
实例分割是检测和分割目标的一个核心视觉识别问题。在过去几年中,该领域一直是计算机视觉领域的圣杯之一,其应用范围广泛,包括自动驾驶汽车( AV )、机器人技术、视频分析、智能家居、数字人类和医疗保健。
注释是对图像或视频中的每个对象进行分类的过程,是实例分割的一个具有挑战性的组成部分。训练 面具 R-CNN 等传统实例分割方法需要同时使用对象的类标签、边界框和分割遮罩。
然而,获取分割掩模既昂贵又耗时。例如, 可可数据集 需要大约 70000 小时的时间来注释 200k 图像,其中 55000 小时用于收集对象遮罩。
介绍 Discobox
为了加快注释过程, NVIDIA 研究人员开发了 DiscoBox 框架。该解决方案使用了一种弱监督学习算法,可以在训练期间输出高质量的实例分割,而无需掩码注释。
该框架直接从边界框监控生成实例分段,而不是使用掩码注释直接监控任务。边界框作为一种基本的注释形式被引入,用于训练现代对象检测器,并使用带标签的矩形来紧密地包围对象。每个矩形对对象的定位、大小和类别信息进行编码。
边界框标注是工业计算机视觉应用的最佳选择。它包含丰富的本地化信息,并且非常容易绘制,使得在注释大量数据时,它更经济、更具可扩展性。然而,它本身不提供像素级信息,不能直接用于训练实例分割。
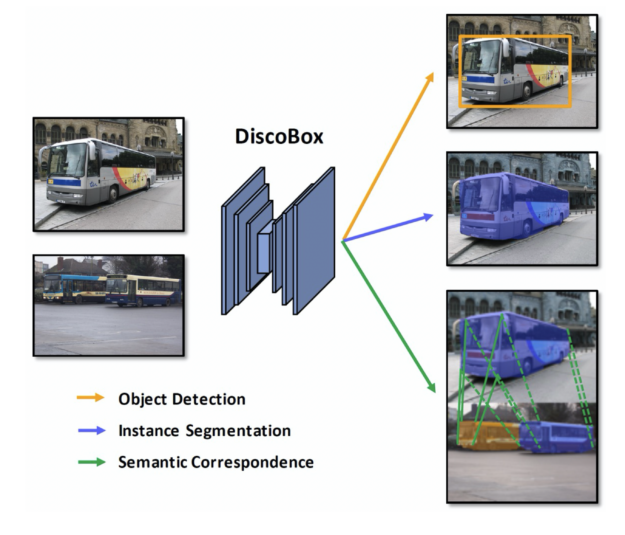
DiscoBox 的创新功能
DiscoBox 是第一个弱监督的实例分割算法,它在减少标记时间和成本的同时,提供了与完全监督方法相当的性能。例如,这种方法比传说中的面具 R-CNN 更快、更准确,在训练期间不需要面具注释。这就提出了一个问题,即在未来的实例分割应用中,是否真的需要掩码注释,因为需要更少的标记。
DiscoBox 也是第一个在盒子监督下将实例分割和多对象语义对应结合起来的弱监督算法。这两项任务在许多计算机视觉应用中都很有用,例如 3D 重建,并且可以相互帮助。例如,通过实例分割预测的对象遮罩可以帮助语义对应关注前景对象像素,而语义对应可以细化遮罩预测。 DiscoBox 将这两项任务统一在盒子的监督下,使他们的模型训练变得简单且可扩展。
DiscoBox 的中心是一个师生设计。该设计的特点是使用自我一致性作为自我监督,以取代 DiscoBox 培训中缺失的面罩监督。该设计有效地促进了高质量的口罩预测,即使在训练中没有口罩注释。
DiscoBox 应用
除了作为 NVIDIA 人工智能应用程序的自动标签工具包之外, DiscoBox 还有许多应用程序。通过自动化昂贵的掩码注释,该工具可以帮助智能视频分析或 AV 领域的产品团队节省大量注释预算。




另一个潜在的应用是 3D 重建,在这个领域中,对象遮罩和语义对应都是重建任务的重要信息。 DiscoBox 能够在只有边界框监控的情况下提供这两个输出,帮助在开放世界场景中生成大规模 3D 重建。这将有助于构建虚拟世界的许多应用程序,如内容创建、虚拟现实和数字人类。
有关模型或使用代码的更多信息,请访问 GitHub 上的 DiscoBox 。
要了解更多关于 NVIDIA 正在进行的研究,请访问 NVIDIA Research 。




