
深度学习推荐系统通常使用大型嵌入表。很难将它们放入 GPU 内存中。
这篇文章向你展示了如何结合使用模型并行和数据并行训练范例来解决这个记忆问题,从而更快地训练大型深度学习推荐系统。我分享了我的团队在 TensorFlow 2 中高效培训 1130 亿参数推荐系统所采取的步骤,该模型的所有嵌入的总大小为 421 GiB 。
通过在 GPU 和 CPU 之间拆分模型和嵌入,我的团队实现了 43 倍的加速。然而,将嵌入分布到多个 GPU 上,带来了令人难以置信的 672 倍的加速。这种多 GPU 方法实现了显著的加速,使您能够在几分钟内而不是几天内训练大型推荐系统。
您可以使用 NVIDIA 深度学习示例 GitHub 存储库 中提供的代码自己复制这些结果。
嵌入层的模型并行训练
在数据并行训练中,每个 GPU 存储模型的相同副本,但在不同的数据上训练。这对于许多深度学习应用程序来说都很方便,因为它易于实现,并且通信开销相对较低。然而,这种模式要求神经网络的权重适合单个设备。
如果模型大小大于设备内存,一种方法是将模型分成子部分,并在不同的 GPU 上训练每个子部分。这被称为模型并行训练。
表的每一行对应于要映射到密集表示的输入变量的值。表中的每一列表示输出空间的不同维度,表示所有向量中一个值的切片。因为一个典型的深度学习推荐程序会吸收多个分类特征,所以它需要多个嵌入表。
对于具有多个大型嵌入的推荐程序,有三种实现模型并行性的方法:
- Table-wise split ——每个嵌入表完全放在一个设备上;每个设备只包含所有嵌入的一个子集。(图 1 )
- Column-wise split –每个 GPU 包含每个嵌入表中的一个子集列。(图 2 )
- Row-wise split –每个 GPU 保存每个嵌入表中的行子集。
由于负载平衡问题,行分割比其他两个选项更难实现。在本文中,我将重点介绍表拆分和列拆分。混合和匹配多种方法是一个可行的选择,但为了简单起见,我不会在本文中集中讨论这一点。
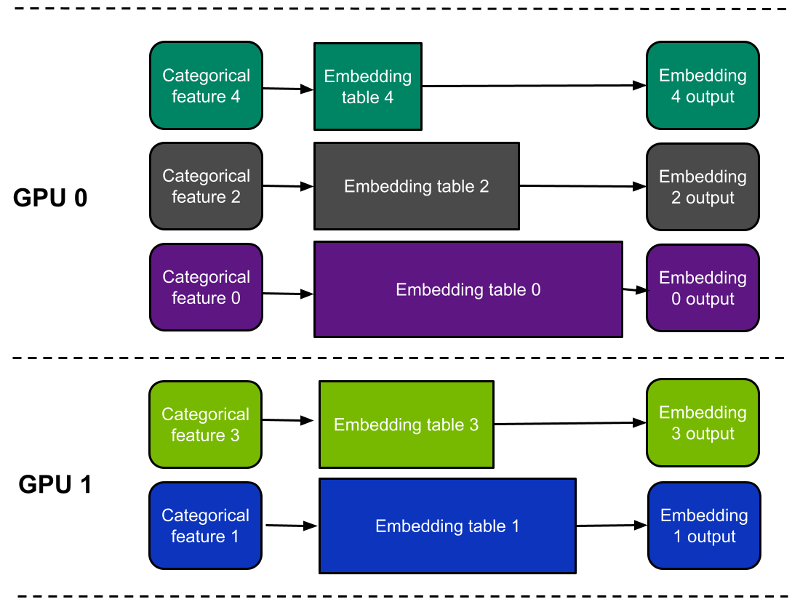
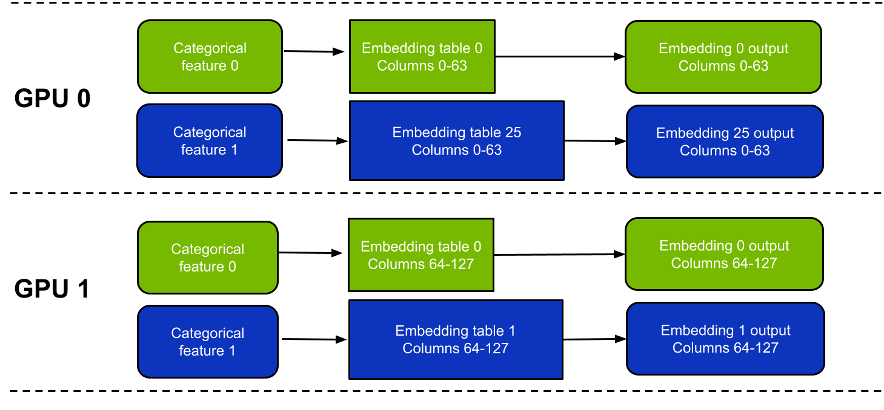
这些方法之间有一些关键区别(表 1 )。简言之,按表拆分模式更易于使用,而且可能更快,具体取决于具体的工作负载。
