
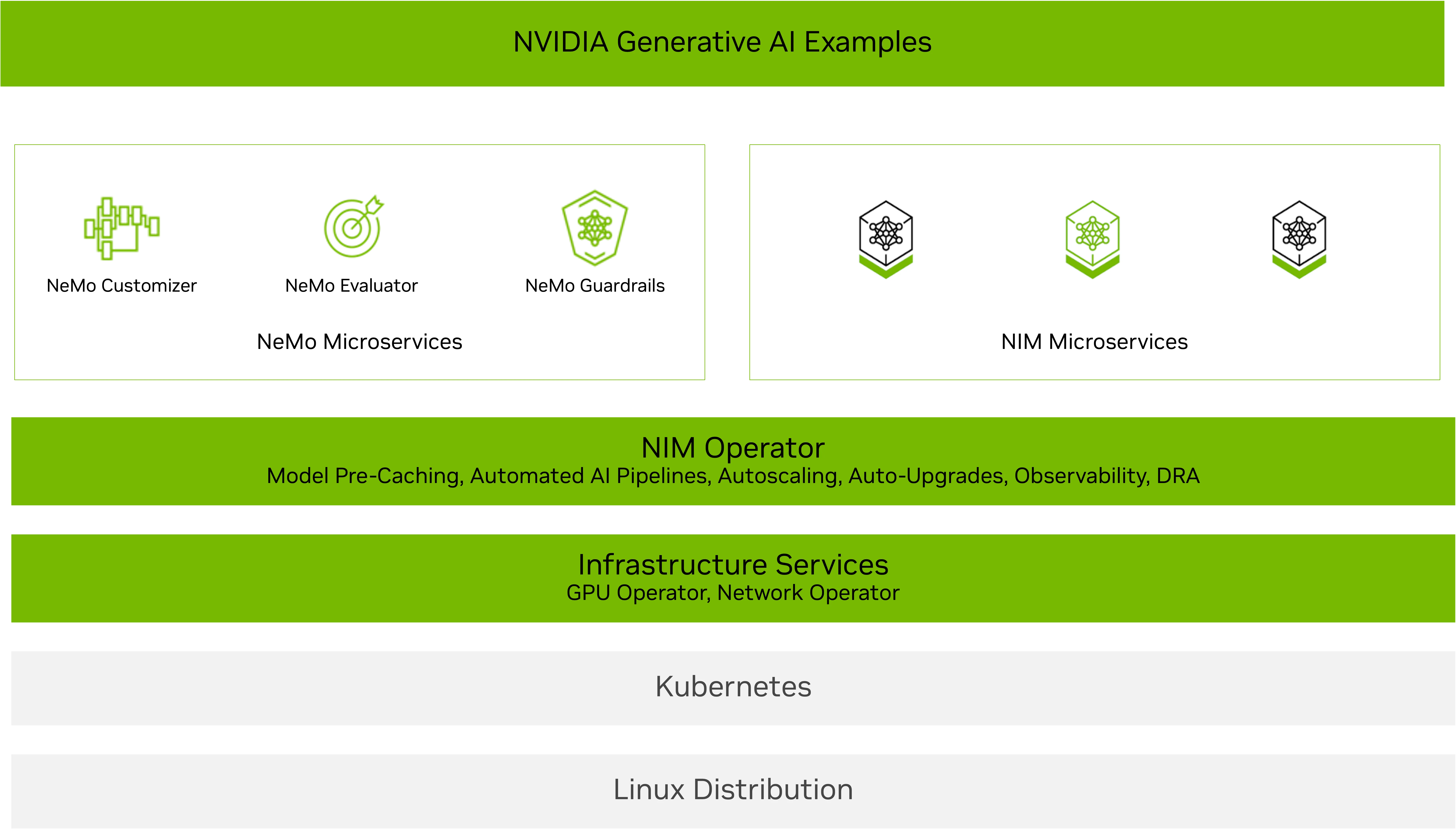
AI 模型、推理引擎后端以及分布式推理框架在架构、复杂性和规模上持续演进。面对快速的技术变革,部署并高效管理支撑这些高级功能的 AI 推理工作流正面临严峻挑战。
NVIDIA NIM Operator 旨在助力实现智能化扩展。它使 Kubernetes 集群管理员能够高效管理运行 NVIDIA NIM 推理微服务 所需的软件组件与服务,适用于各类大型语言模型及多模态 AI 模型,涵盖推理、检索、视觉、语音、生物信息学等应用场景。
NVIDIA NIM Operator 3.0.0 版本新增了扩展功能,可简化并优化在 Kubernetes 环境中部署 NVIDIA NIM 微服务 和 NVIDIA NeMo 微服务 的流程。该版本支持高效利用资源,并能与现有的 Kubernetes 基础设施(包括 KServe 部署)实现无缝集成。
