
人工智能正在改变每一个行业,实现传统软件无法实现的强大的新应用程序和用例。随着人工智能的不断扩散,以及人工智能模型的规模和复杂性的不断增加,人工智能计算性能的重大进步需要跟上。
这就是 NVIDIA 平台的所在地。
凭借跨越芯片、系统、软件甚至整个数据中心的全堆栈方法, NVIDIA 为所有人工智能工作负载(包括人工智能培训)提供了最高的性能和最大的通用性。NVIDIA 在 MLPerf 培训 v1 中展示了这一点。 1 ,行业标准的最新版本,经同行评审的基准套件,用于测量跨广泛网络的 ML 培训性能。由 NVIDIA A100 GPU 核心张量 提供动力的系统,包括 Azure NDm A100 v4 云实例 ,提供了图表上的最佳结果,创造了新的记录,并且是唯一完成所有八项 MLPerf 训练测试的系统。
所有主要的云服务提供商都提供了由 A100 供电的NVIDIA GPU 加速实例,使公共云成为 NVIDIA 平台的性能和能力的一个很好的地方。在这篇文章中,我将展示一种基于 A100 选择当前一代实例的策略,这种策略不仅可以在云中提供最快的人工智能模型训练时间,而且是最具成本效益的。
NVIDIA A100 涡轮增压人工智能培训
NVIDIA A100 是基于 Ampere architecture ,它包含了与前一代 NVIDIA V100 相比,如第三代张量核心、新一代 NVLink 和更大的内存带宽加速 AI 培训的主机创新。这些增强带来了巨大的性能飞跃,从而缩短了训练各种人工智能网络的时间。
在本文中,我使用 ResNet-50 表示图像分类, BERT 用于自然语言处理, DLRM 用于推荐系统。

图 1 。NVIDIA A100 与NVIDIA V100 相比,大大缩短了训练人工智能模型的时间。
GPU 服务器:双插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB 和双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司机: 465.19.01 ;数据集: ResNet-50 v1 的 ImageNet2012 。 5 号, v1 小队。 1 对于 BERT 大型微调, DLRM 的标准 TB 数据集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量大小: A100 , V100 = 65536 。
更快的培训时间加快了洞察的速度,最大限度地提高了组织数据科学团队的生产力,并更快地部署了经过培训的网络。还有另一个重要的好处:降低成本!
云实例通常按单位时间定价,按需使用通常按小时定价。培训模型的成本是每小时实例定价和培训模型所需时间的乘积。
虽然选择时薪最低的实例很有诱惑力,但这可能不会导致最低的培训成本。以每小时计算,一个实例可能会稍微便宜一些,但训练一个模型所需的时间要长得多。培训的总成本比价格更高的实例更快地完成工作的成本要高。此外,等待较慢的实例完成训练运行也会浪费时间。
在前面显示的性能数字中,NVIDIA A100 可以比 NVIDIA V100 更快地训练模型。这几乎是 BERT 大微调的 3 倍。与此同时,来自主要云服务提供商的 100 个基于实例的定价通常只比上一代基于 V100 的同类产品有适度的溢价。
在本文中,我将讨论与基于 V100 的云实例相比,使用基于 100 的云实例如何在培训 AI 模型时节省时间和金钱。