一个缺点是它不支持嵌入跨越多个 GPU 的表。相比之下,按列拆分模式支持嵌入跨多个 GPU 的表,但速度可能会稍慢,尤其是对于窄表。
| Table-wise split | Column-wise split | |
| Embedding lookup efficiency | Good. Embedding lookup efficiency is the same as performing the same lookup on a single GPU. | Less efficient from a hardware perspective. Lower than for table-wise split as it uses more narrow tables. Ideally, the width of each slice should be at least 4 columns for satisfactory performance. |
| Largest table supported (including optimizer variables). | Maximum size of each table is limited by the memory of a single GPU. | Maximum size of each table is limited to the combined memories of all the GPUs. A table with N columns can only be split across N GPUs. However, this is only a concern for tables with extremely high row counts (more than 1 billion rows). |
| Load balancing | Needs careful examination for best performance. Each GPU should hold roughly the same amount of memory and perform roughly the same number of lookup operations. | Perfectly balanced by design. |
表 1 。表拆分和列拆分模式之间的比较。
高效训练推荐系统的混合并行方法
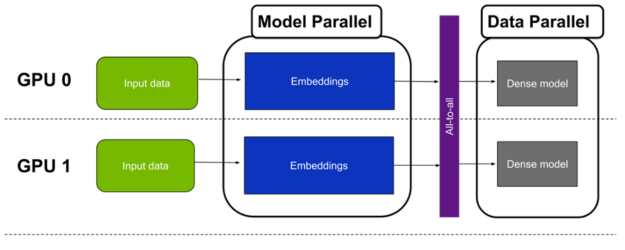
典型的推荐程序在嵌入后运行算术密集型层,如线性或点积。处理模型这一部分的一种幼稚方法是将嵌入查找的结果收集到单个 GPU 上,并在此 GPU 上运行这些密集层。然而,这是非常低效的,因为在这段时间内没有使用用于保存嵌入的另一个 GPU 。
更好的方法是使用所有 GPU 通过数据并行运行密集层。这可以通过按批量大小拆分嵌入查找的结果来实现。也就是说,对于 N 和八 GPU 的全局批量,每个 GPU 只处理 N / 8 个训练样本。实际上,这意味着密集层以数据并行模式运行。
由于这种方法结合了嵌入的模型并行性和多层感知器( MLP )的数据并行性,因此被称为混合并行训练(图 3 )。
Horovod all-to-all
从模型并行到数据并行范式需要一个多 GPU 集体通信操作:全部对全部。
All to All 是一种灵活的集体通信原语,可在每对 GPU 之间交换数据。这是必需的,因为在嵌入查找阶段结束时,每个 GPU 都保存所有样本的查找结果。但是,仅适用于表的子集(用于按表拆分)或列的子集(用于按列拆分)。
由于 all-to-all 操作会在 GPU 之间洗牌数据,因此需要注意的是,每个 GPU 都会保存所有表的所有列的嵌入查找结果,但只保存样本子集的嵌入查找结果。例如,对于一个 8 GPU 场景,本地批量大小毕竟是之前的 8 倍。
通信由 Horovod 库的 hvd.alltoall 函数处理。在引擎盖下,霍洛伍德称 NCCL 实施 为了获得最佳性能。如果你的系统上有 NVLink ,它也会利用它。
TensorFlow 2 中的混合并行训练示例
在本节中,我将描述一种用于 TensorFlow 2 中训练的 1130 亿参数推荐系统的混合并行训练方法。完整的源代码可以在 NVIDIA 深度学习示例库 中找到。
深度学习推荐模型的体系结构
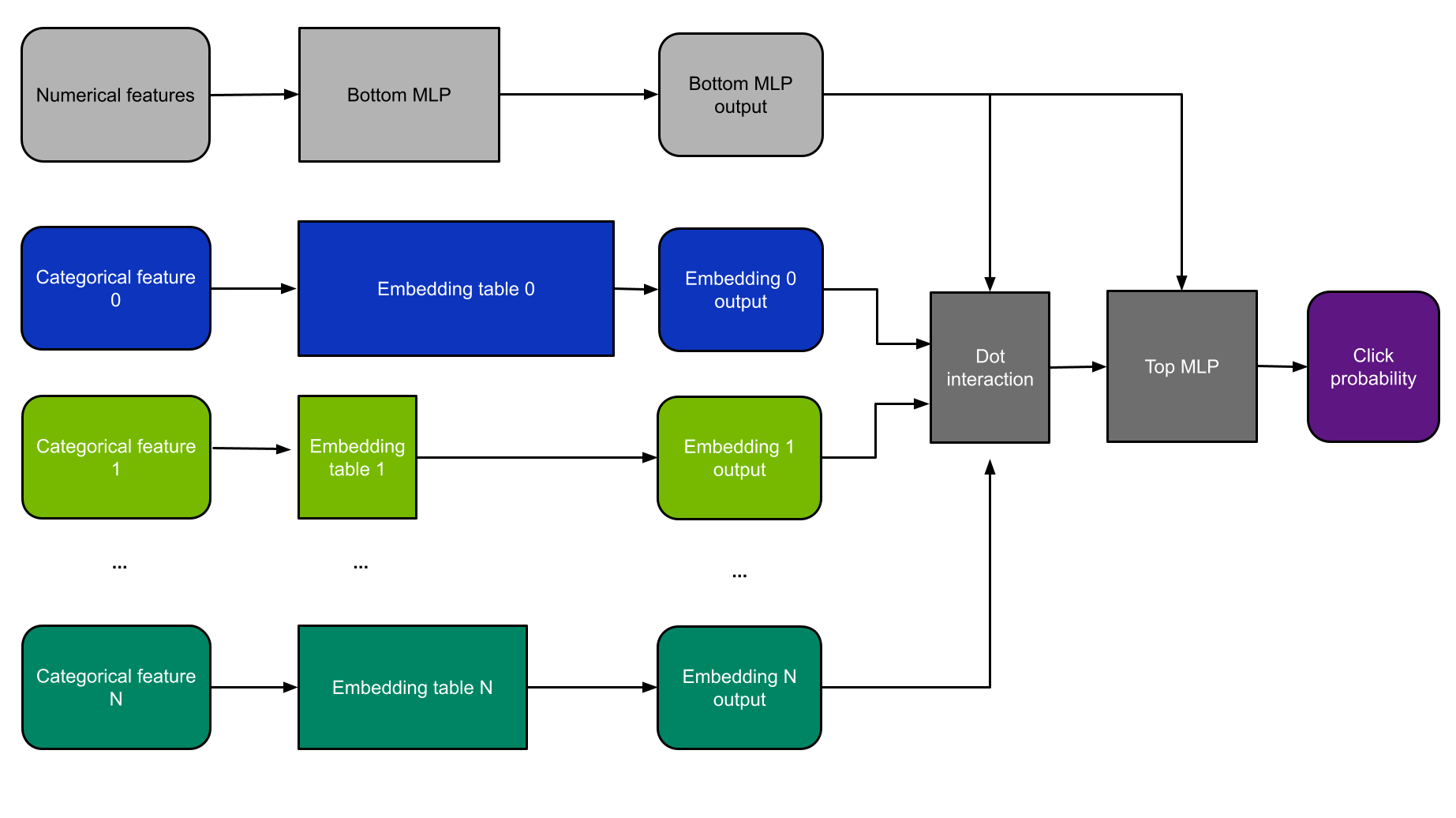
对于这个例子,我使用 DLRM 体系结构(图 4 )。 DLRM 是研究论文 面向个性化和推荐系统的深度学习推荐模型 中首次介绍的一类推荐模型。我之所以选择它,是因为 MLPerf 基准测试使用了更小版本的 DLRM ,因此,它是演示推荐系统性能的当前行业标准。
