新冠肺炎疫情引起了公众对基于代理的建模与仿真( ABMS )的关注。它是研究行为的一种强大的计算技术,无论是流行病学、生物学、社会学还是其他方面。该过程在概念上很简单:
- 描述了个人的行为(模型)。
- 提供了模型的输入。
- 对许多相互作用的个体(或代理)的模拟使复杂的系统级行为得以自然出现。
这里有一个经典的例子:羊群、学校和牛群的行为。通过与群体保持紧密联系(凝聚力)、避免冲突(分离)和匹配邻居的速度(对齐)等相对简单的行为,可以观察到美丽的涌现模式。
FLAME GPU 是用于模拟复杂系统的开源软件。它是独立于领域的,可以用于任何使用基于代理的建模思想的模拟。描述个体行为和观察紧急输出的基于代理的建模方法使 FLAME GPU 能够用于植绒、细胞生物学和运输等示例。
以下视频显示了 FLAME GPU 软件输出的植绒示例。
视频 1 。 FLAME GPU 基于 GPU 上 100K 代理的 Boids 模拟
无论给定模拟的主题如何,使用 ABMS 来模拟大量代理可能会产生显著的计算成本。通常,此类模拟器被设计用于 CPU 架构上的顺序执行,导致解决问题的时间极其缓慢,并限制了模拟模型的可行规模。
GPU ( FLAME GPU )库的灵活大规模代理建模环境使您能够利用 GPU 并行性的强大功能,显著提高 ABMS 的计算性能和规模。该软件速度极快,因此可以扩展到 NVIDIA A100 和 NVIDIA H100 上的数亿代理 GPU 。
FLAME GPU 简介
新的 FLAME GPU 软件通过为模型和代理行为规范提供直观的界面,抽象了在 GPU 上执行基于代理的模型的复杂性。该软件通过提供一个抽象底层实现的许多复杂性的 API 来实现这一点。
例如,所有技术考虑都是透明处理的,以确保 GPU 上的出色执行性能。这可能包括空间数据结构的构建、 CUDA 内核执行的调度或内存中同质密集代理阵列的分组。
FLAME GPU 软件用 CUDA C ++编写,以在 NVIDIA GPU 上执行模拟。谢菲尔德大学的一个研究软件工程师团队已经开发了大约 5 年的版本 2 。它通过使用 C ++和 CUDA 的现代功能,构建并取代了该软件的传统 C 版本。我们通过他们的学术加速器和黑客马拉松程序帮助优化了 NVIDIA 的代码。
FLAME GPU 还有一个 Python 库(pyflamegpu),它允许您在 Python 中本地指定模型。这包括代理行为,它是使用 Jitify 和 NVRTC 在运行时转换和编译的。有关使用库的更多信息,请参见 Creating the Circles Model 。
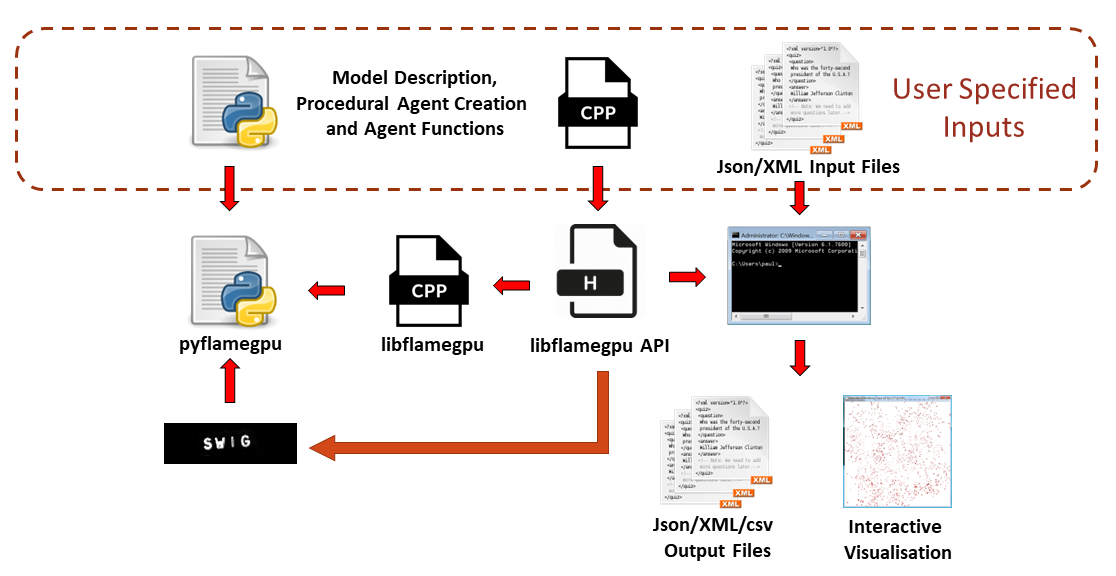
图 1 显示了使用 FLAME GPU 库构建模型的过程。本文将介绍 C ++中模型描述的规范。
代理行为
FLAME GPU 软件可以被认为是更复杂、通用的粒子模拟版本,如 CUDA 示例中提供的。它支持多种任意的、用户定义的、粒子或代理类型,在代理之间交换信息,并完全控制代理行为的设计。
代理行为由 agent function 指定,它充当流进程。代理的实例可以更新其内部状态变量以及可选地输出或输入消息数据。
消息是存储在列表中的状态变量的集合,有助于代理之间的信息间接通信。向代理函数输入消息数据是通过遍历消息数据的 C ++迭代器实现的。不同的消息传递类型以不同的方式实现迭代器,但从用户和模型抽象存储、数据结构和迭代机制。
下面的示例演示了一个简单的用户定义代理函数 output _ message ,它需要三个参数,分别表示函数名、输入和输出消息类型。
