对万亿参数模型的兴趣是什么?我们知道当今的许多用例,并且由于有望提高以下方面的能力,人们的兴趣正在增加:
- 自然语言处理任务,例如翻译、问答、抽象和流畅性。
- 掌握长期背景和对话能力。
- 结合语言、视觉和语音的多模态应用。
- 创意应用,如叙事、诗歌生成和代码生成。
- 科学应用,例如蛋白质折叠预测和药物研发。
- 个性化,能够培养一致的个性并记住用户上下文。
其优势是巨大的,但训练和部署大型模型的计算成本高昂且需要大量资源。旨在提供实时推理的计算高效、经济高效且节能的系统对于广泛部署至关重要。新的 NVIDIA GB200 NVL72 就是这样一个系统,可以完成这项任务。
为了说明这一点,我们考虑一下多专家模型 (MoE).这些模型有助于在多个专家之间分配计算负载,并使用模型并行和管道并行跨数千个 GPU 进行训练。提高系统效率。
然而,并行计算、高速显存和高性能通信的新水平可以使 GPU 集群能够应对棘手的技术挑战。 NVIDIA GB200 NVL72 机架级架构实现了这一目标,我们将在以下博文中详细介绍。
适用于百亿亿级 (Exascale) AI 超级计算机的机架级设计
核心 GB200 NVL72 是 NVIDIA GB200 Grace Blackwell 超级芯片。它将两个高性能 NVIDIA Blackwell Tensor Core GPU 和 NVIDIA Grace CPU 通过 NVLink 芯片到芯片 (C2C) 接口连接,可提供 900 GB/s 的双向带宽。借助 NVLink-C2C,应用程序可以一致地访问统一内存空间。这简化了编程,并支持万亿参数 LLM、用于多模态任务的 Transformer 模型、用于大规模模拟的模型和用于 3D 数据的生成模型的更大内存需求。
