这篇文章,旨在为具有深入学习专业水平的开发人员准备,将帮助您生成一个准备生产、人工智能、文本到语音的模型。
几十年来,将文本实时转换为高质量、自然发音的语音一直是一项具有挑战性的任务。最先进的语音合成模型是基于参数神经网络 1 。文本到语音( TTS )合成通常分两步完成。
- 第一步将文本转换成时间对齐的特征,如 mel-spe CTR 图或 F0 频率等语言特征;
- 第二步将时间对齐的功能转换为音频。
优化的 Tacotron2 模型 2 和新的 WaveGlow 模型 1 利用 NVIDIA Volta 上的 张量核 和图灵 GPUs 将文本实时转换为高质量的自然发音语音。生成的音频具有清晰的人声,没有背景噪音。
下面是一个使用此模型可以实现的示例:
输入:
“ 威廉·莎士比亚是英国诗人、剧作家和演员,被公认为英语中最伟大的作家和世界上最伟大的剧作家。他常被称为英国的民族诗人和‘雅芳吟游诗人’。”
输出:
在遵循 Jupyter 笔记本 中的步骤之后,您将能够为模型提供英语文本,并且它将生成一个音频输出文件。所有重现结果的脚本都发布在我们的 NVIDIA 深度学习示例 存储库的 GitHub 上,其中包含几个使用张量核心的高性能培训配方。此外,我们还开发了一个 Jupyter 笔记本 ,供用户创建自己的容器映像,然后下载数据集,逐步重现训练和推理结果。
模型
我们的 TTS 系统是两个神经网络模型的组合:
- 从“ 基于 Mel-Spe CTR 图预测的条件波网自然合成 TTS ”改进的 Tacotron 2 (图 1 )模型;
- 来自“ WaveGlow :一种基于流的语音合成生成网络 ”的基于流的神经网络模型。
Tacotron 2 和 WaveGlow 模型构成了一个 TTS 系统,用户可以在没有任何附加韵律信息的情况下从原始文本合成自然发音的语音。
Tacotron 2 型号
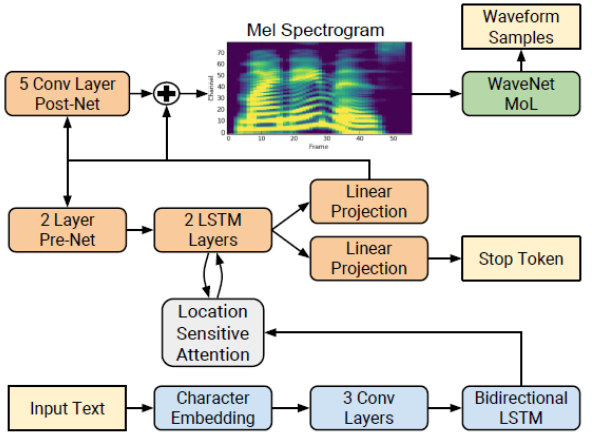
Tacotron 2 2 是一种直接从文本合成语音的神经网络结构。该系统由一个递归的序列到序列特征预测网络组成,该网络将字符嵌入映射到 mel 尺度的 spe CTR 图,然后由一个改进的 WaveNet 模型作为声码器,从这些 spe CTR 图合成时域波形,如图 1 所示。
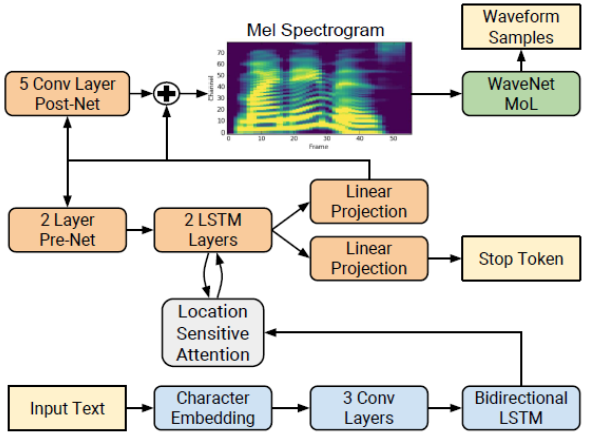
网络由一个编码器(蓝色)和一个解码器(橙色)组成。编码器将一个字符序列转换成一个隐藏的特征表示,作为解码器的输入来预测 spe CTR 图。输入文本(黄色)是使用学习的 512 维字符嵌入来呈现的,它通过三个卷积层(每个包含 512 个形状为 5 × 1 的滤波器)的堆栈,然后进行批量规范化和 ReLU 激活。编码器输出被传递到注意力网络( gray ),该网络将完整编码序列总结为每个解码器输出步骤的固定长度上下文向量。
解码器是一个自回归递归神经网络,它从编码的输入序列中一次一帧地预测 mel-spe CTR 图。前一个时间步的预测首先通过一个包含两个完全连接的 256 个隐藏 ReLU 单元的层的小 pre 网络。 prenet 输出和注意力上下文向量被连接起来,并传递到一个由两个 LSTM 层组成的堆栈,其中包含 1024 个单元。通过线性变换,将 LSTM 输出与注意上下文向量的连接进行投影,以预测目标 spe CTR 图帧。最后,将预测的 mel-spe CTR 图通过一个 5 层卷积后网络,该网络预测一个残差来加入预测,以改善整体重建。每个 post-net 层由 512 个形状为 5 × 1 的过滤器组成,并进行批量标准化处理,除最后一层外,所有过滤器均激活。
我们实现的 Tacotron 2 模型与 1 中描述的模型不同,我们使用:
- 退出而不是分区,以使 LSTM 层正则化;
- 用 WaveGlow 模型 2 代替 WaveNet 来合成波形。
WaveGlow 模型