在该示例中,输出MessageSpatial2D类型的消息,该消息存在于连续空间 2D 环境中。单例对象FLAMEGPU用于使用getVariable检索特定类型的命名变量,并使用message_out.setVariable将这些变量作为消息输出到消息列表。
FLAMEGPU_AGENT_FUNCTION(output_message, flamegpu::MessageNone, flamegpu::MessageSpatial2D) {
FLAMEGPU->message_out.setVariable<int>("id", FLAMEGPU->getID());
FLAMEGPU->message_out.setLocation(
FLAMEGPU->getVariable<float>("x"),
FLAMEGPU->getVariable<float>("y"));
return flamegpu::ALIVE;
}
然后可以指定一个更复杂的代理函数来描述处理output_message输出的消息的代理的行为。在下面的代码示例中描述的 input _ message 中,消息循环迭代器遍历任何空间数据结构以返回候选消息。
给定MessageSpatial2D消息作为输入,候选消息由距离确定。这种代理的行为是施加排斥力,这取决于邻居的位置。排斥因子由环境变量控制;即对模型中的所有代理都是只读的变量。
FLAMEGPU_AGENT_FUNCTION(input_message, flamegpu::MessageSpatial2D, flamegpu::MessageNone) {
const flamegpu::id_t ID = FLAMEGPU->getID();
const float REPULSE_FACTOR =
FLAMEGPU->environment.getProperty<float>("repulse");
const float RADIUS = FLAMEGPU->message_in.radius();
float fx = 0.0;
float fy = 0.0;
const float x1 = FLAMEGPU->getVariable<float>("x");
const float y1 = FLAMEGPU->getVariable<float>("y");
int count = 0;
// message loop iterator
for (const auto &message : FLAMEGPU->message_in(x1, y1)) {
if (message.getVariable<flamegpu::id_t>("id") != ID) {
const float x2 = message.getVariable<float>("x");
const float y2 = message.getVariable<float>("y");
float x21 = x2 - x1;
float y21 = y2 - y1;
const float separation = sqrt(x21*x21 + y21*y21);
if (separation < RADIUS && separation > 0.0f) {
float k = sinf((separation / RADIUS)*3.141f*-2)*REPULSE_FACTOR;
// Normalize without recalculating separation