NVIDIA 的客户与合作伙伴正利用 NIM Operator 高效管理各类应用及 AI 智能体,涵盖聊天机器人、代理式 RAG,以及虚拟药物研发。
NVIDIA 近期与 Red Hat 展开合作,通过 NIM Operator 在 KServe 上实现 NIM 的部署。红帽工程总监 Babak Mozaffari 表示:“红帽已为 NIM Operator 的开源 GitHub 仓库 做出贡献,以支持在 KServe 上部署 NVIDIA NIM。”该功能使 NIM Operator 部署能够受益于 KServe 的生命周期管理,以运行 NIM 微服务,并借助 NIM 服务简化大规模 NIM 部署流程。NIM Operator 原生集成 KServe 后,用户还可通过 NIM 缓存利用模型缓存优势,并为所有 KServe 推理端点集成 NeMo Guardrails 等 NeMo 功能,构建更加可信的 AI 应用。
本文将介绍 NIM Operator 3.0.0 版本中的新增功能,涵盖以下内容:
- 简化多 LLM 兼容和多节点 NIM 部署
- 通过动态资源分配 (DRA) 高效利用 GPU
- 在 KServe 上无缝部署
灵活的 NIM 部署:多 LLM 兼容和多节点
NIM Operator 3.0.0 增强了对简单、快速部署 NIM 的支持。您可以将其与面向特定领域的 NIM(例如用于生物学、语音或检索的 NIM)结合使用,也可搭配多种 NIM 部署选项,包括 多 LLM 兼容,或 多节点。
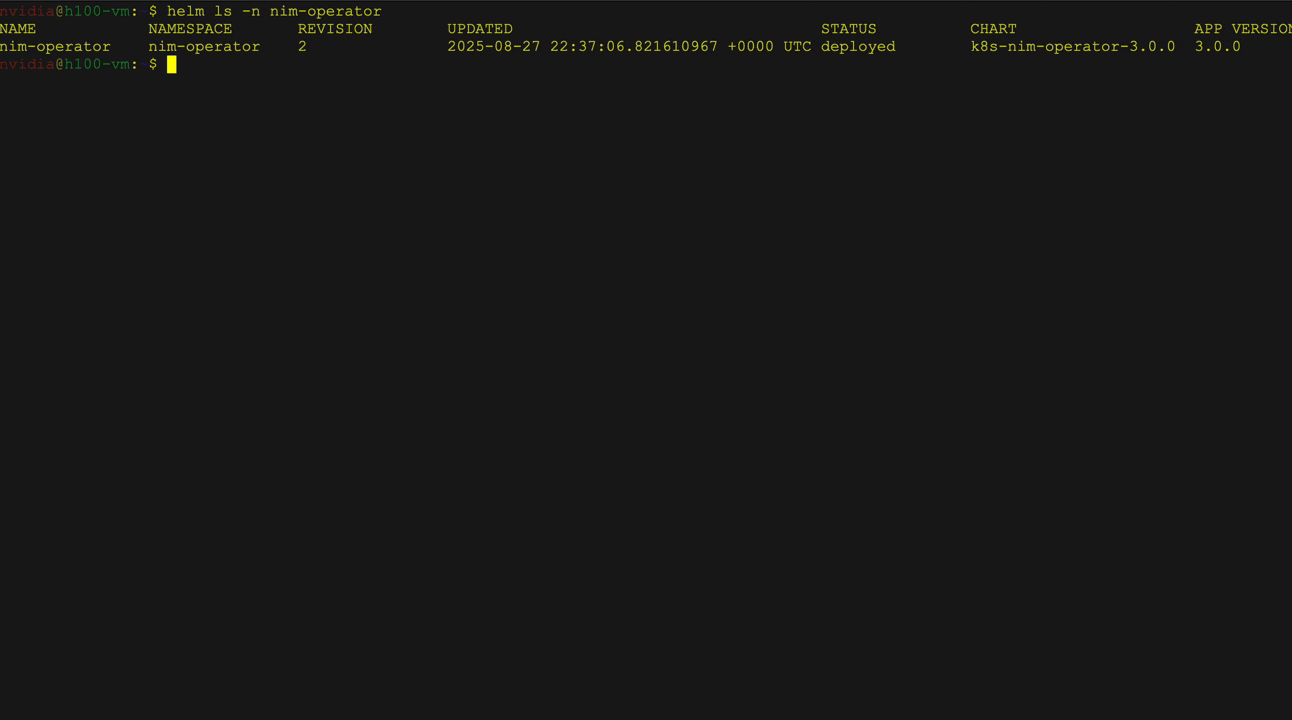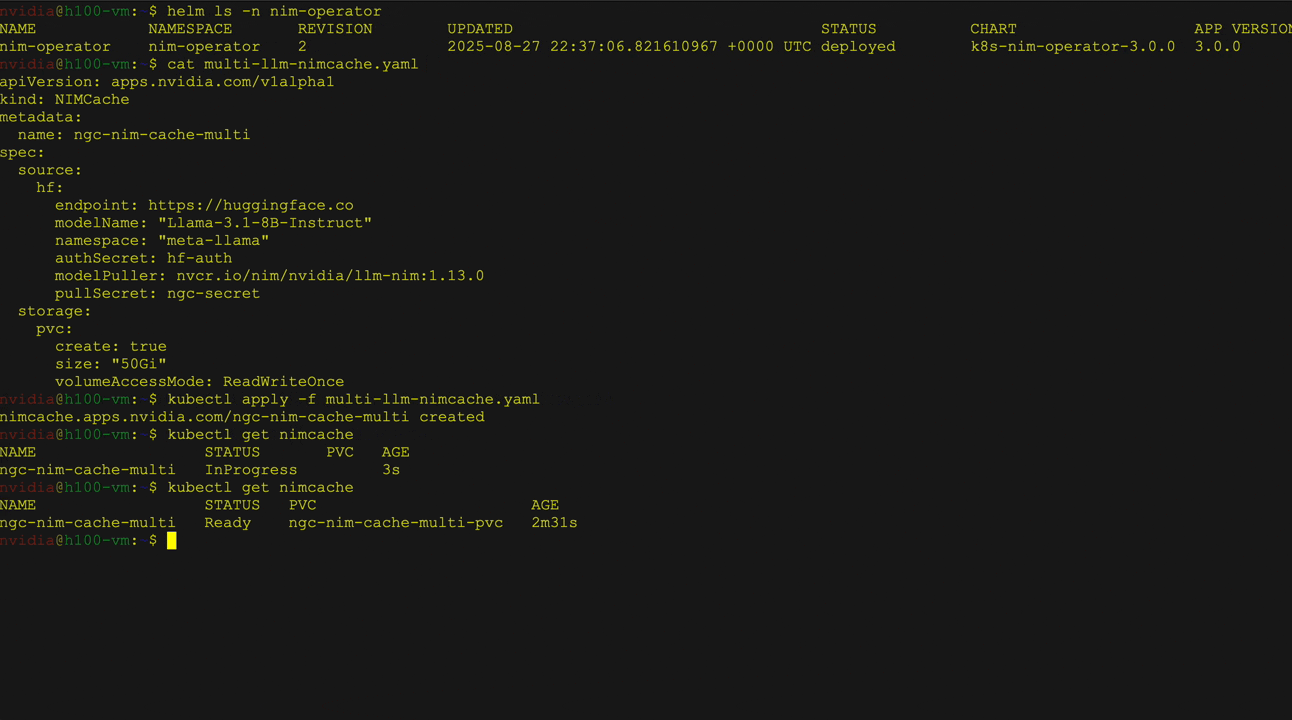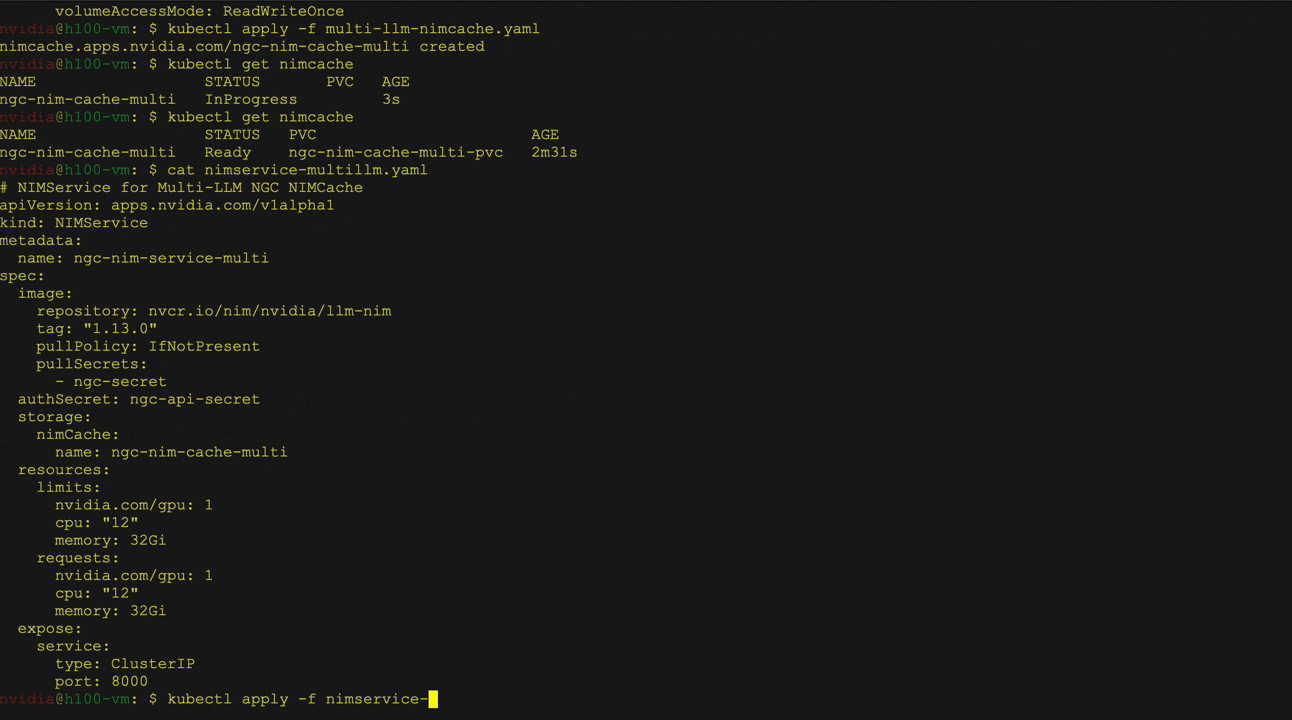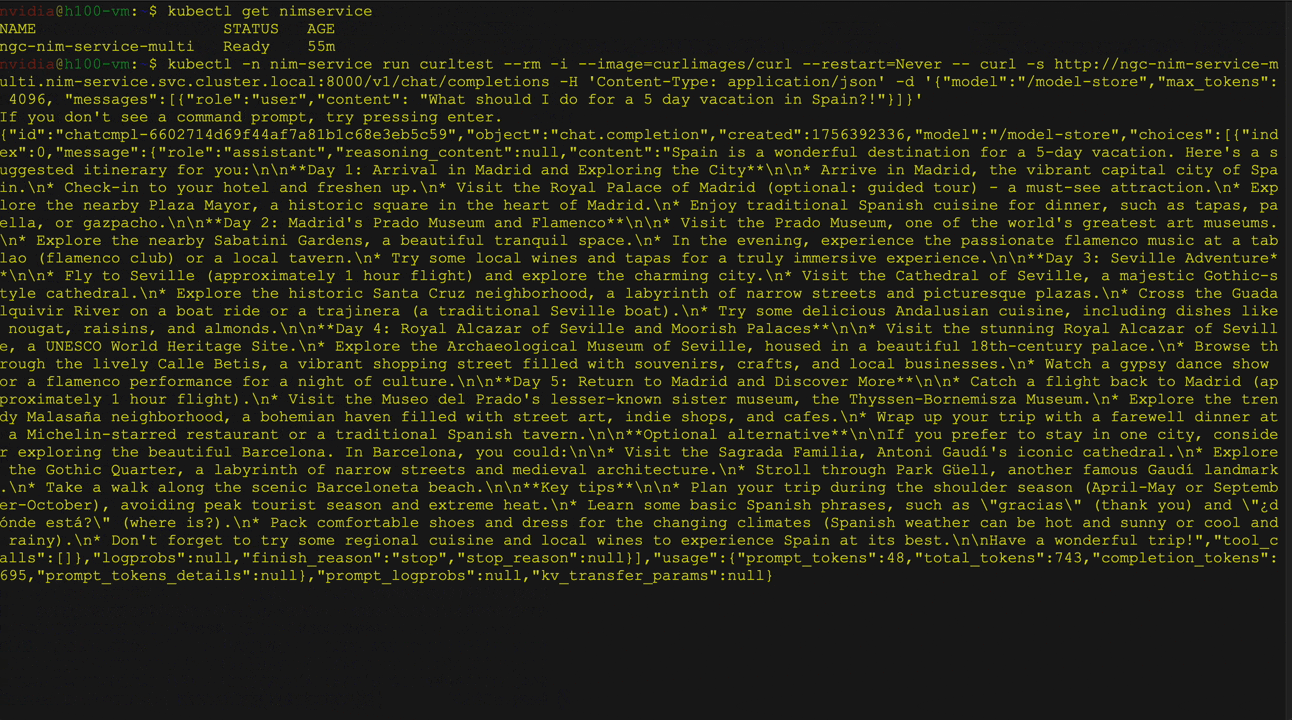
- 多 LLM 兼容 NIM 部署:使用来自 NVIDIA NGC、Hugging Face 或本地存储等来源的自定义权重部署不同的模型。使用 NIM 缓存自定义资源定义 (CRD) 将权重下载到 PVC,并使用 NIM 服务 CRD 管理部署、扩展和入口。