将绩效转化为节约
考虑到人工智能训练的巨大计算需求,通常使用多个 GPU 协同工作来训练模型,以显著减少训练时间。
NVIDIA 平台已经被设计为提供业界领先的每加速器性能,并达到最佳性能和最高的 ROI 在规模上,由于技术 NVLink 和 NVSwitch 。这就是为什么在本文中,我估计与八个 NVIDIA V100 GPU 实例相比,八个 NVIDIA A100 GPU 实例可以节省成本。
在本次分析中,我估计了培训 ResNet-50 、微调 BERT Large ,以及在三大云服务提供商 Amazon Web 服务、谷歌云平台和 Microsoft Azure 上培训基于 V100 和 A100 的实例的 DLRM 的相对成本。
| CSP | Instance | GPU Configuration |
| Amazon Web Services | p4d.24xlarge | 8x NVIDIA A100 40GB |
| p3dn.24xlarge | 8x NVIDIA V100 32GB | |
| p3.16xlarge | 8x NVIDIA V100 16GB | |
| Google Cloud Platform | a2-highgpu-8g | 8x NVIDIA A100 40GB |
| n1-highmem-96 | 8x NVIDIA V100 16GB | |
| Microsoft Azure | Standard_ND96asr_v4 | 8x NVIDIA A100 40GB |
| ND40rs v2 | 8x NVIDIA V100 32GB |
估算方法
为了估计云实例的训练性能,我使用测量的时间在 NVIDIA DGX 系统上训练数据,该系统具有与实例中的配置相对应的 GPU 配置。由于与这些云合作伙伴进行了深入的工程合作, NVIDIA 支持的云实例的性能应该与 DGX 系统上可实现的性能相似。
然后,根据测量的训练时间数据,我使用按需、每小时实例定价来估计训练 ResNet-50 、微调 BERT 大型和训练 DLRM 的成本。
估计成本节约
以下图表都讲述了一个类似的故事:无论您选择哪家云服务提供商,在培训一系列人工智能模型时,基于最新的 NVIDIA A100 GPU 选择实例都可以转化为显著的成本节约。这是,即使在每小时的基础上,基于NVIDIA A100 的实例比使用前一代 V100 GPU 的实例更昂贵。
Amazon 网络服务:
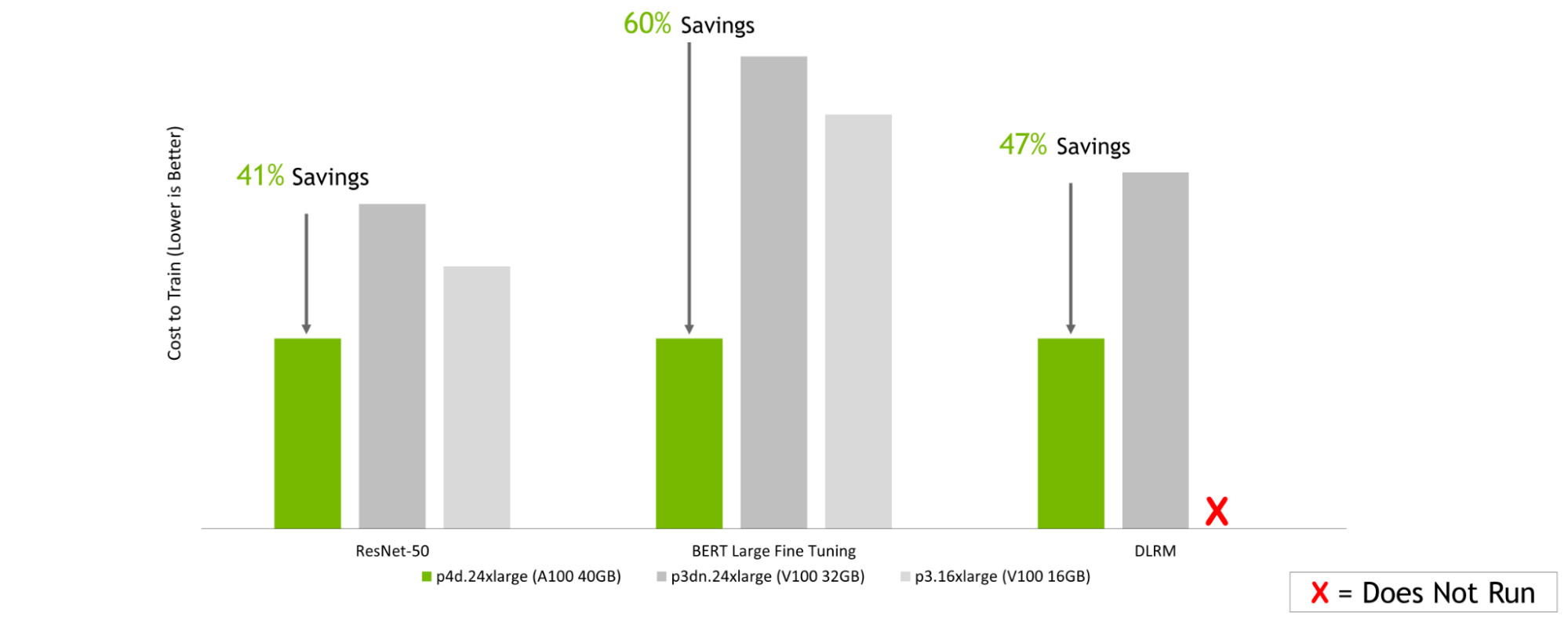
GPU 服务器:双插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB ,双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB ,双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-16GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司机: 465.19.01 ;数据集: ResNet-50 v1 的 Imagenet2012 。 5 号, v1 小队。 1 对于 BERT 大型微调, DLRM 的标准 TB 数据集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量: A100 , V100 = 65536 ;使用在早期配置上运行的性能数据以及截至 2022 年 2 月 8 日的按需实例定价估算成本。