WaveGlow 1 是一种基于流的网络,能够从 mel-spe CTR 图生成高质量的语音。 WaveGlow 结合了 Glow 5 和 WaveNet 6 的见解,以提供快速、高效和高质量的音频合成,而无需自动回归。 WaveGlow 只使用一个网络实现,只使用一个单一的成本函数进行训练:使训练过程简单而稳定。我们当前的模型以 55 * 22050 = 1212750 的速度合成样本,这比每秒 22050 个样本的“实时”要快 55 倍。平均意见得分( MOS )表明,它提供的音频质量与在同一数据集上训练的最佳公开可用 WaveNet 实现一样好。
WaveGlow 是一种生成模型,它通过从分布中采样来生成音频。为了使用神经网络作为生成模型,我们从一个简单的分布中提取样本,在我们的例子中,是一个零均值的球面高斯分布,其维数与我们期望的输出相同,然后将这些样本通过一系列层将简单分布转换为具有期望分布的分布。在这种情况下,我们根据 mel-spe CTR 图对音频样本的分布进行建模。
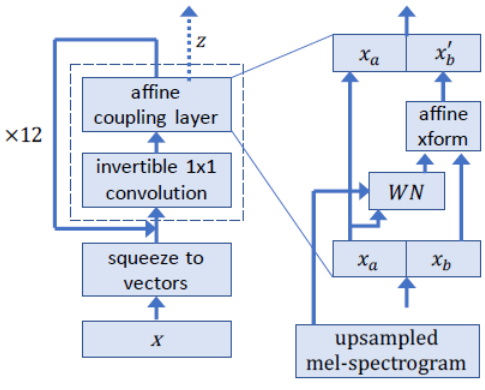
如图 2 所示,对于通过网络的前向传递,我们将八个音频样本组作为向量,“压缩”操作,如 Glow 5 所示。然后我们通过几个“流程步骤”处理这些向量。这里的流动步骤由可逆的 1 × 1 卷积和仿射耦合层组成。在仿射耦合层中,一半的信道作为输入,然后产生乘法和加法项,用于缩放和平移剩余的信道。
启用自动混合精度
混合精度 通过以半精度格式执行操作,同时以单精度( FP32 )存储最少的信息,从而在网络的关键部分尽可能多地保留信息,从而显著提高了计算速度。启用混合精度利用了 Volta 和 Turing GPUs 上的 张量核 ,在训练时间上提供了显著的加速——在运算最密集的模型架构上,整体加速高达 3 倍。
使用 混合精度训练 之前需要两个步骤:
- 在适当的情况下移植模型以使用 FP16 数据类型;
- 手动添加损耗缩放以保持较小的渐变值。
通过使用 PyTorch 中的自动混合精度( AMP )库, APEX 中启用了混合精度,该库在检索时将变量强制转换为半精度,同时以单精度格式存储变量。为了在反向传播中保持较小的梯度值,应用渐变时必须包含 损耗标度 步骤。在 PyTorch 中,通过使用 AMP 提供的 scale _ loss ()方法,可以很容易地应用损耗缩放。要使用的缩放值可以是 dynamic 或 fixed 。
通过在训练脚本中添加– amp run 标志,可以启用张量核心的混合精度训练,您可以在我们的 Jupyter 笔记本 中看到示例。
培训业绩
表 1 和表 2 比较了采用 PyTorch -19 . 06-py3 NGC 容器 在带有 8-V100 16GB GPUs 的 NVIDIA DGX-1 上使用改进的 Tacotron 2 和 WaveGlow 模型的训练性能。在整个训练周期内,平均性能数( Tacotron 2 的输出 mel spe CTR 图每秒, WaveGlow 每秒输出样本数)。
| Number of GPUs | Mixed Precision mels/sec | FP32 mels/sec | Speed-up with Mixed Precision | Multi-GPU Weak Scaling with Mixed Precision | Multi-GPU Weak Scaling with FP32 |
| 1 | 20,992 | 12,933 | 1.62 | 1.00 | 1.00 |
| 4 | 74,989 | 46,115 | 1.63 | 3.57 | 3.57 |
| 8 | 140,060 | 88,719 | 1.58 | 6.67 | 6.86 |
表 2 : WaveGlow 模型的训练性能结果
如表 1 和表 2 所示,使用张量核进行混合精度训练可以实现显著的加速,并且可以有效地扩展到 4 / 8 GPUs 。混合精度训练也保持了与单精度训练相同的精度,并允许更大的批量。语音质量取决于模型大小和训练集大小;使用具有自动混合精度的张量核,可以在相同的时间内训练出质量更高的模型。
