
假设你刚刚开始一个新的数据科学项目。目标是建立一个预测目标变量 Y 的模型。您已经从利益相关者/数据工程师那里收到了一些数据,进行了彻底的 EDA ,并选择了一些您认为与当前问题相关的变量。然后你终于建立了你的第一个模型。分数可以接受,但你相信你可以做得更好。你是做什么的?
有很多方法可以让你跟进。一种可能是增加所用 machine-learning 模型的复杂性。或者,您可以尝试提出一些更有意义的功能,并继续使用当前的模型(至少目前是这样)。
对于许多项目,企业数据科学家和 Kaggle 等数据科学竞赛的参与者都同意,后者——从数据中识别出更有意义的特征——往往能够以最少的努力最大程度地提高模型的准确性。
你有效地将复杂性从模型转移到了功能上。这些功能不一定非常复杂。但是,理想情况下,我们会发现与目标变量有着强烈而简单的关系的特征。
许多数据科学项目包含一些关于时间流逝的信息。这并不局限于时间序列预测问题。例如,您通常可以在传统的回归或分类任务中找到此类特征。本文研究如何使用日期相关信息创建有意义的特征。我们介绍了三种方法,但首先需要做一些准备。
设置和数据
在本文中,我们主要使用非常知名的 Python 软件包,并依赖于一个相对未知的scikit-lego,这是一个库,其中包含许多扩展scikit-learn’s功能的有用功能。我们按如下方式导入所需的库:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from datetime import date from sklearn.linear_model import LinearRegression from sklearn.preprocessing import FunctionTransformer from sklearn.metrics import mean_absolute_error from sklego.preprocessing import RepeatingBasisFunction
为了保持简单,我们自己生成数据。在本例中,我们使用一个人工时间序列。我们首先创建一个空数据框,索引跨越四个日历年(我们使用pd.date_range)。然后,我们创建两列:
day_nr——表示时间流逝的数字索引day_of_year——一年中的第几天
最后,我们必须创建时间序列本身。为此,我们将两条经过变换的正弦曲线和一些随机噪声结合起来。用于生成数据的代码基于scikit-lego’s documentation 中包含的代码。
# for reproducibility np.random.seed(42) # generate the DataFrame with dates range_of_dates = pd.date_range(start="2017-01-01", End="2020-12-30") X = pd.DataFrame(index=range_of_dates) # create a sequence of day numbers X["day_nr"] = range(len(X)) X["day_of_year"] = X.index.day_of_year # generate the components of the target signal_1 = 3 + 4 * np.sin(X["day_nr"] / 365 * 2 * np.pi) signal_2 = 3 * np.sin(X["day_nr"] / 365 * 4 * np.pi + 365/2) noise = np.random.normal(0, 0.85, len(X)) # combine them to get the target series y = signal_1 + signal_2 + noise # plot y.plot(figsize=(16,4), title="Generated time series");
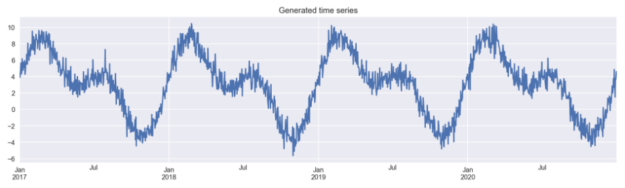
