
RAPIDS 25.08 版本持续突破极限,新增多项功能,进一步提升了加速数据科学的易用性和可扩展性,包括:
- 两个新的分析工具,用于对 cuml.accel 代码进行故障排除
- Polars GPU 引擎支持更大、更复杂的数据
- cuML 和 cuml.accel 中的新算法支持
- CUDA 版本支持的更新
请在下方详细了解新增功能。
适用于 cuML 零代码更改加速器的新分析工具
在 25.08 版本中,cuml.accel 新增了两项分析功能。与此前为 cudf.pandas 推出的分析器类似,这些功能可帮助用户了解在机器学习工作流中,哪些操作通过 GPU 上的 cuML 实现了加速,哪些操作回退至 CPU 执行,以及各类操作的耗时情况。这对于识别当前性能瓶颈、优化工作流效率具有重要意义。
首先,我们引入了函数级分析器。该分析器能够显示在给定脚本或单元中,所有在 GPU 和 CPU 上执行的操作,并展示每个函数的执行时间。
函数级分析器有两种使用方法。如果运行的是 Jupyter 或 IPython notebook,用户可以在加载 cuml.accel 后调用 %%cuml.accel.profile,对整个单元进行分析。
%%cuml.accel.profile
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100)
# Fit and predict on GPU
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
ridge.predict(X)
# Retry, using an unsupported hyperparameter
ridge = Ridge(positive=True)
ridge.fit(X, y)
ridge.predict(X)
本单元的输出包含分析结果:
cuml.accel profile
┏━━━━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┓
┃ Function ┃ GPU calls ┃ GPU time ┃ CPU calls ┃ CPU time ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━┩
│ Ridge.fit │ 1 │ 141.2ms │ 1 │ 3ms │
│ Ridge.predict │ 1 │ 31.5ms │ 1 │ 97.3µs │
├───────────────┼───────────┼──────────┼───────────┼──────────┤
│ Total │ 2 │ 172.7ms │ 2 │ 3.1ms │
└───────────────┴───────────┴──────────┴───────────┴──────────┘
Not all operations ran on the GPU. The following functions required CPU fallback for the following reasons:
* Ridge.fit
- `positive=True` is not supported
* Ridge.predict
- Estimator not fit on GPU
还可以通过 CLI 中的 --profile 标志,在 Python 脚本中调用函数级分析器:
python -m cuml.accel --profile script.py
第二个分析器是行级分析器,能够显示用户执行代码时具体到每一行的位置。与函数级分析器类似,行级分析器也可以在使用 %%cuml.accel.line_profile 的 Notebook 中调用。
%%cuml.accel.line_profile
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100)
# Fit and predict on GPU
ridge = Ridge(alpha=1.0)
ridge.fit(X, y)
ridge.predict(X)
# Retry, using an unsupported hyperparameter
ridge = Ridge(positive=True)
ridge.fit(X, y)
ridge.predict(X)
cuml.accel line profile
┏━━━━┳━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ # ┃ N ┃ Time ┃ GPU % ┃ Source ┃