GB200 计算托盘基于新的 NVIDIA MGX 设计。它包含两个 Grace CPU 和四个 Blackwell GPU.GB200 具有冷却板和液体冷却接口,PCIe Gen 6 支持高速网络,以及用于 NVLink 线缆盒的 NVLink 接口。GB200 计算托盘提供 80 petaflop 的 AI 性能和 1.7 TB 的快速内存。

最大的问题是需要足够数量的突破性成果,这些成果使用 Blackwell GPU,因此它们必须以高带宽和低延迟进行通信,并始终保持忙碌状态。
GB200 NVL72 机架级系统使用带有 9 个 NVLink 交换机托盘的 NVIDIA NVLink Switch 系统以及互连 GPU 和交换机的线缆盒,提高了 18 个计算节点的并行模型效率。
NVIDIA GB200 NVL36 和 NVL72
GB200 在 NVLink 域中支持 36 个和 72 个 GPU.每个机架根据 MGX 参考设计和 NVLink Switch 系统托管 18 个计算节点。它采用 GB200 NVL36 配置,一个机架中包含 36 个 GPU,另一个 GB200 计算节点中包含 18 个单 GB200 计算节点。GB200 NVL72 在一个机架中配置 72 个 GPU,在两个机架中配置 18 个双 GB200 计算节点,即 72 个 GPU,其中有 18 个单 GB200 计算节点。
