作为发布合作伙伴,NVIDIA 与 Google 合作提供了Gemma,这是一个新优化的开放模型系列,它基于创建 Gemini 模型时所使用的相同研究和技术构建。通过使用 TensorRT-LLM 的优化版本,用户只需配备NVIDIA RTX GPU,即可享受到这些优势。
由 Google DeepMind 创建,Gemma 2B 和 Gemma 7B 作为该系列的首批模型,Gemma 可实现高吞吐量和先进性能。通过 TensorRT-LLM (用于优化推理性能的开源库) 加速,Gemma 可兼容从数据中心、云到本地 PC 的各种 NVIDIA AI 平台。
以前,LLM 的优化和部署非常复杂,令人望而却步。使用 TensorRT-LLM 简化的 Python API 可以轻松实现量化和内核压缩。Python 开发者可以针对热门 LLM 自定义模型参数、减少内存占用、提高吞吐量并降低推理延迟。Gemma 模型使用的词汇量为 256K,支持的上下文长度高达 8K。
通过广泛的数据管护和以安全为导向的训练方法,将安全性内置于 Gemma 模型中。个人识别信息 (PII) 过滤可从预训练和指令调整数据集中删除标识符(例如社会安全号)。此外,根据人类反馈进行的大量微调和强化学习 (RLHF) 可将指令调整模型与负责任的行为保持一致。
开发者使用超过 6 万亿个令牌进行训练,可以满怀信心地构建和部署高性能、负责任的高级 AI 应用程序。
TensorRT-LLM 让 Gemma 模型更快
TensorRT-LLM 具有大量优化和内核,可提高推理吞吐量和延迟。TensorRT-LLM 的三项独特功能可提升 Gemma 的性能,即 FP8、XQA 和 INT4 激活感知权重量化 (INT4 AWQ)。
FP8 是加速深度学习应用程序的自然进展,超越了现代处理器中常见的 16 位格式。FP8 在不牺牲准确性的情况下实现了更高的矩阵乘法和内存传输吞吐量。在内存带宽受限的模型中,它既有助于小批量处理,也在计算密度和内存容量至关重要时处理大批量表现出色。
TensorRT-LLM 还为 KV 缓存提供 FP8 量化。KV 缓存不同于在批量大或上下文长度较长的情况下占用不可忽略的持久内存的正常激活。切换到 FP8 KV 缓存可在提高性能的同时,运行 2-3 倍的批量大小。
XQA 是一个支持组查询注意力和多查询注意力的内核。XQA 是 NVIDIA AI 开发的新内核,可在生成阶段提供优化,并优化波束搜索。 NVIDIA GPU 减少了数据加载和转换时间,在相同的延迟预算内提高了吞吐量。