┡━━━━╇━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 1 │ 1 │ - │ - │ from sklearn.linear_model import Ridge │
│ 2 │ 1 │ - │ - │ from sklearn.datasets import make_regression │
│ 3 │ │ │ │ │
│ 4 │ │ │ │ │
│ 5 │ 1 │ 1.1ms │ - │ X, y = make_regression(n_samples=100) │
│ 6 │ │ │ │ │
│ 7 │ │ │ │ │
│ 8 │ │ │ │ # Fit and predict on GPU │
│ 9 │ 1 │ - │ - │ ridge = Ridge(alpha=1.0) │
│ 10 │ 1 │ 174.2ms │ 99.0 │ ridge.fit(X, y) │
│ 11 │ 1 │ 5.2ms │ 99.0 │ ridge.predict(X) │
│ 12 │ │ │ │ │
│ 13 │ │ │ │ │
│ 14 │ │ │ │ # Retry, using an unsupported hyperparameter │
│ 15 │ 1 │ - │ - │ ridge = Ridge(positive=True) │
│ 16 │ 1 │ 4.5ms │ 0.0 │ ridge.fit(X, y) │
│ 17 │ 1 │ 172.7µs │ 0.0 │ ridge.predict(X) │
│ 18 │ │ │ │ │
└────┴───┴─────────┴───────┴──────────────────────────────────────────────┘
Ran in 185.6ms, 96.4% on GPU
还可以通过命令行中的 --line-profile 参数启用行分析器:
python -m cuml.accel --line-profile script.py
借助这些新增的分析功能,cuml.accel 为用户提供了更多工具,让机器学习代码的加速与调试变得更加便捷。
使用由 NVIDIA cuDF 提供支持的 Polars GPU 引擎处理更大、更复杂的数据
使用新的默认流式传输执行程序处理大于 GPU 显存的数据集
在 25.06 版本中作为实验性功能引入的流式执行模式,现已成为 Polars GPU 引擎的默认执行方式。该执行引擎通过数据分片,能够高效处理远超 GPU 显存容量的数据集。对于少数暂不支持的操作,流式执行模式仍可回退至内存执行模式;而从 25.08 版本起,流式执行已基本覆盖内存中 GPU 执行所支持的全部算子,显著提升了系统的性能与可扩展性。
对于较小的数据集,在单个 GPU 上使用流式传输执行模式相比内存引擎仅带来轻微的性能开销。然而,随着数据集规模增大并逐渐超出 GPU 显存容量,流式传输执行器相比内存引擎能够实现显著的性能提升。
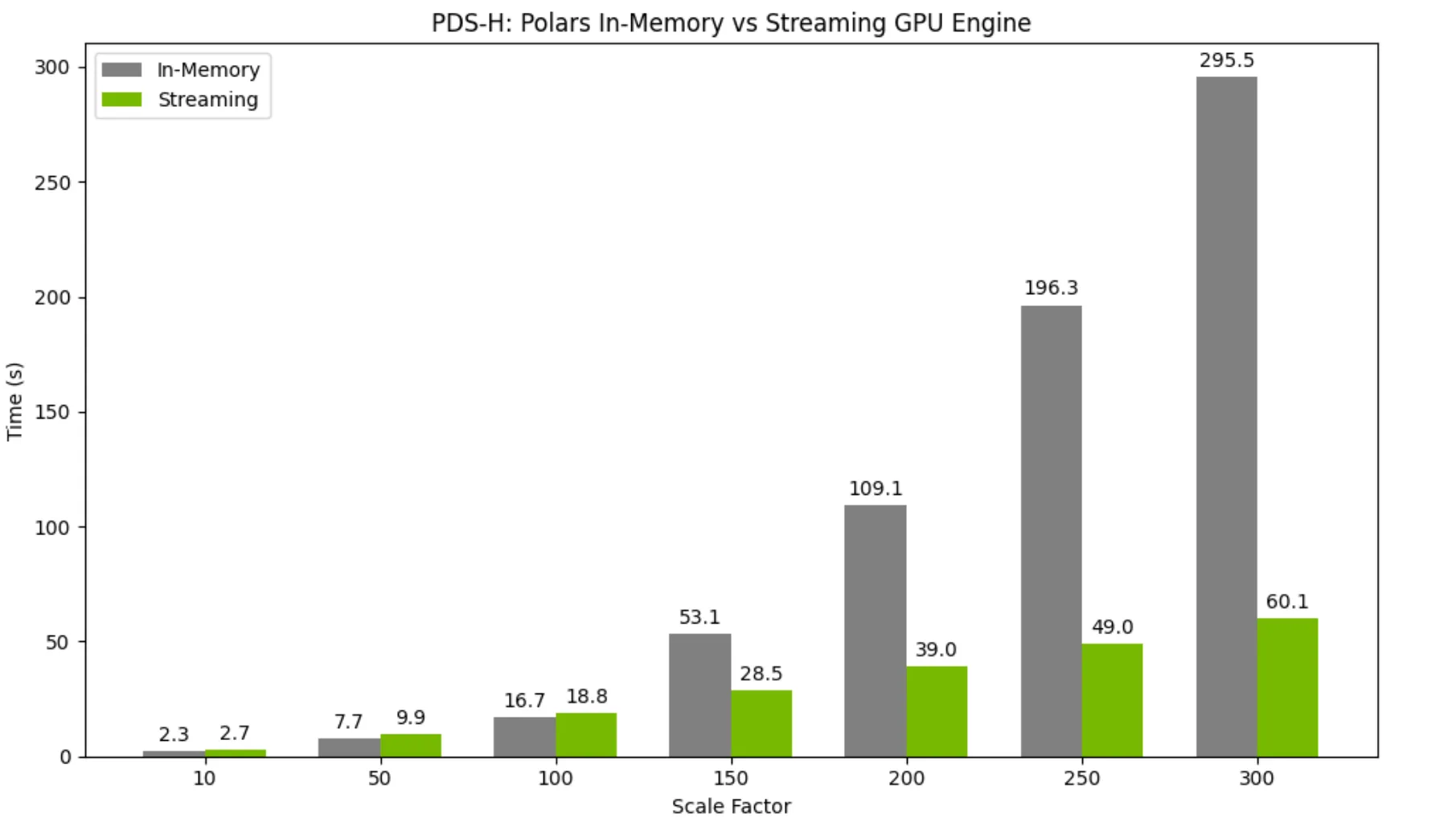
有关 Polars GPU 流式执行引擎的更多详细信息,请参阅我们的文档。
在 GPU 上保留结构和字符串操作等复杂数据
Polars GPU 引擎现已支持列中的结构化数据。此前,任何涉及结构体的操作都会回退到 CPU 执行;而随着新版本的发布,这些操作均已实现 GPU 加速,显著提升了性能。
>>> import polars as pl
... ratings = pl.LazyFrame(
... {
... "Movie": ["Cars", "IT", "ET", "Cars", "Up", "IT", "Cars", "ET", "Up", "ET"],
... "Theatre": ["NE", "ME", "IL", "ND", "NE", "SD", "NE", "IL", "IL", "SD"],
... "Avg_Rating": [4.5, 4.4, 4.6, 4.3, 4.8, 4.7, 4.7, 4.9, 4.7, 4.6],
... "Count": [30, 27, 26, 29, 31, 28, 28, 26, 33, 26],
... }
... )
... ratings.select(pl.col("Theatre").value_counts()).collect(engine=pl.GPUEngine(raise_on_fail=True))
...
