
目前,AI 领域最引人注目的问题之一是大型语言模型 (LLM) 是否可以通过持续强化学习 (RL) 继续改进,或者其能力是否最终会达到顶峰。
ProRL v2 是 NVIDIA 研究团队开发的 Prolonged Reinforcement Learning (ProRL) 的最新版本,专门用于测试扩展强化学习训练对 LLM 的影响。ProRL v2 利用先进的算法、严格的正则化和全面的领域覆盖,将边界远远推到了典型的 RL 训练计划之外。我们的实验系统地探索了模型在执行数千个额外的强化学习步骤时能否取得可衡量的进步。
今天,我们很高兴地宣布发布 ProRL v2。本文解释了关键创新和先进方法,并分享了 ProRL v2 的新经验结果,这些结果实现了最先进的性能,揭示了 LLM 如何继续学习和改进。
ProRL v2 如何实现 RL 扩展?
思维链提示、树搜索和其他 AI 技术可帮助模型更好地利用其已有的知识。RL,尤其是具有严格的、可编程验证奖励的 RL,有望将模型推向全新的领域。然而,传统的短期 RL 技术往往会不稳定,回报迅速递减,因此被称为“温度蒸馏”,而不是真正的边界扩展推动者。
ProRL 从根本上挑战了这一范式。它提供:
- 扩展训练:在五个不同的领域中,超过 3000 个 RL 步骤在 1.5B 推理模型中实现了新的最先进的性能。
- 稳定性和鲁棒性:采用 KL 正则化信任区域、周期性参考策略重置和计划长度正则化。
- 完全可验证的奖励:每个奖励信号都是通过编程确定的,并且始终可检查。
- 强制简明:预定的余弦长度惩罚确保输出保持简洁高效。
目标是超越重新采样这些熟悉的方法,真正扩展模型可以发现的内容。
| 传统 RL 微调 | ProRL v2:用于强化学习的开源平台,可用于训练和测试 RL 智能体。 |
| 几百个步骤,一个域 | 3,000+ 个步骤,五个领域 |
| 熵崩溃、KL 峰值 | PPO-Clip、REINFORCE++-baseline、Clip-Higher、动态采样、参考重置 |
| 风险奖励模型漂移 (RRM Drift) | 完全可验证的系统奖励: |
| 冗长输出 | 预定余弦长度惩罚项 (Scheduled cosine length penalty) |
核心技术:ProRL 算法和正则化器
ProRL v2 基于 REINFORCE++ 基线构建而成,该基线利用 Clip-Higher 来鼓励探索,并利用动态采样来降低噪声和提高学习效率。我们推出了多项创新,包括:
- 用于生成简洁输出的预定余弦长度惩罚项
- KL 正则化信任区域,定期参考重置当前最佳检查点,以帮助防止过拟合并确保稳定性
使用 REINFORCE++ 基线进行近似策略优化
ProRL 的核心是 clipped proximal policy optimization (PPO-Clip) loss,它通过限制新策略与旧策略的差异程度来稳定策略更新:
\mathcal{L}_\mathrm{PPO}(\theta) = \mathbb{E}_\tau\bigg[
\min\Big( r_\theta(\tau) A(\tau),\
\mathrm{clip}\big(r_\theta(\tau), 1 - \varepsilon_\mathrm{low}, 1 +