DLRM 同时使用分类和数字功能。分类特征被输入到嵌入层中,而数字特征则由一个小的 MLP 子网络处理。
然后将这些层的结果输入点交互层和另一个 MLP 。然后使用二元交叉熵损失函数通过反向传播对模型进行训练,并根据随机梯度下降( SGD )方法更新权重。
修改以支持宽深度模型
虽然我选择在本例中使用 DLRM 体系结构,但也可以支持相关模型(如 Wide & Deep )。这需要进行以下修改:
- 添加 wide & Deep 的“ wide ”部分,并在纯数据并行模式下运行它,完全绕过 all to all 。
- 为宽部分添加第二个优化器。
- 在深部,移除底部 MLP ,并将数字特征直接传递到顶部 MLP 。
- 移除点交互层。
同步文件夹
DLRM 可以在由数字和分类特征组成的任何表格数据集上进行训练。在本例中,我使用 Criteo 的 TB 点击日志数据集 ,因为它是最大的公开点击率数据集。
该数据集由 26 个分类变量和 13 个数值变量组成。在未经处理的数据中,独特类别的总数为 8.82 亿,其中 2.92 亿是在最大的特征中发现的。
遵循 MLPerf 推荐基准,对嵌入使用单精度,每个特征的嵌入维度为 128 。这意味着参数总数为 882M × 128 = 1130 亿。所有 26 个表的总大小为 1130 亿× 4 字节/ 230= 421 GiB ,最大表为 139.6 GiB 。因为最大的表不适合单个 GPU ,所以必须使用按列拆分模式将表分片,并将每个表分布到多个 GPU 中。
从理论上讲,您可以只对超过单个 GPU 内存的少数表执行此操作,并对其余的表使用按表拆分。然而,这将不必要地使代码复杂化,而没有任何明显的好处。因此,对所有表使用按列拆分模式。
性能优化
为了提高训练速度,我的团队实施了以下性能优化,如代码所示。这些是可以应用于其他深度学习推荐系统以及其他深度学习框架的通用策略。
自动混合精度
混合精度是计算方法中不同数值精度的组合使用。有关如何启用它的更多信息,请参阅 TensorFlow 核心文档中的 Mixed precision 。与 A100 上默认的 TF32 精度相比,该模型使用混合精度使其速度提高了 23% 。
相同宽度的融合嵌入表