shape: (5, 1)
┌───────────┐
│ Theatre │
│ --- │
│ struct[2] │
╞═════════==╡
│ {"NE",3} │
│ {"ND",1} │
│ {"ME",1} │
│ {"SD",2} │
│ {"IL",3} │
└───────────┘
此外,Polars GPU 引擎现已支持大量字符串操作符,例如:
>>> ldf = pl.LazyFrame({"foo": [1, None, 2]})
>>> ldf.select(pl.col("foo").str.join("-")).collect(engine=gpu_engine)
shape: (1, 1)
┌─────┐
│ foo │
│ --- │
│ str │
╞═════╡
│ 1-2 │
└─────┘
>>> ldf = pl.LazyFrame({
... "lines": [
... "I Like\nThose\nOdds",
... "This is\nThe Way",
... ]
... })
... ldf.with_columns(
... pl.col("lines").str.extract(r"(T\w+)", 1).alias("matches"),
... ).collect(engine=pl.GPUEngine(raise_on_fail=True))
...
shape: (2, 2)
┌─────────┬──────┐
│ lines ┆ matches │
│ --- ┆ --- │
│ str ┆ str │
╞═════════╪══════╡
│ I Like ┆ Those │
│ Those ┆ │
│ Odds ┆ │
│ This is ┆ This │
│ The Way ┆ │
└─────────┴──────┘
数据类型支持的扩展进一步增强了 Polars GPU 引擎的功能,有助于更快地交付用户最常使用的功能。
cuML 中支持的新算法:Spectral Embedding、LinearSVC、LinearSVR 和 KernelRidge
在 25.08 版本中,cuML 引入了用于降维与流形学习的谱嵌入(Spectral Embedding)算法。该方法通过构建相似度图,并利用其特征值与特征向量,将高维数据映射到低维空间。
cuML 中新增的 Spectral Embedding 算法的 API 与 scikit-learn 中 Spectral Embedding 实现的 API 保持一致。
from cuml.manifold import SpectralEmbedding
import cupy as cp
from sklearn.datasets import fetch_openml
# (70000, 784) -> (70000, 2)
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist.data, mnist.target.astype(int)
spectral = SpectralEmbedding(n_components=2, n_neighbors=None, random_state=42)
embedding = spectral.fit_transform(cp.asarray(X, order='C', dtype=cp.float32))
此外,cuml.accel 现在无需修改代码即可加速多种新算法。在 25.08 版本中,新增了 LinearSVC 和 LinearSVR 估计器,这意味着支持向量机系列的所有估计器均已纳入 cuml.accel 的支持范围。
KernelRidge 也被添加到 cuml.accel 中,在无需修改代码的情况下引入了另一种广受欢迎的回归算法。
有关当前支持的算法的更多详细信息,请参阅我们的完整文档。
弃用 CUDA 11 支持
从 25.08 版本开始,我们将不再支持 CUDA 11,因为 CUDA 11 已涵盖所有容器、已发布的软件包以及从源码构建的功能。希望继续使用 CUDA 11 的用户可选用 RAPIDS 25.06 版本。
访问 RAPIDS 官方文档 以获取更多详细信息。
总结
NVIDIA RAPIDS 25.08 版本在加速和优化数据科学工作流程方面实现了显著突破。随着 cuml.accel 分析器的推出,开发者现在能够借助这一强大工具对机器学习代码进行性能诊断与优化。Polars GPU 引擎的更新,包括流式执行引擎和对更多数据类型的支持,进一步提升了处理大规模数据集时的效率、可扩展性和整体性能。此外,cuML 中新增的算法也使机器学习生态系统更加完善。这些改进共同推动了加速数据科学的易用性与效率。如需详细了解各项新功能与优化,欢迎查阅 RAPIDS 官方文档。
欢迎在 GitHub 上提交您的反馈。您还可以加入 RAPIDS Slack 社区,与三千五百多名成员共同探讨 GPU 加速的数据处理。
如果您还不熟悉 RAPIDS,可以通过 相关资源 快速入门,并免费参加我们的 “零代码更改加速数据科学工作流程”课程。如需深入了解如何加速数据科学,欢迎探索我们的 DLI 学习路径,报名参加实战培训,例如 “利用 GPU 加速实现表格数据特征工程的高效实践”。