x21 /= separation;
y21 /= separation;
fx += k * x21;
fy += k * y21;
count++;
}
}
}
fx /= count > 0 ? count : 1;
fy /= count > 0 ? count : 1;
FLAMEGPU->setVariable<float>("x", x1 + fx);
FLAMEGPU->setVariable<float>("y", y1 + fy);
FLAMEGPU->setVariable<float>("drift", sqrt(fx*fx + fy*fy));
return flamegpu::ALIVE;
}
这里描述的代理函数定义了基于代理的系统的行为规范的完整示例,我们称之为 circles 模型。这种行为类似于粒子系统、群体或群体,甚至是简单的细胞生物学模型。
尽管由于所使用的抽象机制,这两个代理函数并不明显,但示例中的两个代理功能都编译为 CUDA 设备代码。
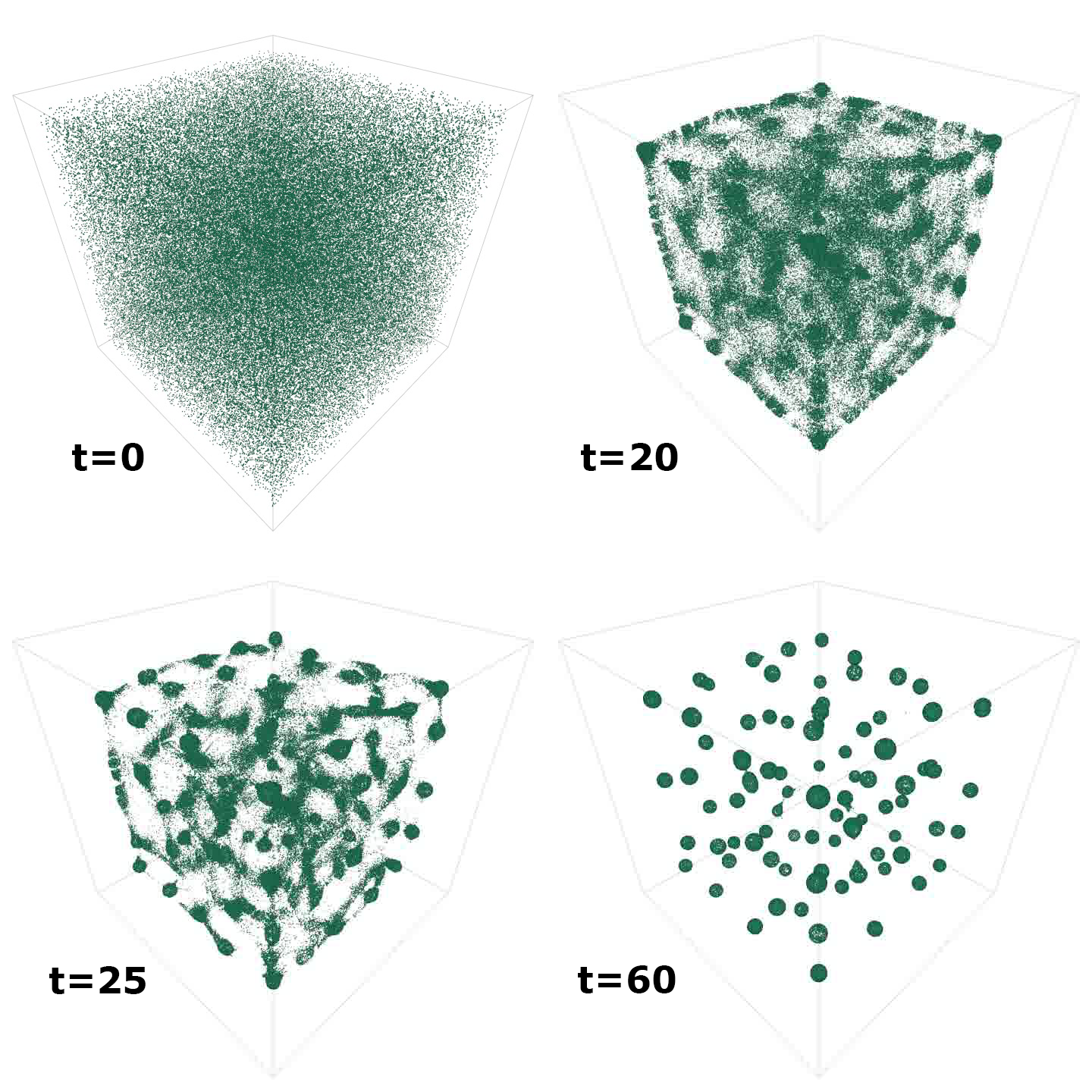
图 2 显示了随着时间的推移(但扩展到 3D )模拟时该模型的紧急输出。可视化由内置 FLAME GPU 可视化工具的屏幕截图生成。
描述模型
FLAME GPU 软件最重要的特征之一是基于状态的代理表示,其中状态只是一种对代理进行分组的方法。对于流行病学模型,药剂可能处于易感、暴露、感染或恢复( SEIR )状态。在生物模型中,细胞因子可能处于细胞周期的不同阶段。代理的状态可能决定代理执行的行为。
在 FLAME GPU 中,代理可以具有多个状态,并且代理函数仅应用于处于特定状态的代理。状态的使用确保了在模型中可以发生不同的、异构的行为,避免了高度分散的代码执行。简单地说,代理与执行相同行为的其他代理分组。
模型,例如本示例中的圆模型,可以具有单个(默认)状态,但是,复杂模型可能具有多个。国家在确定职能的执行顺序方面也发挥着重要作用。通过函数中的消息使用,代理状态之间发生间接通信。
可以通过依赖性分析从程序上确定代理和功能之间的依赖性。结果是一个有向无环图( DAG ),它表示模型的一次迭代中所有代理的行为。
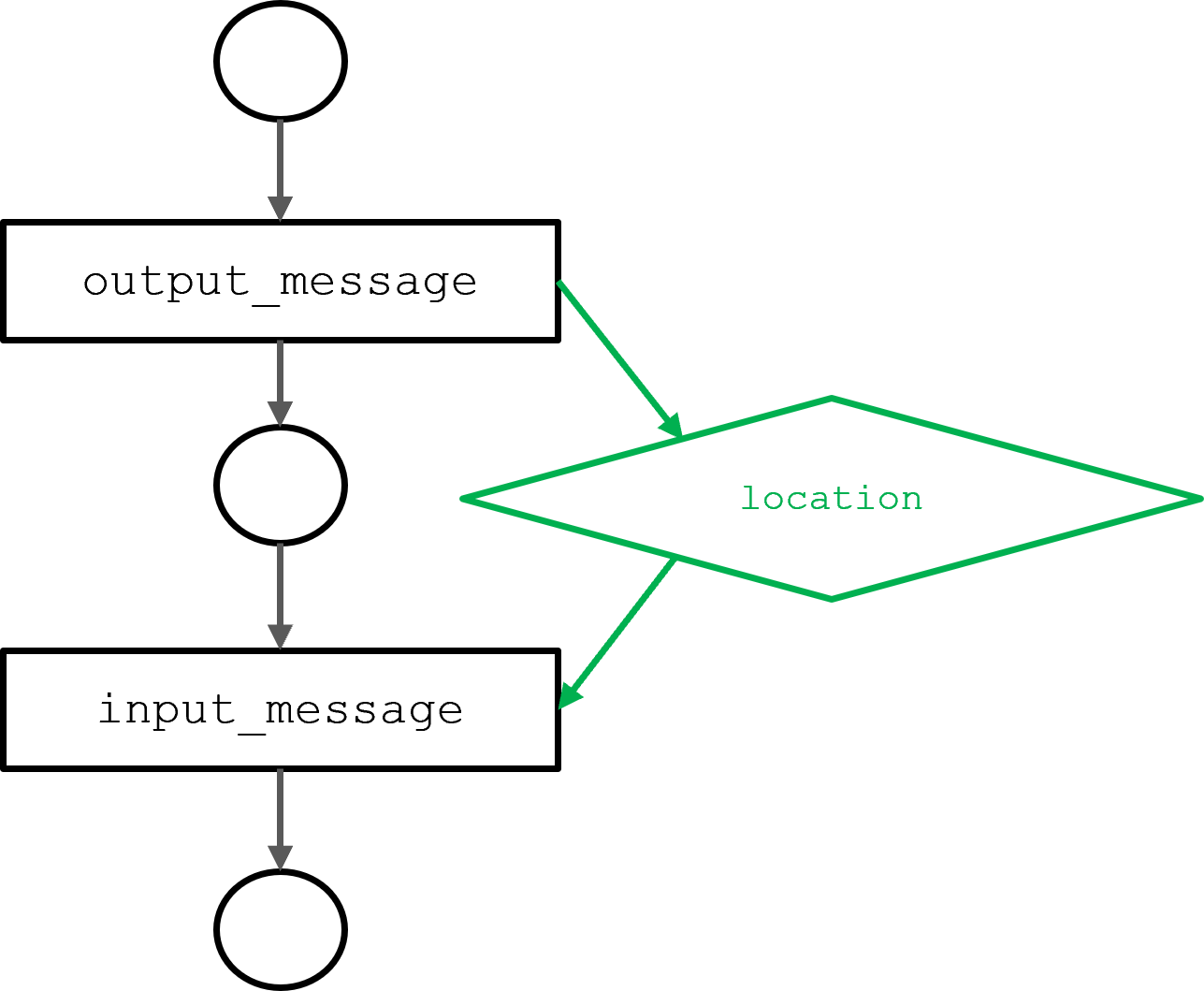
图 3 显示了由上一节中描述的 output _ message 和 input _ message 代理函数生成的圆圈模型的 DAG 。input_message功能取决于output_message功能输出的位置信息。依赖关系决定执行顺序。
FLAME GPU 模型的完整状态描述使用 FLAME GPU API 定义(图 4 )。ModelDescription对象充当所描述模型的根,其描述如下:
// Define the FLAME GPU model
flamegpu::ModelDescription model("Circles Tutorial");
所有其他 API 对象都是ModelDescription对象的同级对象。在下面的示例中,(“ circle ”)代理由三个变量定义,其中每个变量都有一个特定的字符串名称和一个显式类型。变量名称和类型与在代理函数中获得的名称和类型相匹配:
// Define an agent named point
flamegpu::AgentDescription agent = model.newAgent("circle");
// Assign the agent some variables (ID is implicit to agents, so we don't define it ourselves)