当多个嵌入表具有相同的向量大小时——这是 DLRM 中使用embedding_dim=128的情况——它们可以沿零轴连接。这允许对一个大表执行单个查找,而不是对许多较小的表执行多个查找。
启动一个大内核而不是多个小内核要高效得多。在本例中,将表连接起来可使训练速度提高 39% 。有关更多信息,请参阅 NVIDIA/DeepLearningExamples/blob/master/TensorFlow2/Recommendation/DLRM GitHub 回购协议。
XLA
我的团队使用 TensorFlow 加速线性代数( XLA )编译器来提高性能。对于这个特定的用例,应用 XLA 比不使用它产生 3.36X 的加速。这个值是在打开所有其他优化的情况下实现的: AMP 、串联嵌入等等。
广播数据加载器
在每个 GPU 上运行每个嵌入表的一部分意味着每个 GPU 必须访问每个训练样本的每个特性。在每个过程中分别加载和解析所有这些输入数据效率低下,可能会导致严重的瓶颈。我通过只在第一个 worker 上加载输入数据并通过 NVLink 将其广播给其他 worker 来解决这个问题。这提供了 32% 的加速。
把这一切放在一起
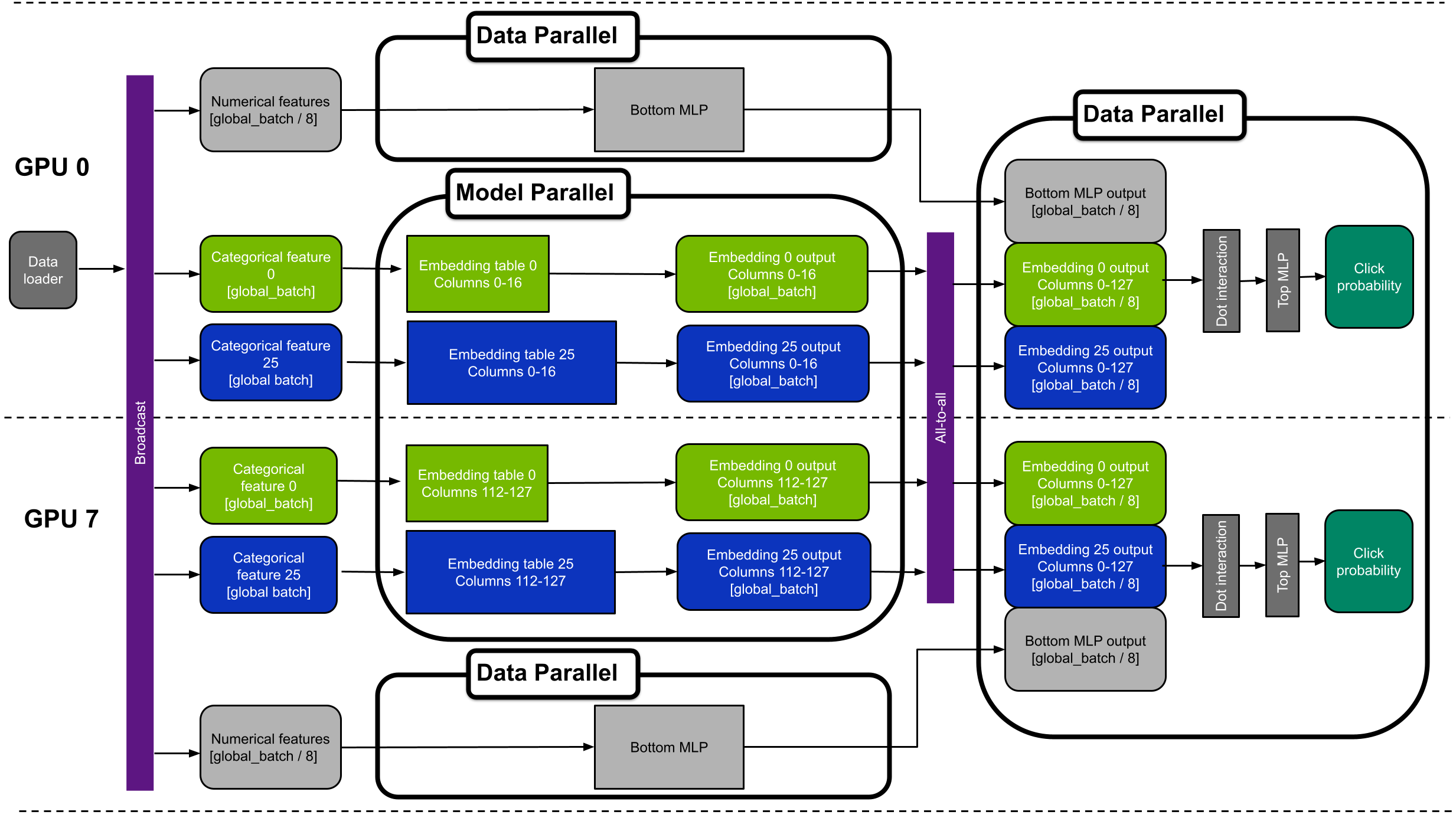
图 5 显示了具有八个 GPU 的混合并行 DLRM 的设备放置示例。该图显示 GPU 0 和 7 。为了简单起见,它只显示分类功能 0 和 25 。
替代方法:将大型嵌入存储在 CPU 上
存储大型嵌入矩阵的一个简单替代方法是将它们放入主机内存中。小型嵌入表和计算密集型层仍然可以放置在 GPU 上,以获得最佳性能。虽然简单得多,但与将所有变量保留在 GPU 上相比,这种方法也较慢。
这有两个根本原因:
- 嵌入查找是一种内存受限的操作。 CPU 内存比 GPU 内存慢得多。双插槽 AMD Epyc 7742 的总内存带宽为 409.6 GB / s ,而单插槽 A100-80GB GPU 的总内存带宽为 2 TB / s ,而 8 个 A100-80GB GPU 的总内存带宽为 16 TB / s 。
- GPU 之间的数据交换速度明显快于 CPU 和 GPU 之间的数据交换速度。这是因为将 CPU 连接到 GPU 之间的 PCIe 链路可能会成为瓶颈。