谷歌云平台 :
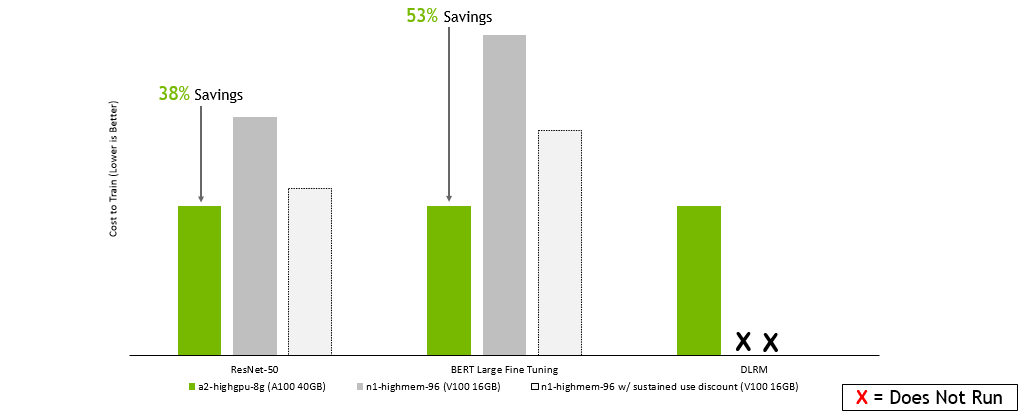
GPU 服务器:双插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB ,双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB ,双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-16GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司机: 465.19.01 ;数据集: ResNet-50 v1 的 ImageNet2012 。 5 号, v1 小队。 1 对于 BERT 大型微调, DLRM 的标准 TB 数据集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量: A100 , V100 = 65536 ;使用在早期配置上运行的性能数据以及截至 2022 年 2 月 8 日的按需实例定价估算成本。
Microsoft Azure :
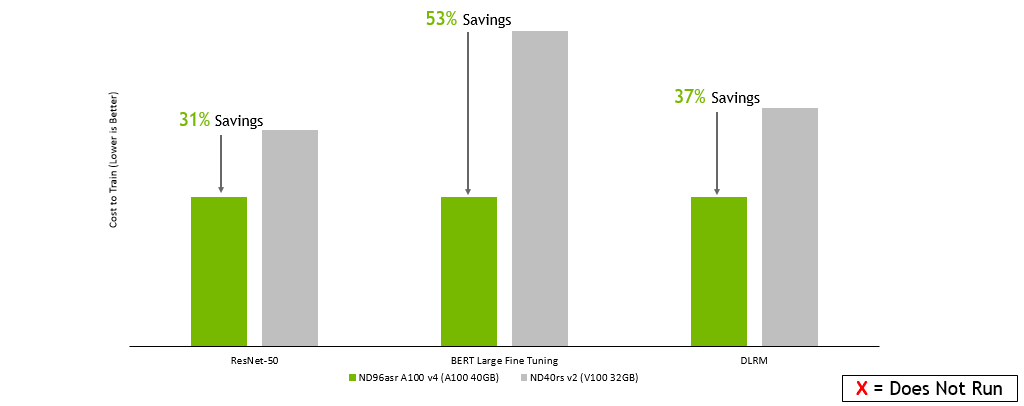
GPU 服务器:双插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB ,双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB ,双插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-16GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司机: 465.19.01 ;数据集: ResNet-50 v1 的 ImageNet2012 。 5 号, v1 小队。 1 对于 BERT 大型微调, DLRM 的标准 TB 数据集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量: A100 , V100 = 65536 ;使用在早期配置上运行的性能数据以及截至 2022 年 2 月 8 日的按需实例定价估算的成本。
除了提供更低的培训成本和为用户节省大量时间之外,使用当前一代实例还有另一个好处:它们支持全新的人工智能用例。例如,基于人工智能的推荐引擎正变得越来越流行,NVIDIA GPU 常用于对其进行培训。图 5 总结了 100 个实例跨不同云提供商提供的成本和时间节约:
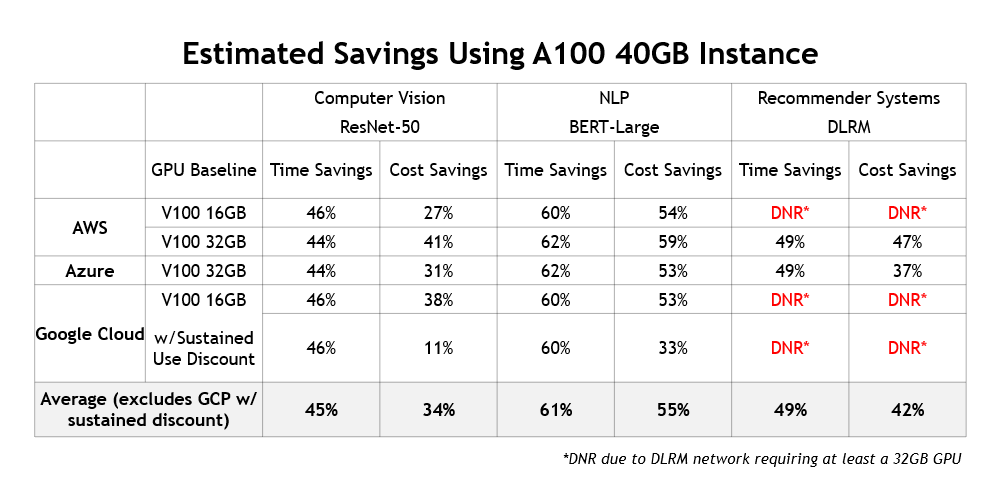
更高的性能也意味着更高的节约
这里展示的这些结果表明,与使用上一代 GPU 的旧版实例相比,当前一代 NVIDIA GPU 加速实例提供的性能要高得多,超过了每小时定价差异。
基于最新 NVIDIA A100 GPU 的实例不仅可以通过减少培训时间来最大限度地提高数据科学团队的生产力,而且是在云中培训模型的最经济高效的方式。
要了解更多关于在云中使用 NVIDIA 加速的选项,请参阅 Cloud Computing 。