GB200 NVL72 使用铜缆盒密集封装和互连 GPU,以简化操作。它还采用液冷系统设计,成本和能耗降低 25 倍。

第五代 NVLink 和 NVLink Switch 系统
NVIDIA GB200 NVL72 引入了第五代 NVLink,可在单个 NVLink 域中连接多达 576 个 GPU,总带宽超过 1 PB/s,快速内存超过 240 TB.每个 NVLink 交换机托盘提供 144 个 100 GB 的 NVLink 端口,因此 9 台交换机可完全连接 72 个 Blackwell GPU 上的 18 个 NVLink 端口。
每个 GPU 革命性的 1.8 TB/s 双向吞吐量是 PCIe 5.0 带宽的 14 倍以上,可为当今极为复杂的大型模型提供无缝高速通信。

跨代 NVLink
NVIDIA 行业领先的高速低功耗 SerDes 创新推动了 GPU 到 GPU 通信的发展,首先是推出 NVLink,以高速加速多 GPU 通信。NVLink GPU 到 GPU 带宽为 1.8 TB/s,是 PCIe 带宽的 14 倍。第五代 NVLink 比 2014 年推出的第一代 160 GB/s 快 12 倍。NVLink GPU 到 GPU 通信在扩展 AI 和 HPC 领域的多 GPU 性能方面发挥了重要作用。
自 2014 年以来,GPU 带宽的进步,加上 NVLink 域的指数级扩展,使得 576 Blackwell GPU NVLink 域的 NVLink 域的总带宽增加了 900 倍,达到 1 PB/s。
用例和性能结果
GB200 NVL72 的计算和通信能力前所未有,使 AI 和 HPC 领域的重大挑战触手可及。