agent.newVariable<float>("x");
agent.newVariable<float>("y");
agent.newVariable<float>("drift", 0.0f);
与代理一样,消息包含许多变量。例如,此处定义的消息具有一个变量,用于存储其源代理的 ID 。消息也有一个特殊性,表明它们是如何存储和迭代的。
在下一个示例中,消息被描述为type flamegpu::MessageSpatial2D。重要的是,此类型与前面代理函数的输入和输出类型相匹配。由于消息类型是 2D 空间的,消息隐式地包括坐标变量x和y。
消息类型还需要定义环境大小(消息存在的边界)和空间半径。空间半径确定消息返回到查询消息列表的代理的范围。
// Define a message of type MessageSpatial2D named location
flamegpu::MessageSpatial2D::Description message =
model.newMessage<flamegpu::MessageSpatial2D>("location");
// Configure the message list
message.setMin(0, 0);
message.setMax(ENV_WIDTH, ENV_WIDTH);
message.setRadius(1.0f);
// Add extra variables to the message
// X Y (Z) are implicit for spatial messages
message.newVariable<flamegpu::id_t>("id");
信息专业性是 FLAME GPU 软件的重要性能考虑因素。不同的消息类型有不同的实现和优化。在所有情况下,它们都使用 NVIDIA Nsight Compute 分析器进行了优化,以提高内存和计算吞吐量。
flamegpu::BruteForce的消息类型相当于每个代理读取列表中的每个消息。有许多消息类型,包括离散化环境、桶和数组的类型,其中大多数使用 CUB 排序和扫描函数来构建空间数据结构。本示例中使用的空间消息构建了一个装箱数据结构,使来自固定区域的消息能够轻松定位。
通过将上一节中定义的代理函数分配给特定代理,可以将它们链接到模型。下面的代码示例中定义的消息输入和输出类型需要与FLAMEGPU_AGENT_FUNCTION定义相匹配。
// Set up the two agent functions
flamegpu::AgentFunctionDescription out_fn =
agent.newFunction("output_message", output_message);
out_fn.setMessageOutput("location");
flamegpu::AgentFunctionDescription in_fn =
agent.newFunction("input_message", input_message);
in_fn.setMessageInput("location");
在 FLAME GPU 库中,变量名(如x)通过哈希转换为 CUDA 内存地址。编译时散列用于确保翻译在运行时开销最小。特定于函数的哈希表在每个代理函数开始时加载到共享内存中,以最小化延迟。