INT4 AWQ 也获得 TensorRT-LLM 提供支持。AWQ 可为批量大小不超过 4 的小工作负载提供卓越的性能。它可减少网络的内存占用,并显著提高内存带宽受限的应用程序的性能。AWQ 是一种仅采用低位权重的量化方法,可减少量化误差。它通过利用激活函数保护重要的权重。
通过结合 INT4 和 AWQ 的优势,适用于 INT4 AWQ 的 TensorRT-LLM 自定义内核可根据 LLM 的相对重要性将其权重压缩到 4 位,并在 FP16 中执行计算。这有助于提供比其他 4 位方法更高的准确性,同时减少内存占用并显著加速。
实时性能,每秒超过 7.9 万个令牌
搭载 NVIDIA H200 Tensor Core GPU 的 TensorRT-LLM 可在 Gemma 2B 和 Gemma 7B 模型上提供出色的性能。单个 H200 GPU 在 Gemma 2B 模型上每秒可提供超过 79000 个令牌,在较大的 Gemma 7B 模型上每秒可提供近 19000 个令牌。
结合这种性能,仅在一个 H200 GPU 上部署的搭载 TensorRT-LLM 的 Gemma 2B 模型可以为 3000 多个并发用户提供实时延迟服务。
立即开始
通过您的浏览器直接体验 Gemma,访问 NVIDIA AI Playground。您还可以在 NVIDIA 与 RTX 聊天 演示应用中体验即将推出的 Gemma。
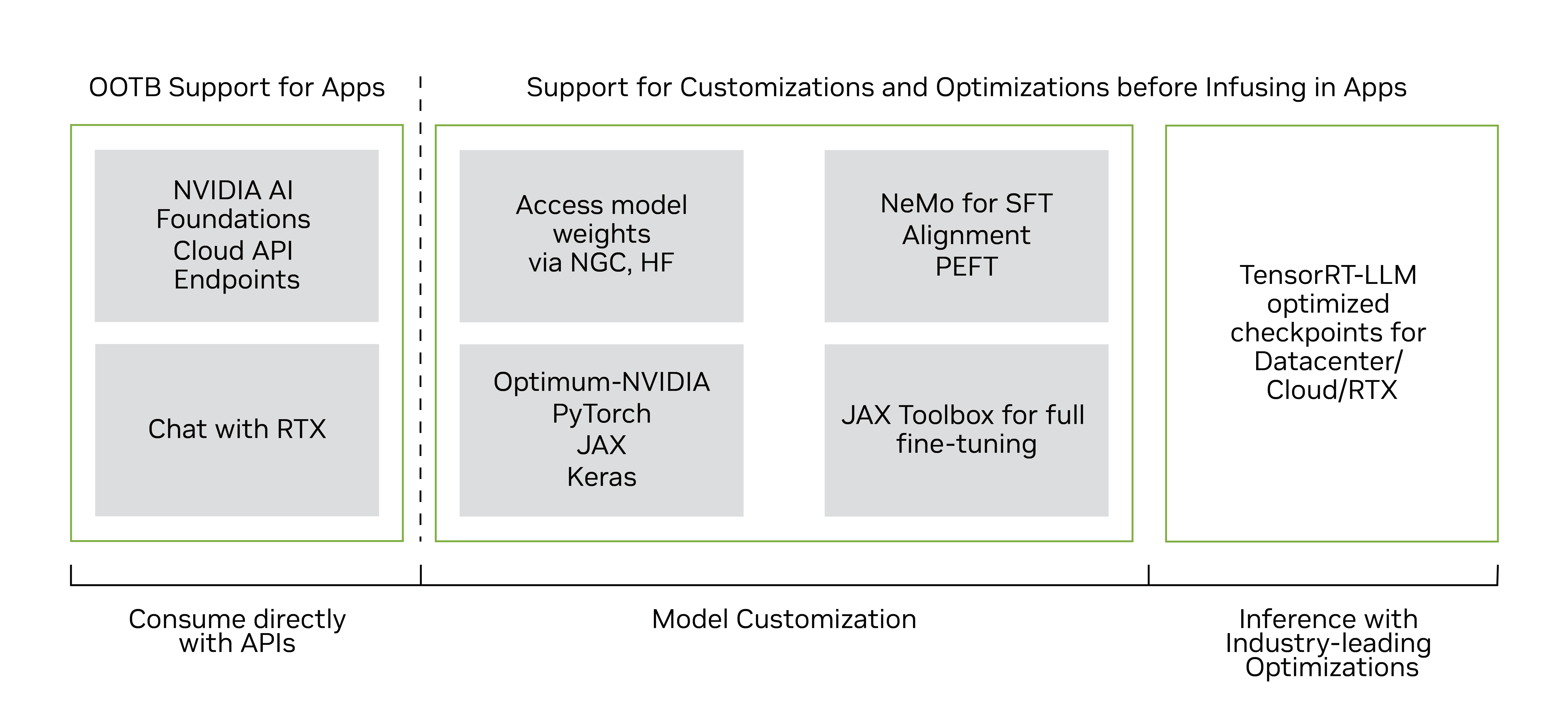
多个经过优化的 TensorRT-LLM Gemma-2B 和 Gemma-7B 模型检查点(包括预训练和指令调优版本)现已在 NGC 上提供,用于在 NVIDIA GPU(包括消费级 RTX 系统)上运行优化模型。
很快,您将能够在 Omniverse 中体验到 TensorRT-LLM 优化的 FP8 量化模型版本,这些模型基于最佳 NVIDIA 库,并且只需一行代码即可集成快速 LLM 推理。
开发者可以使用NVIDIA NeMo 框架来定制和部署 Gemma 在生产环境中。NeMo 框架提供了多种自定义技术,如监督微调、使用 LoRA 和 RLHF 的参数高效微调,以及支持训练的 3D 并行性。通过 Notebook 开始使用 Gemma 和 NeMo 进行编码。
立即开始使用 NeMo 框架自定义 Gemma。