考虑到高质量所需的模型大小和培训量, GPUs 提供了一个最合适的硬件架构,并将吞吐量、带宽、可伸缩性和易用性进行了最佳组合。
推理性能
表 3 和表 4 分别显示了从 1-V100 和 1-T4 GPU 上的 1000 次推理运行中收集的 Tacotron2 和 WaveGlow 文本到语音系统的推理统计数据。从 Tacotron2 推断开始到 WaveGlow 推断结束,测量潜伏期。这些表包括平均延迟、标准偏差和延迟置信区间(百分比值)。吞吐量是以每秒生成的音频样本数来衡量的。 RTF 是一个实时因子,它告诉我们在 1 秒钟的壁时间内产生了多少秒的语音。
| Batch size | Input Length | Precision | Avg Latency (s) | Std Latency (s) | Latency Confidence Interval 50% (s) | Latency Confidence Interval 100% (s) | Throughput (samples/sec) | Avg Mels Generated (81 mels=1 sec of speech) | Avg Audio Length (s) | Avg RTF |
| 1 | 128 | Mixed Precision | 1.73 | 0.07 | 1.72 | 2.11 | 89,162 | 601 | 6.98 | 4.04 |
| 4 | 128 | Mixed Precision | 4.21 | 0.17 | 4.19 | 4.84 | 145,800 | 600 | 6.97 | 1.65 |
| 1 | 128 | FP32 | 1.85 | 0.06 | 1.84 | 2.19 | 81,868 | 590 | 6.85 | 3.71 |
| 4 | 128 | FP32 | 4.80 | 0.15 | 4.79 | 5.43 | 125,930 | 590 | 6.85 | 1.43 |
表 3 : 1-V100 GPU 上 Tacotron2 和 WaveGlow 系统的推断统计
与 FP32 相比,我们可以看到混合精度推理具有较低的平均延迟和延迟置信区间(百分比值),同时实现更高的吞吐量并生成更长的平均 RTF ( 1 秒壁时间内的语音秒数)。
| Batch size | Input Length | Precision | Avg Latency (s) | Std Latency (s) | Latency Confidence Interval 50% (s) | Latency Confidence Interval 100% (s) | Throughput (samples/sec) | Avg Mels Generated (81 mels=1 sec of speech) | Avg Audio Length (s) | Avg RTF |
| 1 | 128 | Mixed Precision | 3.16 | 0.13 | 3.16 | 3.81 | 48,792 | 603 | 7.00 | 2.21 |
| 4 | 128 | Mixed Precision | 11.45 | 0.49 | 11.39 | 14.38 | 53,771 | 601 | 6.98 | 0.61 |
| 1 | 128 | FP32 | 3.82 | 0.11 | 3.81 | 4.24 | 39,603 | 591 | 6.86 | 1.80 |
| 4 | 128 | FP32 | 13.80 | 0.45 | 13.74 | 16.09 | 43,915 | 592 | 6.87 | 0.50 |
表 4 : 1-T4 GPU 上 Tacotron2 和 WaveGlow 系统的推断统计
一步一步运行 Jupyter 笔记本
为了达到上述结果:
- 按照 GitHub 上的脚本操作或逐步运行 Jupyter 笔记本 来训练 Tacotron 2 和 WaveGlow v1 . 5 模型。在 Jupyter 笔记本 中,我们提供了完全自动化的脚本来下载和预处理 LJ 语音数据集 ;
- 数据准备步骤完成后,使用提供的 Dockerfile 构建修改后的 Tacotron 2 和 WaveGlow 容器,并在容器中启动一个分离的会话;
- 要使用带张量核心的 AMP 或使用 FP32 训练我们的模型,请使用 Tacrotron 2 的默认参数和使用单个 GPU 或多个 GPUs 的 WaveGlow 模型执行训练步骤。
Training
Tacotron2 和 WaveGlow 模型分别独立地进行训练,两个模型在训练过程中通过短时傅立叶变换( STFT )得到 mel-spe CTR 图。这些 mel-spe CTR 图用于 Tacotron 2 情况下的损耗计算,以及在波辉光的情况下作为网络的调节输入。
整个验证数据集的平均损失是训练损失的平均值。对于 Tacotron 2 模型,性能是以每秒的总输入令牌数来报告的,而对于 WaveGlow 模型,则是以每秒的总输出样本数来报告的。在输出日志中,这两个度量值都被记录为 train _ iter _ items / sec (每次迭代后)和 train _ epoch _ items / sec (在 epoch 上的平均值)。结果在整个训练周期内取平均值,并在训练中包含的所有 GPUs 上求和。
默认情况下,我们的训练脚本将使用张量 cCores 启动混合精度训练。您可以通过删除– fp16 run 标志来更改此行为。
Inference
在训练了 Tacotron 2 和 WaveGlow 模型,或者下载了各自模型的预先训练的检查点之后,您可以执行以文本为输入的推理,并生成一个音频文件。
您可以根据文本文件的长度自定义文本文件的内容,可能需要将– max decoder steps 选项增加到 2000 。 Tacotron 2 模型是在 LJ 语音数据集 上训练的,音频样本不超过 10 秒,相当于 860 个 mel spe CTR 图。因此,这种推断在生成相似长度的音频样本时可以很好地工作。我们将 mel-spe CTR 图长度限制设置为 2000 (约 23 秒),因为实际上它仍然可以生成正确的声音。如果需要,用户可以将较长的短语分成多个句子,并分别合成它们。
下一步
在阅读了这个博客之后,可以尝试使用 Jupyter 笔记本 来获得从文本实时生成音频的实际体验。
References:
- [Prenger et al 2018][ WaveGlow :一种基于流的语音合成生成网络 ” Ryan Prenger , Rafael Valle , Bryan Catanzaro
- [Shen 等人 2018 年]“ Mel Spe CTR 谱预测条件下的天然 TTS 合成 ”, Jonathan Shen , Ruming Pang , Ron J . Weiss , Mike Schuster , Navdeep Jaitly , Zhongheng Yang , Zhifeng Chen , Yu Zhang , Yuxuan Wang , RJ Skerry Ryan , Rif A . Saurus , Yannis Agimyrgiannakis ,和 Yonghui Wu
- Tacotron2 和 WaveGlow Jupyter 笔记本
- PyTorch 存储库的 Tacotron2 和 WaveGlow v1 . 7
- [Kingma 等人 2018 年]“ 辉光:具有可逆 1 × 1 卷积的生成流 ” Diederik P Kingma 和 Prafulla Dhariwal
- [Van den Oord 等人 2016 年]“ WaveNet :原始音频的生成模型 ”亚伦·范登诺德、桑德·迪勒曼、海加·岑、凯伦·西蒙扬、奥利奥·维尼尔斯、亚历克斯·格雷夫斯、纳尔·卡尔什布伦纳、安德鲁·塞奥鲁和科雷·卡武库格鲁