在开发过程中,可以使用 CMake 中的FLAMEGPU_SEATBELTS选项启用类型检查。此选项执行其他额外的运行时检查,这在开发过程中很有用。模型完成后,可以禁用FLAMEGPU_SEATBELTS以获得最大的执行性能。
FLAME GPU 还支持运行时编译的代理函数。在这种情况下,代理函数可以作为字符串提供,并使用 NVIDIA Jitify 库进行编译,该库充当 NVRTC 的前端。设备代码的运行时编译对于提供 Python 绑定(pyflamegpu)至关重要。
为了进一步改善 Python 中的用户体验,pyflamegpu允许在本地 Python 的子集中描述代理函数。作为运行时编译过程的一部分,这将被转换为 C ++。
环境财产可用于参数化模型,并可由所有代理读取。排斥因子AGENT_COUNT和ENV_WIDTH在代码示例中指定。所有环境财产都使用与代理变量相同的机制进行散列。
// Define environment properties
flamegpu::EnvironmentDescription env = model.Environment();
env.newProperty<unsigned int>("AGENT_COUNT", AGENT_COUNT);
env.newProperty<float>("ENV_WIDTH", ENV_WIDTH);
env.newProperty<float>("repulse", 0.05f);
建模规范的最后一个阶段是定义代理函数的执行顺序。这可以手动指定为层,也可以通过相关性分析进行推断。以下示例演示了通过相关性分析生成层的过程:
// Dependency specification flamegpu::DependencyGraph dependencyGraph = model.getDependencyGraph(); dependencyGraph.addRoot(out_fn); dependencyGraph.generateLayers(model);
将代理功能分离为多个层提供了一个同步框架,其中间接消息通信避免了竞争条件。更复杂的模型允许在同一层内重叠执行功能。层内使用的流支持并发执行,其优点在实现设备的良好利用方面可能非常重要。
执行调度是静态的,因为 DAG 不变。然而,图的各个方面可能不会导致特定功能的执行,例如,如果代理不存在于特定状态中。
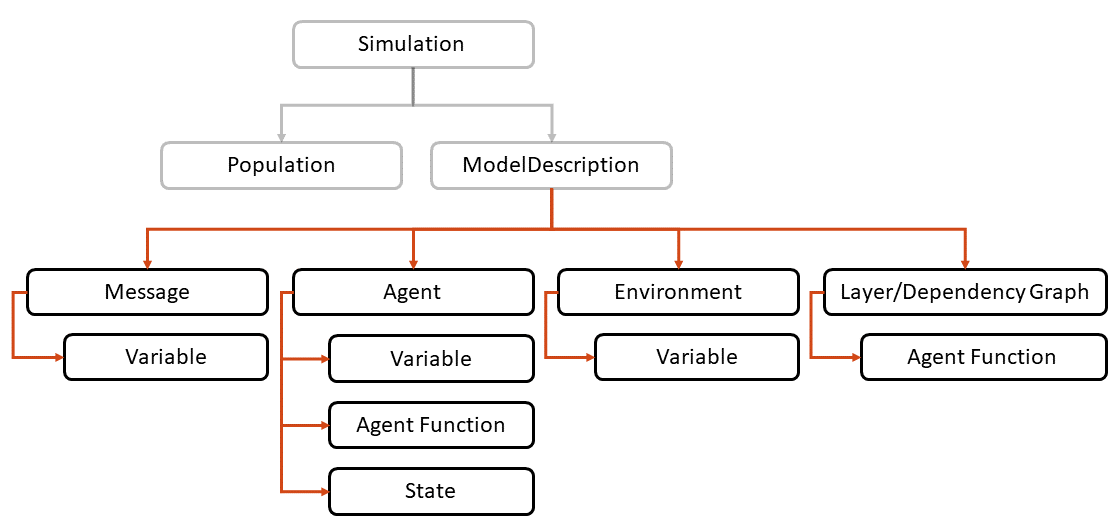
有关 API 的更多信息,请参阅 FLAME GPU documentation 。
模拟代理
执行代理模型需要CUDASimulation对象为 GPU 设备上的模型分配必要的内存。仿真对象负责配置模型的输入和输出以及仿真本身的启动配置。
程序的主要参数被传递给模拟对象,并且可以包括迭代次数(例如--steps 100)。
flamegpu::CUDASimulation cuda_sim(model, argc, argv);
虽然不需要,但可以使用flamegpu::StepLoggingConfig指定模型的日志记录,该选项设置日志记录的频率以及应记录的变量。可以使用通用的归约算子(min、man、
FLAMEGPU_AGENT_FUNCTION(output_message, flamegpu::MessageNone, flamegpu::MessageSpatial2D) {
FLAMEGPU->message_out.setVariable<int>("id", FLAMEGPU->getID());
FLAMEGPU->message_out.setLocation(
