介绍
高效的管道设计对数据科学家至关重要。在编写复杂的端到端工作流时,您可以从各种构建块中进行选择,每种构建块都专门用于特定任务。不幸的是,在数据格式之间重复转换容易出错,而且会降低性能。让我们改变这一点!
在本系列博客中,我们将讨论高效框架互操作性的不同方面:
- 在第一个职位中,我们讨论了不同内存布局以及异步内存分配的内存池的优缺点,以实现零拷贝功能。
- 在第二职位中,我们强调了数据加载/传输过程中出现的瓶颈,以及如何使用远程直接内存访问( RDMA )技术缓解这些瓶颈。
- 在本文中,我们将深入讨论端到端管道的实现,展示所讨论的跨数据科学框架的最佳数据传输技术。
要了解有关框架互操作性的更多信息,请查看我们在 NVIDIA 的 GTC 2021 年会议上的演示。
让我们深入了解以下方面的全功能管道的实现细节:
- 从普通 CSV 文件解析 20 小时连续测量的电子 CTR 心电图( ECG )。
- 使用传统信号处理技术将定制 ECG 流无监督分割为单个心跳。
- 用于异常检测的变分自动编码器( VAE )的后续培训。
- 结果的最终可视化。
对于前面的每个步骤,都使用了不同的数据科学库,因此高效的数据转换是一项至关重要的任务。最重要的是,在将数据从一个基于 GPU 的框架复制到另一个框架时,应该避免昂贵的 CPU 往返。
零拷贝操作:端到端管道
说够了!让我们看看框架的互操作性。在下面,我们将逐步讨论端到端管道。如果你是一个不耐烦的人,你可以直接在这里下载完整的 Jupyter 笔记本。源代码可以在最近的RAPIDS docker 容器中执行。
步骤 1 :数据加载
在第一步中,我们下载 20 小时的 ele CTR 心电图作为 CSV 文件,并将其写入磁盘(见单元格 1 )。之后,我们解析 CSV 文件中的 500 MB 标量值,并使用 RAPIDS “ blazing fast CSV reader ”(参见单元格 2 )将其直接传输到 GPU 。现在,数据驻留在 GPU 上,并将一直保留到最后。接下来,我们使用cuxfilter( ku 交叉滤波器)框架绘制由 2000 万个标量数据点组成的整个时间序列(见单元格 3 )。
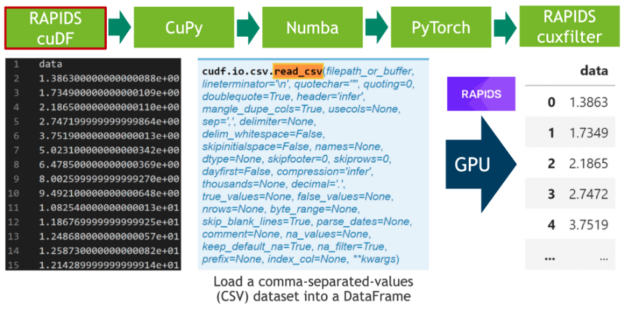
步骤 2 :数据分割
在下一步中,我们使用传统的信号处理技术将 20 小时的 ECG 分割成单个心跳。我们通过将 ECG 流与高斯分布的二阶导数(也称为里克尔小波)进行卷积来实现这一点,以便分离原型心跳中初始峰值的相应频带。使用 CuPy (一种 CUDA 加速的密集线性代数和阵列运算库)可以方便地进行小波采样和基于 FFT 的卷积运算。直接结果是,存储 ECG 数据的 RAPIDS cuDF 数据帧必须使用 DLPack 作为零拷贝机制转换为 CuPy 阵列。
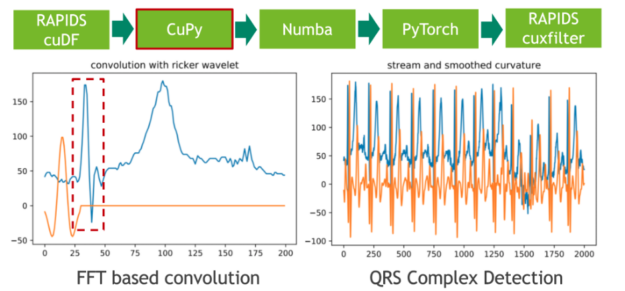
