 测试版现已推出,其中包括 BLAS、LAPACK、FFT、RAND 和 SPARSE,可在 NVIDIA Grace CPU 上加速应用程序。
了解详情并下载 NVPL 测试版。
NVIDIA CUDA Direct 稀疏求解器
我们正在将一个新的标准数学库引入到 NVIDIA GPU 加速库 中。NVIDIA CUDA Direct Sparse Solvers 库(NVIDIA cuDSS)针对求解具有非常稀疏矩阵的线性系统进行了优化。虽然 cuDSS 的第一版支持在单个 GPU 上执行,但即将发布的版本将添加对多 GPU 和多节点的支持。
霍尼韦尔是 cuDSS 的早期采用者之一,目前正处于 UniSim Design 流程模拟产品性能基准测试的最后阶段。
cuDNN 预览版即将推出。点击此处了解更多关于 CUDA 数学库的信息:CUDA-X GPU 加速库。
NVIDIA cuTENSOR 2.0
NVIDIA cuTENSOR 2.0 是一个高性能且灵活的库,专为加速 HPC 和 AI 交叉路口的应用程序而设计。在这个主要版本更新中,cuTENSOR 2.0 引入了新功能和性能改进,特别是针对任意高维张量的优化。为了便于新优化能够轻松地广泛应用于所有张量运算,并同时保持高性能,cuTENSOR 2.0 的 API 进行了全面的重构,着重提升了灵活性和可扩展性。