FLAMEGPU->getVariable<float>("x"),
FLAMEGPU->getVariable<float>("y"));
return flamegpu::ALIVE;
}
、
FLAMEGPU_AGENT_FUNCTION(input_message, flamegpu::MessageSpatial2D, flamegpu::MessageNone) {
const flamegpu::id_t ID = FLAMEGPU->getID();
const float REPULSE_FACTOR =
FLAMEGPU->environment.getProperty<float>("repulse");
const float RADIUS = FLAMEGPU->message_in.radius();
float fx = 0.0;
float fy = 0.0;
const float x1 = FLAMEGPU->getVariable<float>("x");
const float y1 = FLAMEGPU->getVariable<float>("y");
int count = 0;
// message loop iterator
for (const auto &message : FLAMEGPU->message_in(x1, y1)) {
if (message.getVariable<flamegpu::id_t>("id") != ID) {
const float x2 = message.getVariable<float>("x");
const float y2 = message.getVariable<float>("y");
float x21 = x2 - x1;
float y21 = y2 - y1;
const float separation = sqrt(x21*x21 + y21*y21);
if (separation < RADIUS && separation > 0.0f) {
float k = sinf((separation / RADIUS)*3.141f*-2)*REPULSE_FACTOR;
// Normalize without recalculating separation
x21 /= separation;
y21 /= separation;
fx += k * x21;
fy += k * y21;
count++;
}
}
}
fx /= count > 0 ? count : 1;
fy /= count > 0 ? count : 1;
FLAMEGPU->setVariable<float>("x", x1 + fx);
FLAMEGPU->setVariable<float>("y", y1 + fy);
FLAMEGPU->setVariable<float>("drift", sqrt(fx*fx + fy*fy));
return flamegpu::ALIVE;
}
、sum)来归约代理变量值,或者可以记录总体的整个状态变量。
flamegpu::StepLoggingConfig step_log_cfg(cuda_sim);
step_log_cfg.setFrequency(1);
step_log_cfg.agent("circle").logMean<float>("drift");
// Attach the logging config