AI 训练
GB200 包含速度更快的第二代 Transformer 引擎,具有 FP8 精度。与相同数量的 NVIDIA H100 GPU 相比,GB200 NVL72 可为 GPT-MoE-1.8 T 等大型语言模型提供 4 倍的训练性能。
AI 推理
GB200 引入了先进的功能和第二代 Transformer 引擎,可加速 LLM 推理工作负载。与上一代 H100 相比,它将资源密集型应用程序 (例如 1.8 T 参数 GPT-MoE) 的速度提高了 30 倍。新一代 Tensor Core 引入了 FP4 精度和第五代 NVLink 带来的诸多优势,使这一进步成为可能
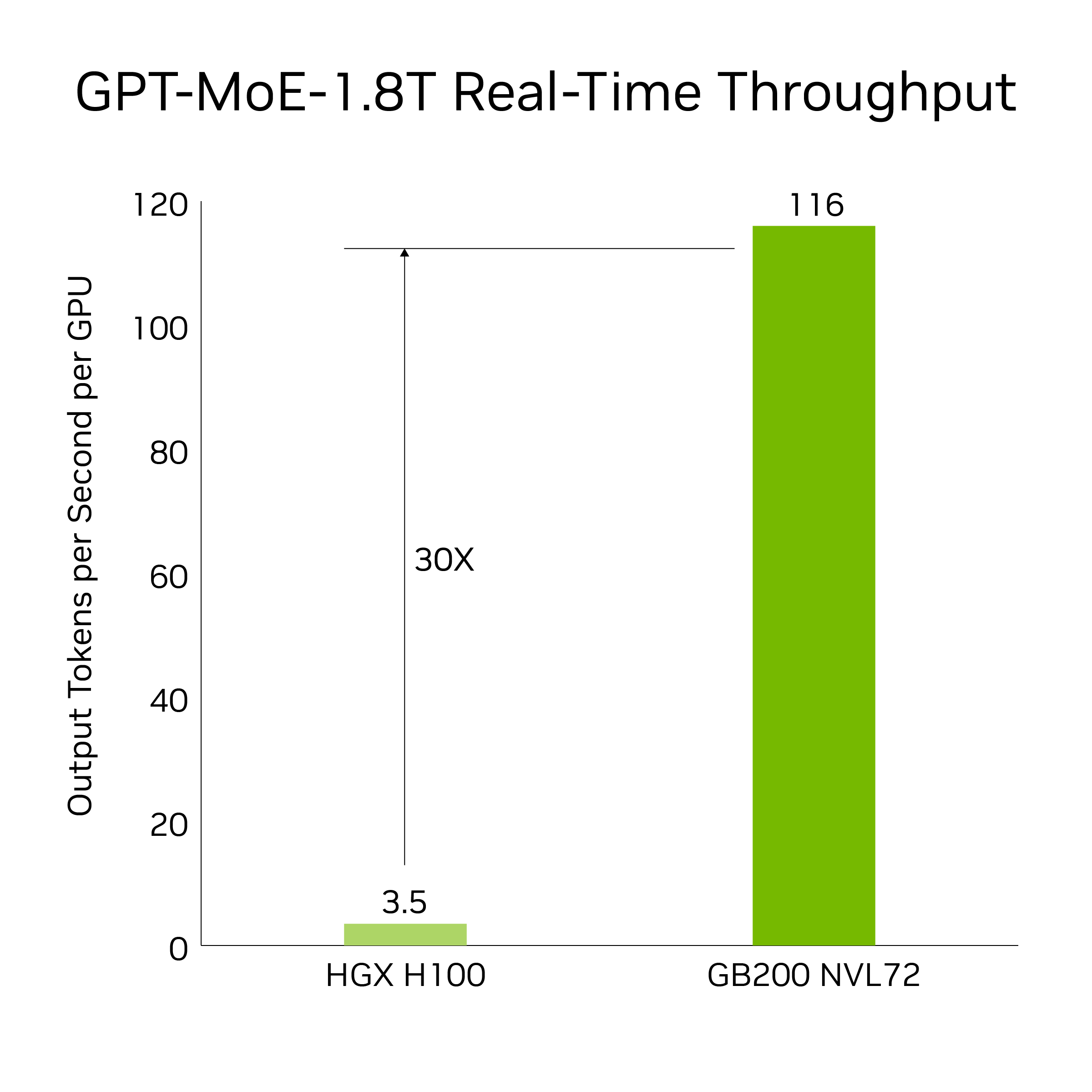
结果基于令牌到令牌延迟=50 毫秒;第一个令牌实时延迟=5000 毫秒;输入序列长度=32768;输出序列长度=1024 路输出,8 路 8 路 HGX H100 风冷:400 GB IB 网络与 18 GB200 超级芯片液冷:NVL36,每个 GPU 性能比较*.预测性能可能会发生变化。
相比于使用 GPT-MoE-1.8 T 的 GB200 NVL72 中的 32 个 Blackwell GPU,相比之下,30 倍加速是通过 8 路 NVLink 和 InfiniBand 扩展的 64 个 NVIDIA Hopper GPU。
数据处理
