数据加载缓慢、内存消耗大的连接操作以及长时间运行的任务,是每位 Python 开发者都会面临的问题。它们不仅浪费了宝贵的时间,也让创意的迭代变得比实际所需更加困难。
本文将介绍五个常见的 pandas 性能瓶颈,以及如何识别这些问题。同时,文章会提供一些可在 CPU 上实施的优化方法,这些方法仅需对代码进行少量调整即可提升性能。此外,还将介绍基于 GPU 的即插即用加速工具 cudf.pandas,它无需修改代码,即可实现数量级的速度提升。
您的机器没有 GPU?不用担心,您可以免费使用 Google Colab 运行 cudf.pandas,因为 Colab 提供了 GPU,且该库已预先安装。
1.您的 read_csv() 调用是否需要很长时间?→ pd.read_csv(..., engine='pyarrow') 或 %load_ext cudf.panda
痛点:在分析开始前,pandas 解析 CSV 文件的速度较慢,可能导致工作流停滞,且在读取过程中 CPU 使用率会显著升高。
如何发现:大型 CSV 文件可能需要数秒甚至数分钟才能加载完成,在加载完成之前,笔记本电脑无法执行其他操作,表现为 I/O 受限。
CPU 修复: 使用更快的解析引擎,如 PyArrow。
pd.read_csv("data.csv", engine="pyarrow")
PyArrow 处理 CSV 的速度比 pandas 的默认解析器更快。其他优化方法包括:转换为 Parquet 或 Feather 格式以提升读取速度,仅加载所需列,或采用分块读取方式。
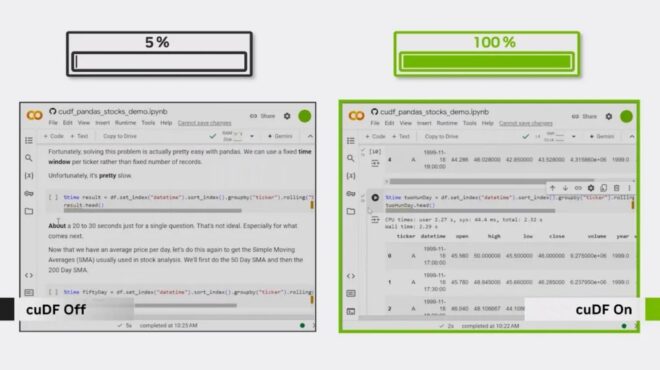
GPU 加速: 借助 NVIDIA cuDF 这一 pandas 加速器,CSV 文件可在数千个 GPU 线程中并行加载,将原本耗时数秒的读取操作变为近乎即时的加载,同时显著提升 CSV 和 Parquet 文件的写入效率,以及 Parquet 文件的读取速度。
%load_ext cudf.pandas
import pandas as pd
df = pd.read_csv("data.csv")
2.您的加入/合并操作是否会使笔记本电脑停止运行?→ df.merge(...)(GPU 加速)
痛点:在 pandas 中执行大规模连接或合并操作时,会显著增加 CPU 负载并占用大量内存,容易导致笔记本电脑卡顿甚至冻结,同时拖慢机器上其他任务的运行速度。
如何发现:RAM 使用率飙升、风扇加速转动,操作需要几秒或几分钟,尤其是在处理数千万行数据时。
CPU 修复:在可能的情况下使用索引联接,并在合并前删除不必要的列以减少数据移动。
# Drop unneeded columns first
df1 = df1[['id', 'value']]
df2 = df2[['id', 'category']]
# Set index if join key is unique
df1 = df1.set_index('id')
df2 = df2.set_index('id')
# Join on index
result = df1.join(df2)
GPU 加速: 在导入 pandas 之前加载 cudf.pandas 扩展,即可利用数千个 GPU 线程并行执行连接操作,显著提升大型数据集的处理速度,且无需修改其余代码:massive speedups
%load_ext cudf.pandas
import pandas as pd
df = pd.merge(df1, df2, on="id")
参考笔记本电脑:在 Colab 中打开 | 查看 GitHub 上的资料
3.您的字符串密集型数据集是否会使笔记本电脑崩溃?→ df['col'] = df['col'].astype('category') 或 cuDF 字符串操作
痛点:宽对象或字符串列(尤其是包含数百万字符的列)会占用大量内存,并显著拖慢下游操作的执行速度。其中,高基数列(即具有大量唯一值的列)是造成这一问题的主要原因。
如何发现:当数据框包含大量对象类型的列时,其内存占用可能膨胀至 GB 级别;此时,诸如 .str.len()、.str.contains() 或基于字符串键的合并等简单操作,都可能变得异常缓慢,甚至引发内存不足错误。
CPU 修复: 针对低基数的字符串列,将其转换为类别类型以显著节省内存;而对于真正的高基数列,则保持其字符串类型,因为在此类情况下使用分类变量效果有限。
# quick heuristic: convert strings with few uniques to category
for col in df.select_dtypes(include="object"):
nunique = df[col].nunique(dropna=False)
if nunique and nunique / len(df) < 0.05: # tune threshold per dataset
df[col] = df[col].astype("category")
其他 CPU 技巧:
- 确保一致的字体大小写和修剪空白字符(隐藏空格或大小写字母差异)。例如,(“A
pple” vs “apple” vs “APPLE”)——创建单独的值。 - 预先标记或规范化 ID 以缩短字符串,将基于文本的 ID(如“
user_00012345_2023”)替换为较短的标记(如“u12345”),以减少内存使用并加快比较速度。