当使用 CPU 存储嵌入时, CPU 和 GPU 之间的传输必须首先通过提供 31.5 GB / s 带宽的 PCIe 接口。相反,在混合并行范例中,嵌入查找的结果通过 GPU 之间的 NVSwitch 结构进行传输。 DGX A100 采用第二代 NVSwitch 技术,支持每秒 600 GB 的峰值 GPU 到 – GPU 通信。
尽管速度有所放缓,但这种替代方法仍然比仅在 CPU 上运行整个网络快得多。
基准结果
下表显示了训练 113B 参数 DLRM 模型的基准测试结果。它只比较了三种硬件设置: CPU ,一种使用 CPU 内存的单一 GPU 用于最大的嵌入表,以及一种使用完整 DGX A100-80GB 的混合并行方法。
| Hardware | Throughput [samples/second] | Speedup over CPU |
| 2xAMD EPYC 7742 | 17.7k | 1x |
| A100-80GB + 2xAMD EPYC 7742(large embeddings on CPU) | 768k | 43x |
| DGX A100 (8xA100-80GB) (hybrid parallel) | 11.9M | 672x |
比较前两行,你可以看到用一个 A100 GPU 来补充两个 CPU 可以使吞吐量增加 43 倍。之所以会出现这种情况,是因为 GPU 非常适合运行计算密集型线性层和适合其 80-GB 内存的较小嵌入层。
此外,使用八个 GPU 的完整 DGX A100 比在单个 A100 GPU 上训练快 15.5 倍。 DGX A100 使您能够将整个型号安装到 GPU 内存中,并消除了昂贵的设备到主机和主机到设备传输的需要。
总的来说, DGX A100 解决这项任务的速度是双插座 CPU 系统的 672 倍。
结论
在这篇文章中,我介绍了使用混合并行来训练大型推荐系统的想法。测试结果表明, DGX A100 是在 TensorFlow 2 中训练参数超过 1000 亿的推荐系统的极好工具。它在双插槽 CPU 上实现了 672 倍的加速。
高内存带宽和快速的 GPU 到 – GPU 通信使快速培训推荐人成为可能。因此,与仅使用 CPU 服务器相比,您的培训时间更短。这降低了培训成本,同时为从业者提供了更快的实验。