大数据分析有助于组织获得见解并做出更明智的决策。组织不断大规模生成数据,并依靠各种压缩技术来缓解瓶颈并节省存储成本。为了在 GPU 上高效处理这些数据集,Blackwell 架构引入了硬件解压缩引擎,该引擎可以大规模地原生解压缩压缩数据,并加速端到端分析流程。解压缩引擎原生支持使用 LZ4、Deflate 和 Snappy 压缩格式解压缩数据。
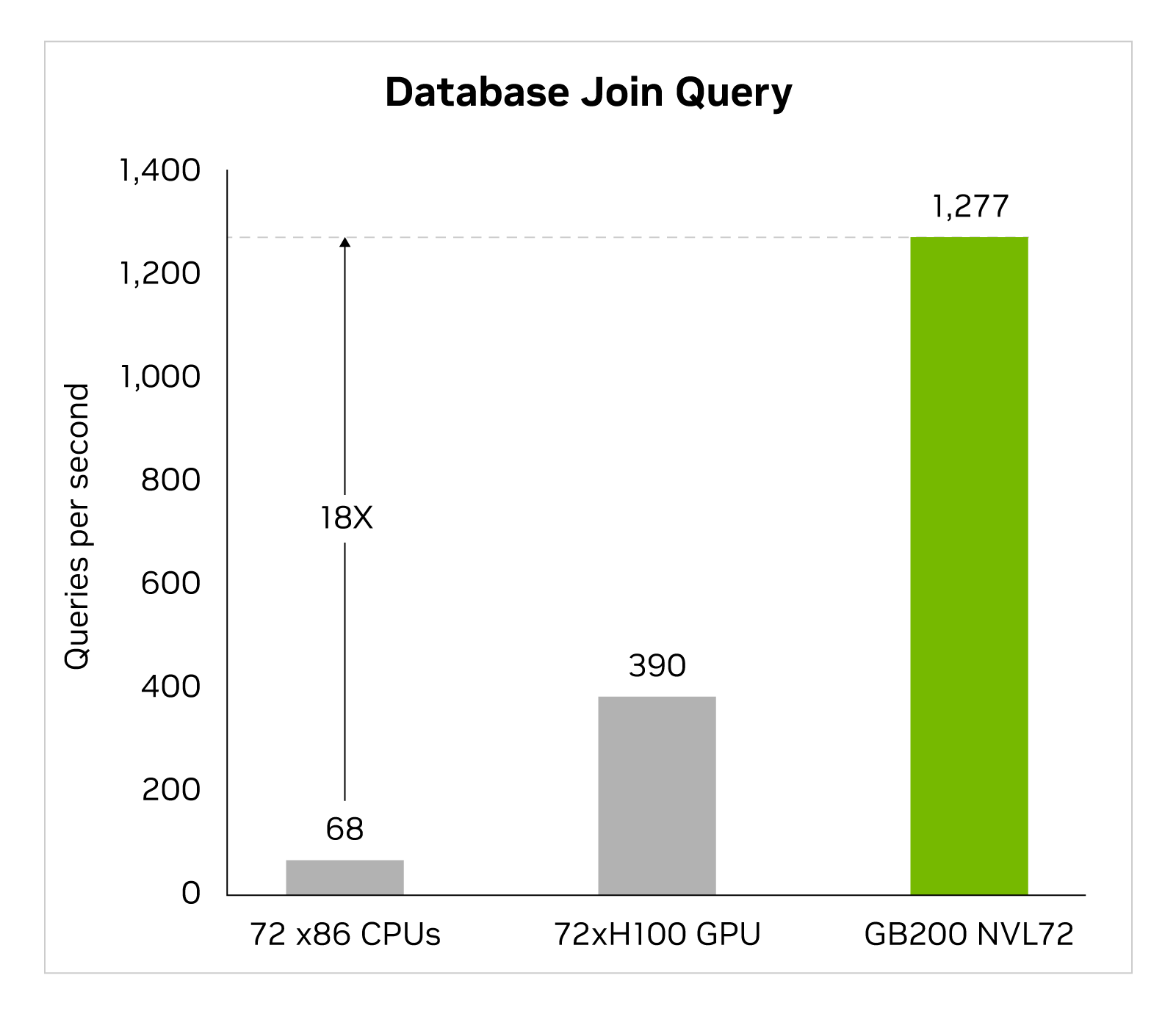
解压缩引擎可加快受内存限制的内核操作速度。它提供高达 800 GB/s 的性能,使 Grace Blackwell 的执行速度比 CPU (Sapphire Rapids) 快 18 倍,比 NVIDIA H100 Tensor Core GPU 在查询基准测试中的执行速度快 6 倍。
借助 8 TB/s 的高显存带宽和 Grace CPU 高速 NVlink 芯片到芯片 (C2C),该引擎可加快数据库查询的整个过程。这可在数据分析和数据科学用例中实现出色的性能。这使得组织能够在降低成本的同时快速获得见解。
基于物理性质的模拟
基于物理性质的模拟仍然是产品设计和开发的中流柱。从飞机和火车到桥梁、硅芯片,甚至是药物,通过模拟测试和改进产品可节省数十亿美元。
在漫长而复杂的工作流程中,特定于应用程序的集成电路几乎完全在 CPU 上设计,包括用于识别电压和电流的模拟分析。Cadence SpectreX 模拟器就是求解器的一个示例。下图显示了 SpectreX 在 GB200 上的运行速度比在 x86 CPU 上快 13 倍。
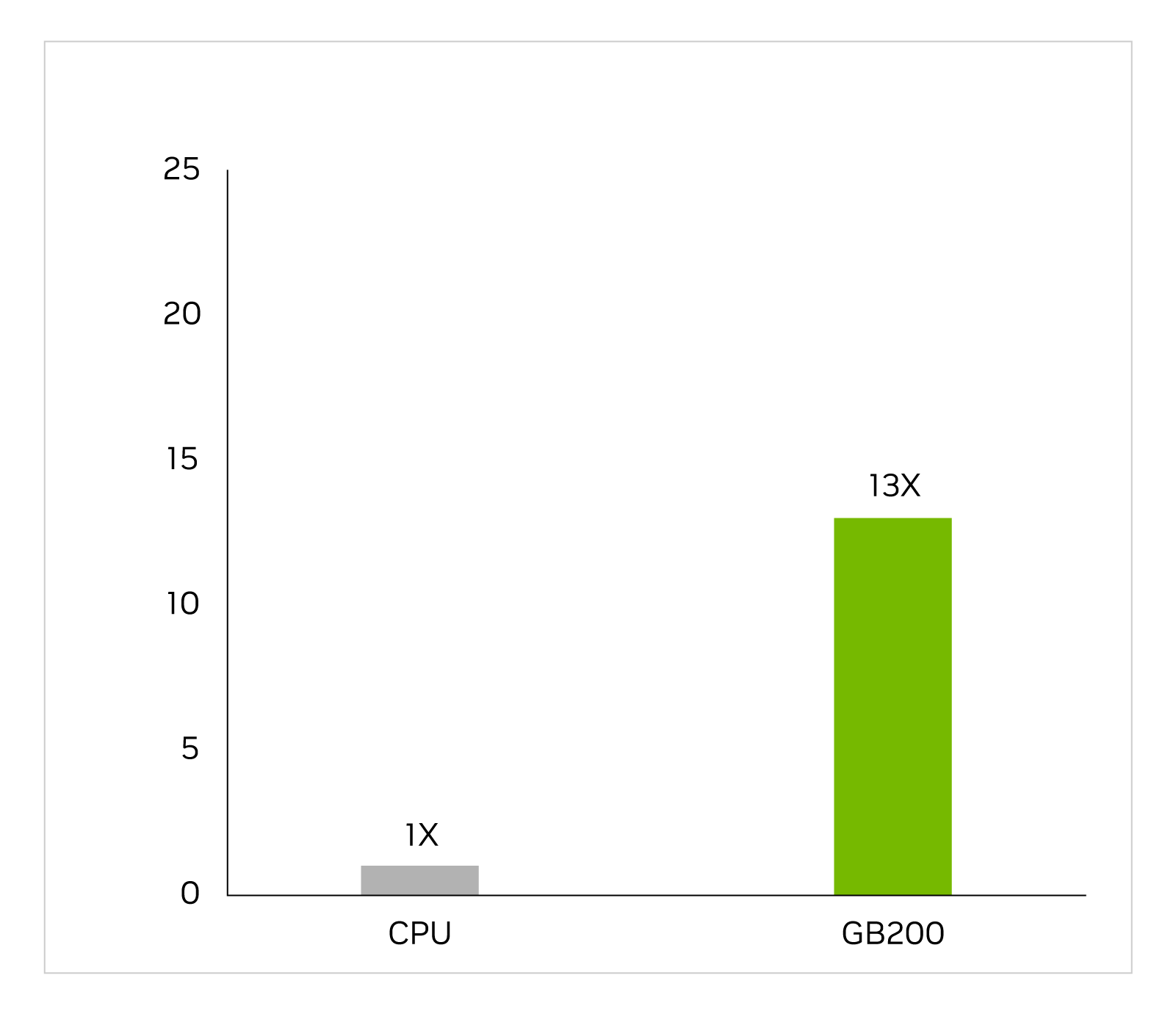