GPU 加速修复: cuDF 利用 GPU 优化内核来加速字符串操作,使得 .str 方法(如 len()、contains() 以及基于字符串键的连接操作)即使在导致 CPU 僵局的高基数列上,也能以交互级速度运行。您只需更改 %load_ext cudf.pandas 即可。
%load_ext cudf.pandas
import pandas as pd
# same pandas code, now accelerated on GPU:
df = pd.read_csv("job_summary.csv", dtype=str)
df['summary_length'] = df['job_summary'].str.len()
以下是参考笔记本,展示了在 8 GB 大规模字符串数据上如何使用 cuDF 加速典型的 pandas 工作流,包括数据读取、连接和字符串处理等操作。您可以通过实际示例直观地看到性能提升效果:在 Colab 中打开 | 查看 GitHub 上的源码
4.您的 groupby 速度是否很慢?→ df.groupby(...).agg(...)(GPU 加速)
痛点:对大型数据集执行 GroupBy 操作(尤其是使用多个分组键或高成本的聚合函数)容易造成 CPU 占用过高,导致数据探索速度变慢,严重影响分析迭代的效率。
如何发现:该操作会占用 CPU 核心(若启用并行化,则可能占满所有核心),RAM 使用率会出现明显波动,且在 pandas 逐个处理分组时,进度往往显得停滞不前。
CPU 优化:在聚合前,可通过删除未使用的列、提前过滤行或预先计算更简单的特征来减小分组数据集的大小。建议使用 observed=True 作为分类键,以跳过不必要的分类组合。
# Filter before grouping
df_filtered = df[df['status'] == 'active']
# Group and aggregate
result = df_filtered.groupby('category', observed=True)['value'].mean()
GPU 加速修复:cuDF 作为 pandas 的 GPU 加速器,能够将 groupby 操作分配到数千个 GPU 线程上,实现对数百万个组的并行处理。只需启用 %load_ext cudf.pandas 并保持原有的 pandas 代码不变,即可在几毫秒内完成原本在 CPU 上需要数分钟才能完成的大规模聚合任务。
%load_ext cudf.pandas
import pandas as pd
result = df.groupby('category', observed=True)['value'].mean()
参考笔记本:使用 cuDF 这一基于 GPU 的 pandas 加速器,仅需几毫秒即可对 2500 万条纽约市违规停车记录按位置进行分组。无需修改 pandas 代码,直接在 GPU 上运行即可实现性能飞跃。 在 Colab 中打开 | 查看 GitHub 上的项目
5.大型数据集内存不足?→ df[col] = df[col].astype('category') 或在 GPU 上使用统一虚拟内存
痛点:数据集过大,无法完全载入CPU内存,导致内存溢出错误,或迫使用户只能使用小样本而非完整数据。
如何发现:当 Python 出现 MemoryError 导致程序崩溃、笔记本内核重启,或无法在不进行磁盘交换的情况下加载完整数据集时,即可能存在内存不足的问题。
CPU 修复: 通过向下转换数值类型并将低基数字符串列转换为类别来减少内存占用。
# Downcast numeric types
df['int_col'] = pd.to_numeric(df['int_col'], downcast='integer')
df['float_col'] = pd.to_numeric(df['float_col'], downcast='float')
# Convert low-cardinality strings
df['state'] = df['state'].astype('category')
您还可以尝试使用 nrows 参数仅加载数据集的一个子集,以便在不将全部数据载入内存的情况下快速进行检查或原型开发。但需注意,如果样本缺乏代表性,可能会遗漏边缘情况,导致分析结果出现偏差。
GPU 修复:cudf.pandas 扩展通过统一虚拟内存(UVM)将 GPU 显存与 CPU 内存合并为一个统一的内存池,使您能够处理超出 GPU 显存容量的数据集。数据会在 GPU 显存与系统内存之间自动分页,让您充分利用全部系统内存,同时享受 GPU 加速带来的高性能。
此视频将向您介绍如何使用此功能:
结论:保持工作流的流畅运行
首先在 CPU 上进行快速优化,以消除最常见的性能瓶颈。如果仍存在性能问题,可进一步利用 GPU 加速,且无需重写代码。您甚至可以通过预装了所有相关库的 Google Colab 免费使用 GPU。只需插入代码,即可见证其飞速运行。
使用 Polars?→ 使用 Polars GPU 引擎即时加速它
使用 Polars 应对 DataFrame 性能挑战?由 NVIDIA cuDF 提供支持的 Polars GPU 引擎 可在连接、分组、聚合和 I/O 操作中实现类似级别的即插即用加速,且无需修改现有的 Polars 查询代码,即可获得数量级的性能提升。
要深入了解这些及其他即插即用的 GPU 加速器,请参加这门免费课程:加速数据科学工作流,无需更改代码。