cuda_sim.setStepLog(step_log_cfg);
对于工作示例中的圆圈模型,记录漂移可以测量整体代理移动。漂移是一种新兴的特性,随着药剂形成结构化的圆形,预计会随着时间的推移而减少(图 2 )。
模拟的最后阶段是定义代理的初始变量。在下面的示例中, Mersenne Twister 伪随机生成器用于生成群体中每个代理的x和y变量。flamegpu::AgentVector对象提供了一种设置代理数据的机制。这存储在设备内存中的密集阵列中,以促进来自代理函数的联合访问。
std::mt19937_64 rng;
std::uniform_real_distribution<float> dist(0.0f, ENV_MAX);
flamegpu::AgentVector population(model.Agent("circle"), AGENT_COUNT);
for (unsigned int i = 0; i < AGENT_COUNT; i++) {
flamegpu::AgentVector::Agent instance = population[i];
instance.setVariable<float>("x", dist(rng));
instance.setVariable<float>("y", dist(rng));
}
cuda_sim.setPopulationData(population);
最后,可以执行模拟。
// Run the simulation cuda_sim.simulate();
在这个示例中,只执行一次模拟。step_log_cfg对象可用于处理输出或将记录的值转储到文件中。 FLAME GPU 还支持集成仿真,允许执行仿真的多个实例化,但输入和环境财产不同。
模拟实例化可以被安排在单个设备上执行,或者可以在共享内存系统上的设备之间分布。我们已广泛使用此功能来校准癌症生长和治疗的生物模型。
如果需要图形模拟,可以使用 FLAME GPU 内置 3D OpenGL 可视化工具( video )对模拟进行可视化。可视化工具支持基于实例的代理渲染,并使用 CUDA OpenGL 互操作性将代理数据直接映射到图形管道中。
如果你观看这个模拟的视频,你会发现每个代理实际上都是一个带有扑动动画的 3D 鸟类模型。数百万代理的交互可视化是可能的,可视化工具允许导航和交互操作环境变量,以观察紧急效果。
表演
FLAME GPU 在基于代理的模拟中非常有效,但是,很难对基于代理的模拟器进行公平比较。大多数现有的模拟器都是为串行执行而设计的。事实上,许多现有模型甚至依赖于串行操作来确保公平性。”
这方面的一个经典例子是在离散(或棋盘式)环境中移动代理。在串行中,代理的移动确保环境单元从不被多个代理占用。随机化运动顺序可确保模拟公平。
在 FLAME GPU 中实现的这种移动的并行等价物需要使用迭代竞价过程,以确保所有代理都有机会移动并避免小区占用中的冲突。
FLAME GPU 引入了子模型的新概念,以封装递归算法来解决此类冲突。基于代理的模型避免了空间冲突并在连续空间中运行,因此在并行环境中性能更好,因为在移动过程中不会发生冲突。
我们选择比较两个不同的模型,以显示 FLAME GPU 与其他知名 CPU 模拟器 Mesa 、 NetLogo 和 Agents.jl (Julia) 的比较。我们选择了两个众所周知的模型,其中每个框架中都有现有的实现。
其中的第一个是 2D 中的 Boids 植绒模型的实现,在连续空间中运行,与本文中的示例类似,只是代理之间的交互稍微复杂一些。