Cadence SpectreX (Spice 模拟器) | CPU:16 核 AMD Milan 75F3 数据集:KeithC Design TSMC N5 | GB200 的性能预测可能会发生变化
在过去两年中,该行业越来越多地将 GPU 加速的计算流体动力学 (CFD) 作为关键工具。工程师和设备设计师使用它来研究和预测其设计行为。Cadence Fidelity 是一个大型涡流模拟器 (LES),在 GB200 上运行模拟的速度比 x86 CPU 快 22 倍。
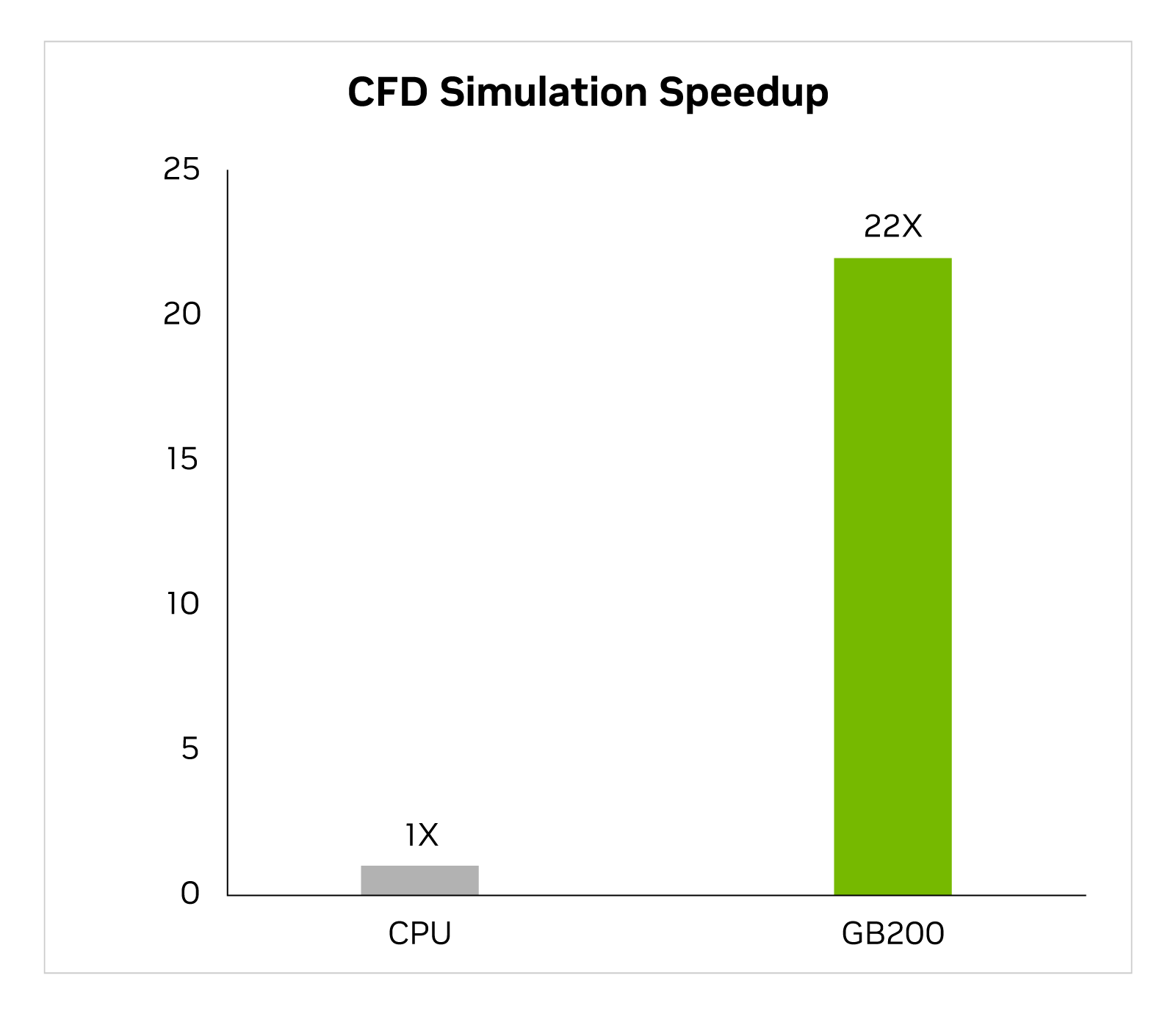
频率保真度 (LES CFD 求解器) | CPU:16 核 AMD Milan 75F3 数据集:GearPump 200 万单元 | GB200 的性能预测可能会发生变化
我们期待在 GB200 NVL72 上探索 Cadence Fidelity 的可能性。凭借并行可扩展性和每个机架 30 TB 的显存,我们的目标是捕获从未捕获过的流细节。
总结
回顾一下,我们回顾了 GB200 NVL72 机架级设计,并特别了解了其在单个 NVIDIA NVLink 域上连接 72 个 Blackwell GPU 的独特功能。这减少了在通过传统网络进行扩展时产生的通信开销。因此,可以对 1.8 T 参数 MoE LLM 进行实时推理,并且训练该模型的速度加快 4 倍。
72 块通过 NVLink 连接的 Blackwell GPU 在 130 TB/s 的计算结构上运行,具有 30 TB 的统一显存,可在单个机架中创建 exaFLOP 的 AI 超级计算机。它就是 NVIDIA GB200 NVL72。