\varepsilon_\mathrm{high}\big) A(\tau) \Big)
\bigg]
地点:





group 指的是针对同一提示生成的全部响应(组归一化)。
REINFORCE++ 基线中的全局批量归一化有助于防止小批量大小导致的值不稳定。它首先减去小群体的平均奖励,以重塑奖励。因此,该算法对 0(错误)/ 1(正确)/ -0.5(格式奖励)或 -1(错误)/ 1(正确)/ -0.5(格式奖励)等奖励模式并不敏感。然后,它应用全局批量归一化。
剪辑边界:
\varepsilon_{\text{low}} = 0.20 \qquad \varepsilon_{\text{high}} = 0.28
Clip-Higher 和动态采样技术
Clip-Higher 使用 PPO 剪辑范围的上限来减轻策略熵崩溃并提高采样多样性 (
动态采样会丢弃具有所有 1(完全正确)或 0(完全错误)奖励的组响应的提示,以减少梯度估计中的噪声。
预定余弦长度惩罚项 (Scheduled cosine length penalty)
为了促进简洁、令牌高效的输出,应用了预定的余弦长度惩罚:
\text{length\_reward}(t) = \eta_{\min} + 0.5 \times (\eta_{\max} - \eta_{\min})
\times [ 1 + \cos ( \pi t / T ) ]
地点:
= 当前输出长度(token)
= 上下文 token 限制
、
= 奖励/惩罚边界
奖励更新:
R'_\tau = R_{\text{correct}} + \lambda_\text{len} \cdot \eta_\text{len}(t)
该惩罚项会定期开启和关闭(例如,开启 100 个更新,关闭 500 个更新),以平衡信息量和简洁性。
KL 正则化和参考策略重置
KL 惩罚项可使策略保持接近参考值。定期重置有助于防止过度拟合并确保稳定性:
\mathcal{L}_\mathrm{KL\text{-}RL} = \mathcal{L}_\mathrm{PPO} - \beta\,
D_\mathrm{KL}(\pi_\theta\ \|\ \pi_\mathrm{ref})
REINFORCE++ 基线中的 KL 散度使用 
\mathcal{L}_{k_{2}} = \mathbb{E}_{s \sim D,\ a \sim
\pi_{\theta_{\text{old}}}(\cdot|s)} \left( \frac{1}{2} ( -\log x )^2 \right)
使用:
\[
x = \exp \left( \mathrm{clamp}\left(
\log \frac{\pi_{\text{ref}}(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)}, -10, 10
\right) \right)
\]
在此,函数 

![[-10, 10]](https://s0.wp.com/latex.php?latex=%5B-10%2C+10%5D&bg=transparent&fg=000&s=0&c=20201002)