然后,我们创建一个新的数据帧,在其中存储生成的时间序列。该数据框架将用于使用不同的特征工程方法比较模型的性能。
results_df = y.to_frame() results_df.columns = ["actuals"]
创建与时间相关的功能
在本节中,我们将介绍三种生成时间相关特征的方法。
在深入研究之前,我们应该定义一个评估框架。我们的模拟数据包含四年的观察结果。我们将使用前三年生成的数据作为培训集,并在第四年进行评估。我们将使用平均绝对误差( MAE )作为评估指标。
下面我们定义了一个变量,用于切断这两个集合:
TRAIN_END = 3 * 365
方法# 1 :虚拟变量
我们从你最可能已经熟悉的东西开始,至少在某种程度上。编码时间相关信息的最简单方法是使用 dummy variables (也称为单热编码)。让我们看一个例子。
X_1 = pd.DataFrame( data=pd.get_dummies(X.index.month, drop_first=True, prefix="month") ) X_1.index = X.index X_1
下面,您可以看到我们操作的输出。
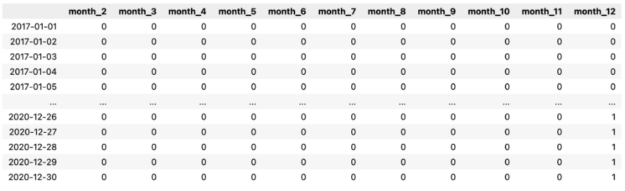
首先,我们从DatetimeIndex中提取关于月份的信息(编码为 1 到 12 的整数)。然后,我们使用pd.get_dummies函数创建虚拟变量。每列都包含有关观察(行)是否来自给定月份的信息。
正如你可能已经注意到的,我们已经降低了一个级别,现在只有 11 列。我们这样做是为了避免臭名昭著的 虚拟变量陷阱 (完美多重共线性),这在使用线性模型时可能会成为一个问题。
在我们的示例中,我们使用虚拟变量方法来捕获记录观察的月份。然而,同样的方法也可用于指示DatetimeIndex中的一系列其他信息。例如,一年中的天/周/季度、某一天是否为周末的标志、某一时段的第一天/最后一天,等等。您可以在 pandas.pydata.org 上找到一个列表,其中包含我们可以从pandas文档索引中提取的所有可能功能。
Bonus tip :这超出了这个简单练习的范围,但在现实生活场景中,我们还可以使用有关特殊日子的信息(比如国定假日、圣诞节、黑色星期五等)来创建功能。holidays是一个不错的 Python 库,包含每个国家过去和未来的特殊日子信息。
如引言所述,特征工程的目标是将复杂性从模型侧转移到特征侧。这就是为什么我们将使用一个最简单的 ML 模型——线性回归——来观察我们仅使用创建的模型就能很好地拟合时间序列。
model_1 = LinearRegression().fit(X_1.iloc[:TRAIN_END], y.iloc[:TRAIN_END]) results_df["model_1"] = model_1.predict(X_1) results_df[["actuals", "model_1"]].plot(figsize=(16,4), title="Fit using month dummies") plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
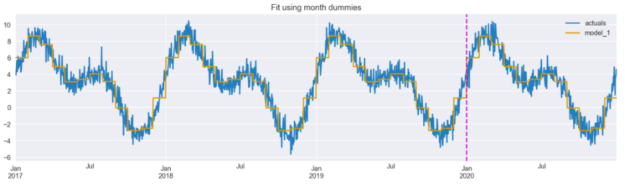
我们可以看到,拟合线已经很好地遵循了时间序列,尽管它有点锯齿状(阶梯状)——这是由虚拟特征的不连续性造成的。这就是我们将尝试用下两种方法解决的问题。
但在继续之前,可能值得一提的是,当使用决策树(或其集合)等非线性模型时,我们不会明确地将月数或一年中的某一天等特征编码为假人。这些模型能够学习有序输入特征和目标之间的非单调关系。
方法 2 :正弦/余弦变换循环编码
如前所述,拟合线类似于台阶。这是因为每个假人都是单独处理的,没有连续性。然而,时间等变量存在明显的周期性连续性。这是什么意思?