基于计划的多阶段 API 通过一组共享 API 扩展到所有操作。新 API 可以将不透明堆分配的数据结构作为输入,以传递为该执行定义的任何操作特定的问题描述符。
cuTENSOR 2.0 还增加了对即时 (JIT) 内核的支持。
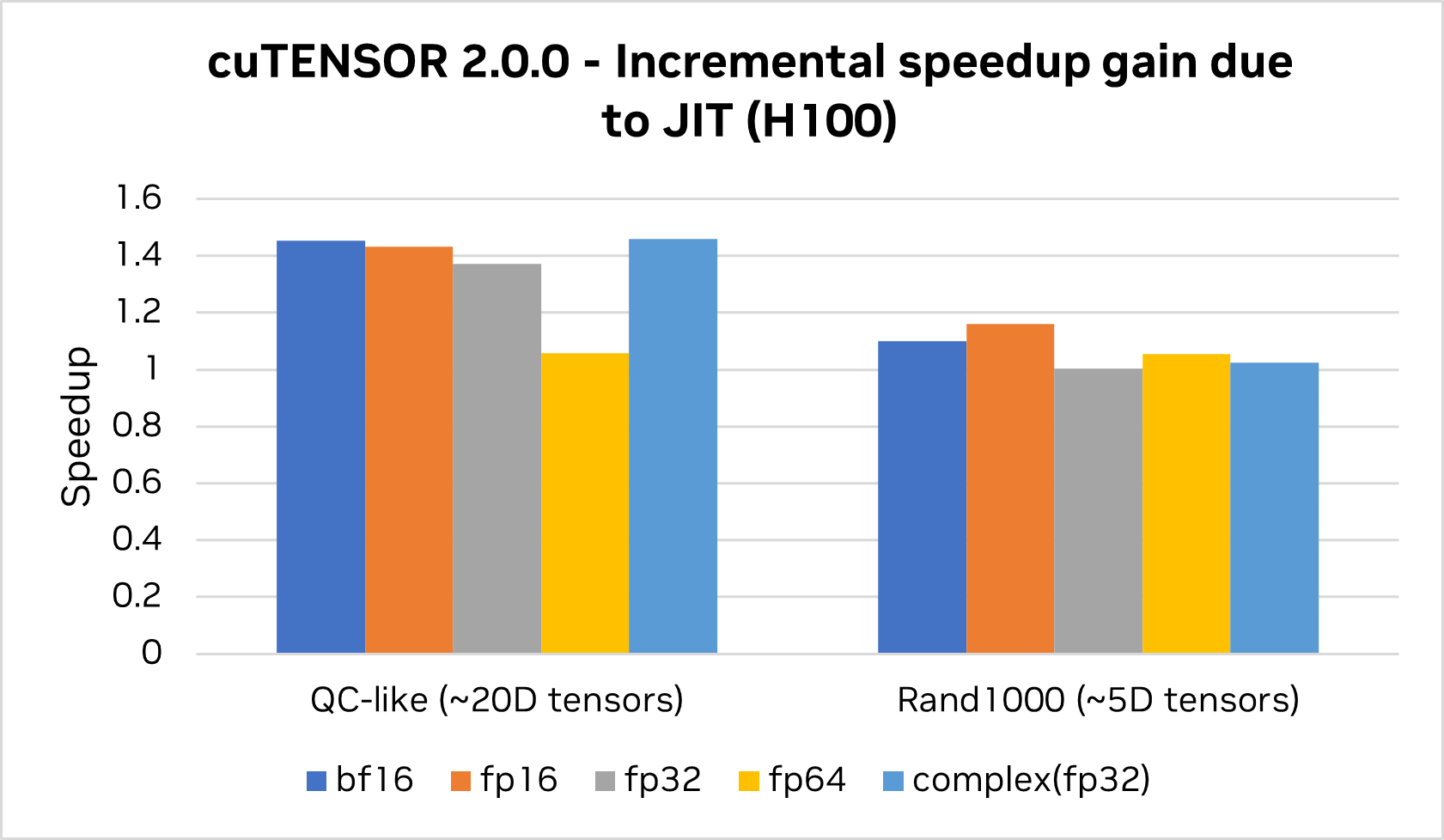
通过在运行时针对目标配置调整正确的配置和优化旋钮,使用 JIT 内核有助于实现无与伦比的性能,同时支持大量高维张量,而这些张量无法通过库可以提供的通用预编译内核实现。
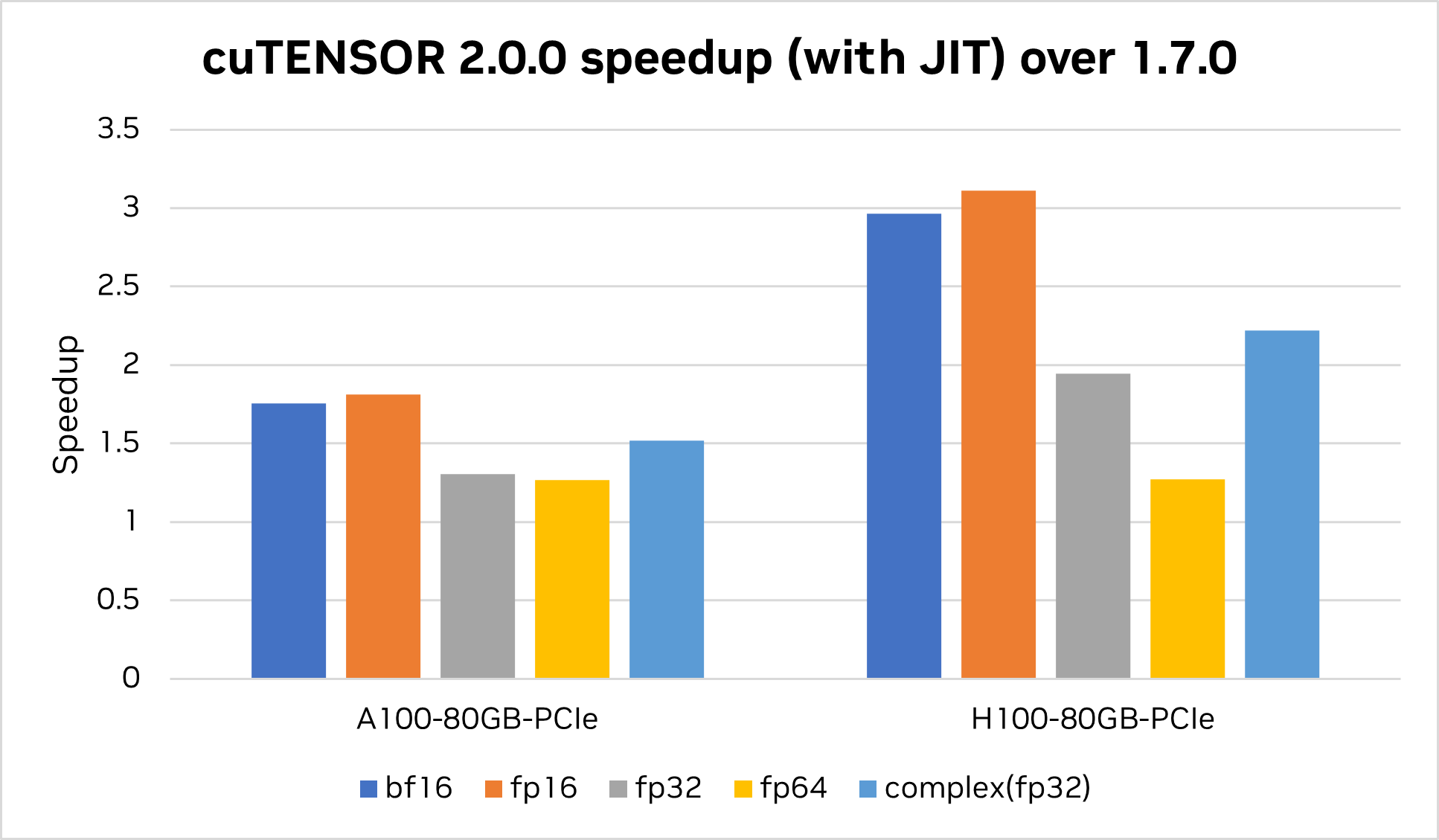
cuTENSOR 2.0 即将推出。
利用 NVIDIA Nsight Systems 2023.4 对 Grace CPU 进行性能调优
基于 Grace 的平台上的应用程序受益于在 CPU 核心上调整指令执行,以及优化 CPU 与系统中其他硬件单元的交互。在将应用程序移植到 Grace 时,深入了解硬件级别的功能将帮助您为新平台配置软件。
NVIDIA Nsight Systems 是一个系统级性能分析工具,它能够收集硬件和 API 的指标,并将这些指标在统一的时间轴上进行关联。对于 Grace CPU 的性能调优,Nsight Systems 通过采样指令指针和回溯来可视化 CPU 代码的高负载区域,以及 CPU 如何利用整个系统的资源。此外,Nsight Systems 还能捕获上下文切换,为所有 Grace CPU 核心构建利用率图表。
Grace CPU 核心事件速率(如 CPU 周期和指令停用)显示了 Grace 核心处理工作的方式。此外,回溯样本的摘要视图可帮助您快速确定哪些指令指针引起了热点。
Grace CPU Uncore 事件速率现已在 Nsight Systems 2023.4 中推出,可用于监控 CPU 核心以外的活动,例如 NVLink-C2C 和 PCIe 活动。Uncore 指标能够展示插槽间的活动如何支持 CPU 核心的工作,帮助您找到改善 Grace CPU 与系统其他部分集成的方法。
Nsight Systems 2023.4 中的 Grace CPU uncore 和 core 事件采样可帮助您找到在 Grace 上运行的代码的最佳优化。有关 Grace CPU 性能调整的更多信息,以及结合优化 CUDA 代码的提示,请观看以下视频。
了解详情并开始使用 Nsight Systems 2023.4。Nsight Systems 也可用于 HPC SDK 和 CUDA 工具包。
HPC 加速计算
NVIDIA 提供了一个由工具、库和编译器组成的生态系统,用于在 NVIDIA Grace 和 Hopper 架构上加速计算。HPC 软件堆栈是 NVIDIA 数据中心芯片上研究和科学研究的基础。
深入了解加速计算领域的 开发者论坛。