卷积的特征响应(结果)测量流中每个位置的固定频率内容的存在。请注意,我们选择小波的方式使局部最大值对应于心跳的初始峰值。
步骤 3 :局部极大值检测
在下一步中,我们使用非最大抑制( NMS )的 1D 变体将这些极值点映射到二进制门。 NMS 确定流中每个位置的对应值是否为预定义窗口(邻域)中的最大值。这个令人尴尬的并行问题的 CUDA 实现非常简单。在我们的示例中,我们使用即时编译器 Numba 实现无缝的 Python 集成。 Numba 和 Cupy 都将 CUDA 阵列接口实现为零拷贝机制,因此可以完全避免从 Cupy 阵列到 Numba 设备阵列的显式转换。
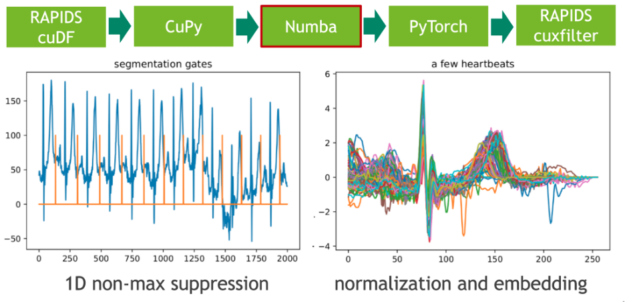
每个心跳的长度是通过计算门位置的相邻差分(有限阶导数)来确定的。我们通过使用谓词门== 1 过滤索引域,然后调用 cupy . diff ()来实现这一点。得到的直方图描述了长度分布。
步骤 4 :候选修剪和嵌入
我们打算使用固定长度的输入矩阵在心跳集上训练(卷积)变分自动编码器( VAE )。用 CUDA 内核可以实现心跳信号在零向量中的嵌入。在这里,我们再次使用 Numba 进行候选修剪和嵌入。
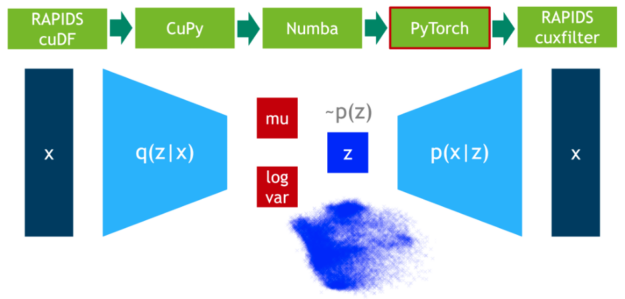
步骤 5 :异常值检测
在这一步中,我们在 75% 的数据上训练 VAE 模型。 DLPack 再次用作零拷贝机制,将 CuPy 数据矩阵映射到 PyTorch 张量。
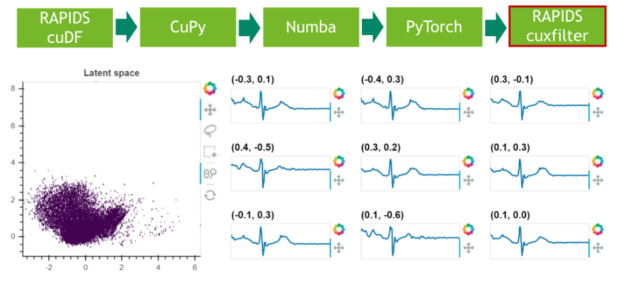
步骤 6 :结果可视化
在最后一步中,我们可视化剩余 25% 数据的潜在空间。
从这篇和前面的博文中可以看出,互操作性对于设计高效的数据管道至关重要。在不同的框架之间复制和转换数据是一项昂贵且极其耗时的任务,它为数据科学管道增加了零价值。数据科学工作负载变得越来越复杂,多个软件库之间的交互是常见的做法。 DLPack 和 CUDA 阵列接口是事实上的数据格式标准,保证了基于 GPU 的框架之间的零拷贝数据交换。
对外部内存管理器的支持是一个很好的特点,在评估您的管道将使用哪些软件库时要考虑。例如,如果您的任务同时需要数据帧和数组数据操作,那么最好选择 RAPIDS cuDF + CuPy 库。它们都受益于 GPU 加速,支持 DLPack 以零拷贝方式交换数据,并共享同一个内存管理器 RMM 。或者, RAPIDS cuDF + JAX 也是一个很好的选择。然而,后一种组合 或许需要额外的开发工作来利用内存使用,因为 JAX 缺乏对外部内存分配器的支持。
在处理大型数据集时,数据加载和数据传输瓶颈经常出现。 NVIDIA GPU 直接技术起到了解救作用,它支持将数据移入或移出 GPU 内存,而不会加重 CPU 的负担,并将不同节点上 GPU 之间传输数据时所需的数据副本数量减少到一个。