想象一下,我们正在处理能源消耗数据。当我们将观察到的消费月份的信息包括在内时,连续两个月之间的联系就更紧密了。按照这种逻辑, 12 月和 1 月之间以及 1 月和 2 月之间的联系非常紧密。相比之下, 1 月和 7 月之间的联系并没有那么紧密。这同样适用于其他与时间相关的信息。
那么,我们如何将这些知识整合到特征工程中呢?三角函数起到了解救的作用。我们可以使用以下正弦/余弦变换将周期时间特征编码为两个特征。
def sin_transformer(period): return FunctionTransformer(lambda x: np.sin(x / period * 2 * np.pi)) def cos_transformer(period): return FunctionTransformer(lambda x: np.cos(x / period * 2 * np.pi))
在下面的代码片段中,我们复制初始数据帧,添加带有月号的列,然后使用正弦/余弦变换对month和day_of_year列进行编码。然后,我们绘制两对曲线。
X_2 = X.copy()
X_2["month"] = X_2.index.month X_2["month_sin"] = sin_transformer(12).fit_transform(X_2)["month"]
X_2["month_cos"] = cos_transformer(12).fit_transform(X_2)["month"] X_2["day_sin"] = sin_transformer(365).fit_transform(X_2)["day_of_year"]
X_2["day_cos"] = cos_transformer(365).fit_transform(X_2)["day_of_year"] fig, ax = plt.subplots(2, 1, sharex=True, figsize=(16,8))
X_2[["month_sin", "month_cos"]].plot(ax=ax[0])
X_2[["day_sin", "day_cos"]].plot(ax=ax[1])
plt.suptitle("Cyclical encoding with sine/cosine transformation");
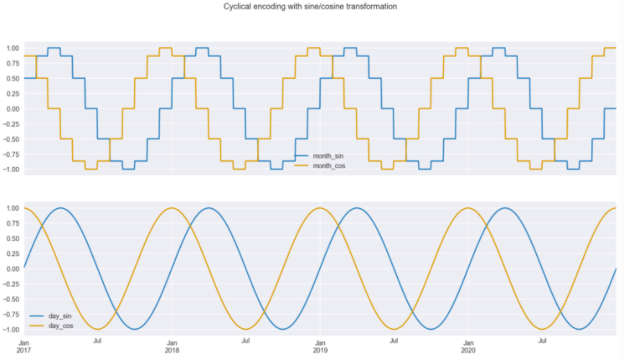
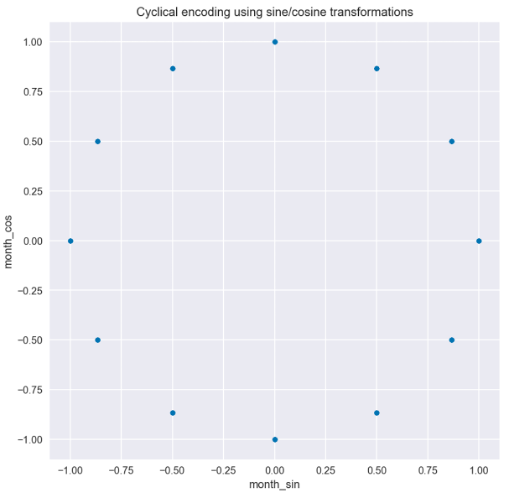
我们可以从转换后的数据中得出两个见解,如图 3 所示。首先,我们可以很容易地看到,当使用月份进行编码时,曲线是逐步的,但当使用日频率时,曲线要平滑得多;其次,我们也可以看到为什么我们必须使用两条曲线而不是一条。由于曲线的重复性,如果你在一年内画一条直线穿过地块,你会在两个地方穿过曲线。这还不足以让模型理解观测的时间点。但有了这两条曲线,就不存在这样的问题,用户可以识别每个时间点。当我们在散点图上绘制正弦/余弦函数的值时,这是显而易见的。在图 4 中,我们可以看到没有重叠值的圆形图案。
让我们只使用来自每日频率的新创建的特征来拟合相同的线性回归模型。
X_2_daily = X_2[["day_sin", "day_cos"]] model_2 = LinearRegression().fit(X_2_daily.iloc[:TRAIN_END], y.iloc[:TRAIN_END]) results_df["model_2"] = model_2.predict(X_2_daily) results_df[["actuals", "model_2"]].plot(figsize=(16,4), title="Fit using sine/cosine features") plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