参考重置:
每 200-500 个 RL 步骤(或在 KL 出现尖峰/验证停滞时),参考策略 
通过定期重置参考策略,模型避免受到过时指导的限制,从而能够继续有效地学习。
定期应用的预定余弦长度惩罚也发挥着重要作用。通过循环开启和关闭惩罚,模型避免陷入短或固定上下文长度,从而提高输出的准确性和 token 效率。这两种策略相结合,可防止模型受到参考策略或上下文长度的限制,从而支持随着时间的推移不断提高准确性和整体性能。
在扩展 LLM 的强化学习方面发现了什么?
我们发现了新的先进性能、持续改进、新颖的解决方案和突破性的进展。
- 全新先进的性能:随着 RL 训练步骤的增加,性能不断提高,ProRL v2 3K 为 1.5B 推理模型树立了新的记录。
- 持续的、非微不足道的改进:Pass@1 和 pass@k 指标在数千个 RL 步骤中不断攀升,扩大了基础模型的推理边界。
- 创意和新颖的解决方案:ProRL 输出显示与预训练数据的 n-gram 重叠减少,表明真正的创新而非死记硬背。
- 突破极限:在基础模型一直失败的任务中,ProRL 不仅实现了较高的通过率,而且还展示了强大的分布外泛化能力。
ProRL 综合结果
ProRL 在数学、代码生成和各种推理健身房基准测试中进行了评估。报告的分数包括:
- Base:DeepSeek-R1-Distill-Qwen-1.5B
- ProRL v1 2K:2,000 个 RL 步骤(使用 16K 上下文训练)
- ProRL v2 3K:3,000 个 RL 步骤(使用 8K 上下文训练)
截至撰写本文时,该模型仍在进行持续训练和准确性改进。下图显示了 2K 步模型相对于基本模型以及 3K 步模型相对于 2K 步模型的性能提升。即使训练上下文长度减半(从 16K 减少到 8K),计算成本大大降低,但整个模型的准确性在所有任务中都有所提高。


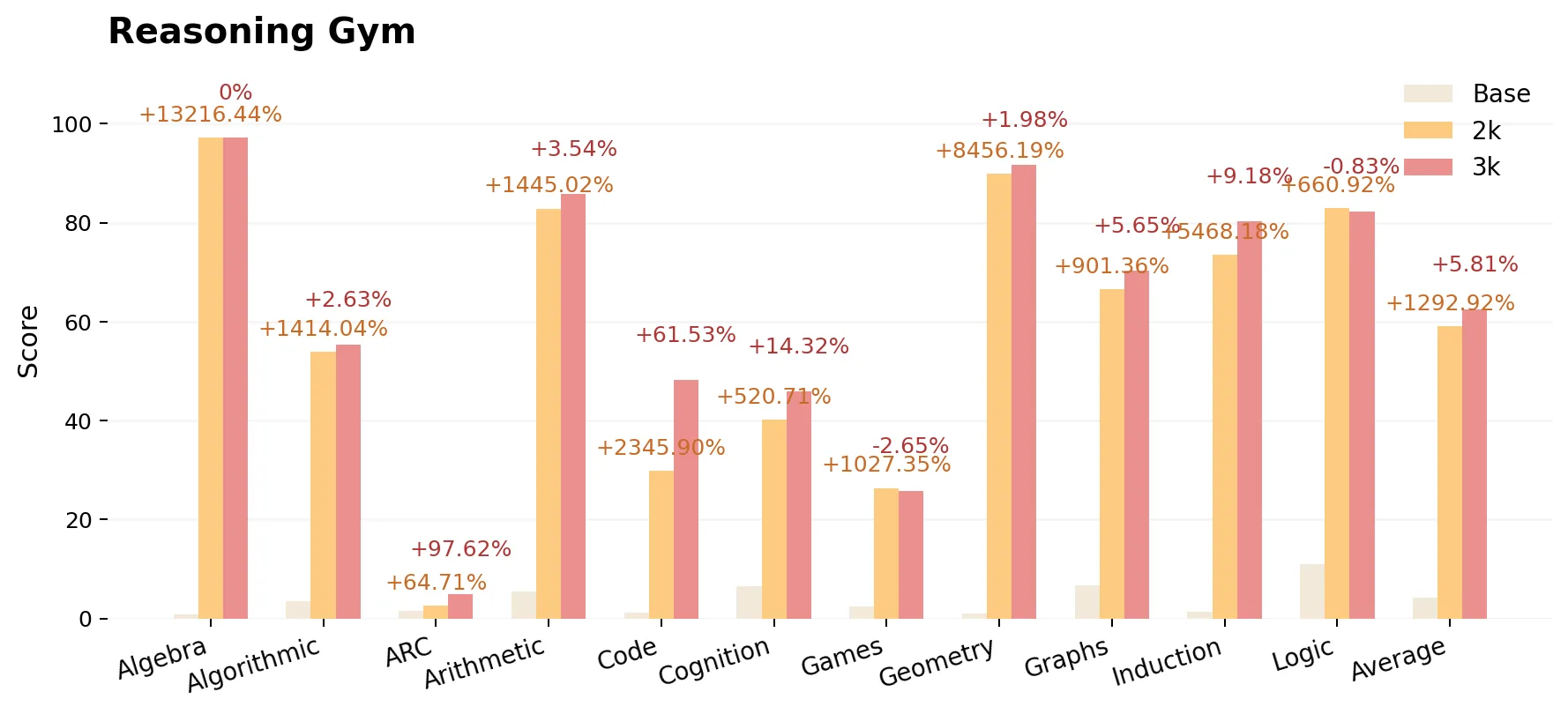

结论
我们的经验结果表明,通过长时间的强化学习,LLM 可以在数学、代码和推理任务中实现持续改进,超过了传统训练程序通常观察到的性能。我们的评估表明,在各种基准测试(包括具有挑战性的非分布式任务)中,扩展的强化学习训练都能显著提高模型的推理能力。
- 新的先进的 1.5B 推理模型 ProRL v2 3K 的性能显著优于其基础模型 DeepSeek-R1-1.5B,并超越了 ProRL v1 2K 之前所取得的先进性能。
- ProRL 在数学、代码和推理方面持续可靠地改进,特别是在基础模型(即使采用积极采样)完全失败的领域。
- 更多计算和更多参数:进一步推动 RL 发展(而不仅仅是扩大模型规模)将大大推动边界扩展。
- 收益稳健:改进并非偶然;几乎每个子任务都受益于持续的强化学习。
对于旨在突破模型性能极限或探索 LLM 推理潜力的从业者而言,ProRL 提供了一个可复制的基础和实用的训练方法。随着开源模型和基准测试的推出,社区被鼓励进一步探索和验证这些发现,作为对 LLM 的 RL 极限和机会的持续研究的一部分。
准备好开始了吗?在 Hugging Face 上探索 ProRL 模型。