第二,谢林的社会隔离模式,是高度系列化模式的一个例子。它可以在棋盘式环境中移动。在 FLAME GPU 中,它使用子模型来解决移动中的冲突。
Boids 模型的性能在 100 次迭代中进行了测量,仅限于 80k 个代理,这不足以完全使用现代 GPU 设备。除此之外,串行模拟器是合理基准测试时间的限制因素。在 Schelling 模型中,规模增加到 250K 个代理( 80% 的单元占用率),因为由于受限的基于网格的环境,它在所有模拟器中的执行效率更高。
包含这两个模型的基准是容器化的,可在 FLAMEGPU/ABM_Framework_Comparisons GitHub repo 上使用。这是 forked 来自为 Agents.js 框架进行的现有基准活动。为了生成图 5 ,每次模拟总共重复 10 次。为了节省时间, NetLogo 和 MESA 的重复次数减少为三次。
通过测量主模拟回路报告平均模拟时间,不包括所有模拟器中常见的模式初始化。结果是从具有以下配置的机器上获得的:
- Ubuntu 22.04 Apptainer 映像
- AMD EPYC 7413 24 核处理器
- NVIDIA A100-SXM4 80 GB (驱动程序 515.65.01 )
- Flame GPU 2.0.0-rc0
- Netlogo 6.3
- Mesa 1.0
- CUDA 11.7
- GCC 11.3
- Python 3.10
- Julia 1.8.2
- Agents.jl 5.5
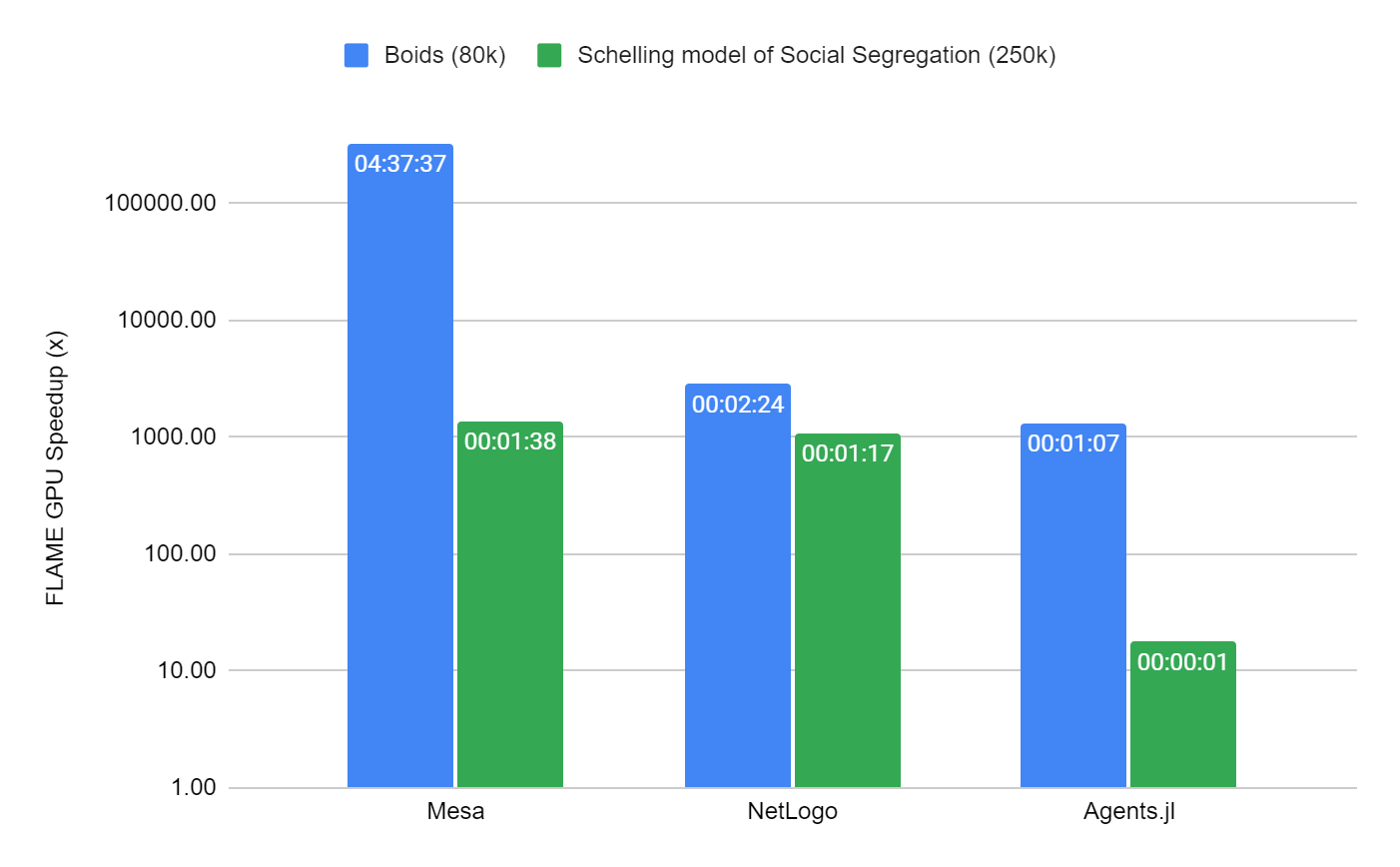
考虑到 Boids 模型的性能, FLAME GPU 至少比次优模拟器( Agents.jl )快 1000 倍,比最差模拟器( Mesa )快数十万倍。 FLAME GPU 的模拟时间仅为约 51 毫秒。
对于 Schelling 模型, FLAME GPU 比第二快的模拟器 Agents.jsl 快约 18 倍,耗时约 70 毫秒,比 NetLogo 和 Mesa 快 1000 多倍。
FLAME GPU 的性能可归因于 FLAME GPU 转换模型以利用 GPU 高水平并行性的能力。该框架的设计考虑到了并行性和性能,并平衡了内存带宽和计算,以实现高水平的设备利用率。
FLAME GPU 软件确实需要一些模型串行初始化以及 CUDA 上下文创建的开销。其他模拟器具有相同的开销,例如, Agents.jar 使用实时编译。然而,固定成本管理费用可以通过运行时间较长的模型轻松摊销。
FLAME GPU 有可能大大提高桌面用户可用的模拟性能和规模。正在进行的研究活动的一个领域正在考虑巨大的挑战问题,其中模拟规模可以扩展到数十亿个代理。
一个这样的例子是 EU Horizon 2020 PRIMAGE project ,它支持了软件的开发。在该项目中, FLAME GPU 用于支持神经母细胞瘤( NB )的决策和临床管理, NB 是儿童早期最常见的实体癌症。该项目使用精心策划的模拟方法来研究药物治疗对超过 30 亿细胞的全肿瘤的影响。
立即尝试 FLAME GPU
FLAME GPU 软件是 MIT 许可证下的开源软件。它可以从 FLAMEGPU/FLAMEGPU2 GitHub repo 或 FLAME GPU website 下载,其中包括使用 CMake 的构建指令。您可以使用pip安装托管在 GitHub 上的预打包 Python 模块。
致谢
该项目的支持由 Applied Research Accelerator Program at NVIDIA.