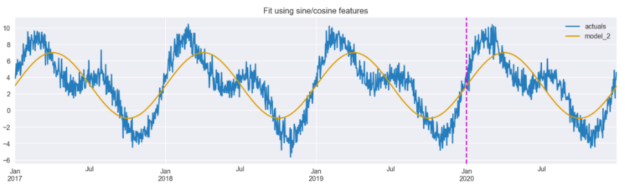
图 5 显示,该模型能够提取数据的总体趋势,识别具有较高和较低值的时段。然而,预测的大小似乎不太准确,乍一看,这种拟合似乎比使用虚拟变量实现的拟合更差(图 2 )。
在讨论第三种特征工程技术之前,值得一提的是,这种方法有一个严重的缺点,这在使用基于树的模型时是显而易见的。根据设计,基于树的模型在同一时间基于单个特征进行分割。正如我们之前所提到的,正弦/余弦特征应该同时考虑,以便正确识别一段时间内的时间点。
方法# 3 :径向基函数
最后一种方法使用径向基函数。我们不会详细介绍它们的实际情况,但您可以阅读更多关于 here 主题的内容。本质上,我们再次希望解决我们在第一种方法中遇到的问题,即我们的时间特征具有连续性。
我们使用方便的scikit-lego库,它提供RepeatingBasisFunction类,并指定以下参数:
- 我们想要创建的基函数的数量(我们选择了 12 个)。
- 使用哪一列为 RBF 编制索引。在我们的例子中,这是一个列,包含给定观测值来自一年中哪一天的信息。
- 输入的范围——在我们的例子中,范围是从 1 到 365 。
- 如何处理我们将用于拟合估计器的数据帧的剩余列。
”drop”将只保留创建的 RBF 功能,”passthrough”将保留旧功能和新功能。
rbf = RepeatingBasisFunction(n_periods=12, column="day_of_year", input_range=(1,365), remainder="drop") rbf.fit(X) X_3 = pd.DataFrame(index=X.index, data=rbf.transform(X)) X_3.plot(subplots=True, figsize=(14, 8), sharex=True, title="Radial Basis Functions", legend=False);
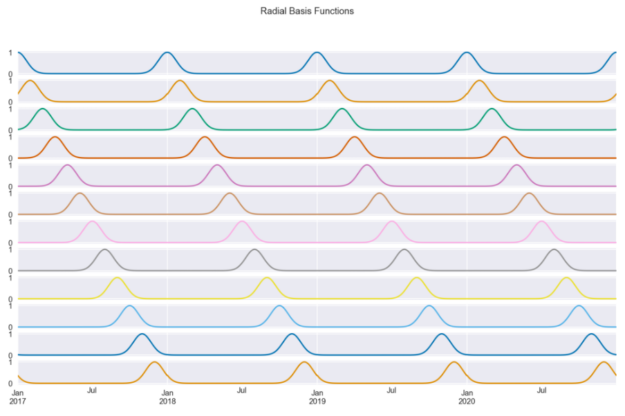
图 6 显示了我们使用天数作为输入创建的 12 个径向基函数。每一条曲线都包含关于我们离一年中某一天有多近的信息(因为我们选择了该列)。例如,第一条曲线测量的是从 1 月 1 日开始的距离,因此它在每年的第一天达到峰值,并在我们离开该日期时对称地减小。
通过设计,基函数在输入范围内是等间距的。我们选择了 12 个,因为我们想让 RBF 看起来像几个月。通过这种方式,每个函数大致显示(由于月份长度不相等)到月份第一天的距离。
与前面的方法类似,让我们使用 12 个 RBF 特征拟合线性回归模型。
model_3 = LinearRegression().fit(X_3.iloc[:TRAIN_END], y.iloc[:TRAIN_END]) results_df["model_3"] = model_3.predict(X_3) results_df[["actuals", "model_3"]].plot(figsize=(16,4), title="Fit using RBF features") plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
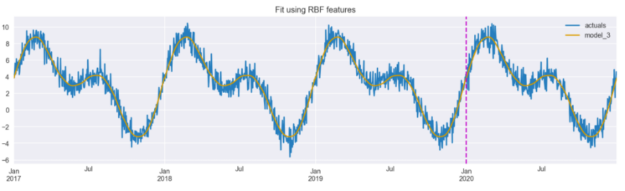
图 7 显示,当使用 RBF 特征时,该模型能够准确捕获真实数据。
使用径向基函数时,我们可以调整两个关键参数:
- 径向基函数的个数,
- 钟形曲线的形状–可以使用
RepeatingBasisFunction的width参数进行修改。
调整这些参数值的一种方法是使用网格搜索来确定给定数据集的最佳值。
最后的比较
我们可以执行以下代码片段,对编码时间相关信息的不同方法进行数值比较。
results_df.plot(title="Comparison of fits using different time-based features", figsize=(16,4), color = ["c", "k", "b", "r"]) plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
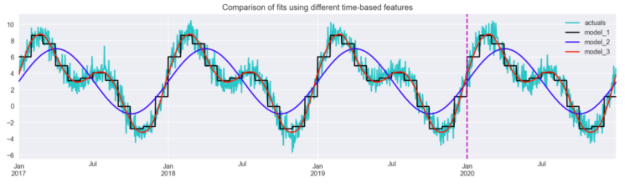
图 8 说明了径向基函数与所考虑的方法最接近。正弦/余弦特征允许模型拾取主要模式,但不足以完全捕捉序列的动态。
使用下面的代码片段,我们计算每个模型在训练集和测试集上的平均绝对误差。我们预计训练集和测试集之间的分数非常相似,因为生成的序列几乎完全是周期性的——年份之间的唯一区别是随机成分。
当然,在现实生活中情况并非如此,在现实生活中,随着时间的推移,我们在同一时期会遇到更多的变化。然而,在这种情况下,我们还将使用许多其他特征(例如,某种趋势或时间推移的度量)来解释这些变化。
score_list = []
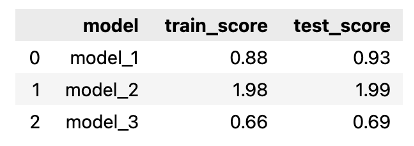
for fit_col in ["model_1", "model_2", "model_3"]: scores = { "model": fit_col, "train_score": mean_absolute_error( results_df.iloc[:TRAIN_END]["actuals"], results_df.iloc[:TRAIN_END][fit_col] ), "test_score": mean_absolute_error( results_df.iloc[TRAIN_END:]["actuals"], results_df.iloc[TRAIN_END:][fit_col] ) } score_list.append(scores) scores_df = pd.DataFrame(score_list)
scores_df
与之前一样,我们可以看到使用 RBF 特征的模型得到了最佳拟合,而正弦/余弦特征表现最差。我们关于训练集和测试集之间分数相似性的假设也得到了证实。
外卖
- 我们展示了三种将时间相关信息编码为机器学习模型特征的方法。
- 除了最流行的虚拟编码外,还有一些方法更适合对时间的周期性进行编码。
- 使用这些方法时,时间间隔的粒度对新创建的特征的形状非常重要。
- 使用径向基函数,我们可以决定要使用的函数的数量,以及钟形曲线的宽度。
您可以在我的 GitHub 上找到本文使用的代码。如果您有任何反馈,我很乐意在 Twitter 上讨论。
工具书类
- https://scikit-learn.org/stable/auto_examples/applications/plot_cyclical_feature_engineering.html
- https://scikit-lego.readthedocs.io/en/latest/preprocessing.html
- https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#time-date-components