- 多节点 NIM 部署解决了部署无法在单个 GPU 上运行或需要在多个 GPU 上运行且可能需要在多个节点上运行的大规模 LLM 的挑战。NIM Operator 支持使用 NIM 缓存 CRD 缓存多节点 NIM 部署,并支持使用 NIM 服务 CRD 在 Kubernetes 上使用 LeaderWorkerSets (LWS) 进行部署。
请注意,由于模型分片加载超时,未配置 GPUDirect RDMA 的多节点 NIM 部署可能导致 LWS Leader 和工作节点容器频繁重启。建议采用高速网络连接(如 IPoIB 或 ROCE),并可通过 NVIDIA Network Operator 轻松完成配置。
图2展示了在Kubernetes上利用Hugging Face库部署大语言模型(LLM)时,使用NVIDIA NIM Operator实现多个LLM NIM部署的场景。其中以Llama 3 8B Instruct模型为例,详细演示了模型的部署过程,包括服务与Pod状态的验证,以及通过curl命令向服务发送请求的操作。
借助 DRA 高效利用 GPU
DRA 是一项内置的 Kubernetes 功能,可将传统的设备插件替换为更灵活、更具扩展性的方案,从而简化 GPU 管理。通过 DRA,用户能够定义 GPU 设备类别,按类别申请 GPU 资源,并根据工作负载和业务需求进行筛选和调度。
NIM Operator 3.0.0 通过 NIM 服务 CRD 和 NIM 工作流 CRD,在 NIM Pod 上配置 ResourceClaim 和 ResourceClaimTemplate,从而在技术预览阶段支持 DRA。您可以手动创建并绑定自定义的资源声明,也可以由 NIM 服务 CRD 和 NIM 工作流 CRD 自动创建并管理这些声明。
支持 NIM Operator DRA:
- 完整使用 GPU 和 MIG
- 通过时间切片将相同声明分配给多个 NIM 服务来实现 GPU 共享
注意:此功能目前为技术预览版,即将全面支持。
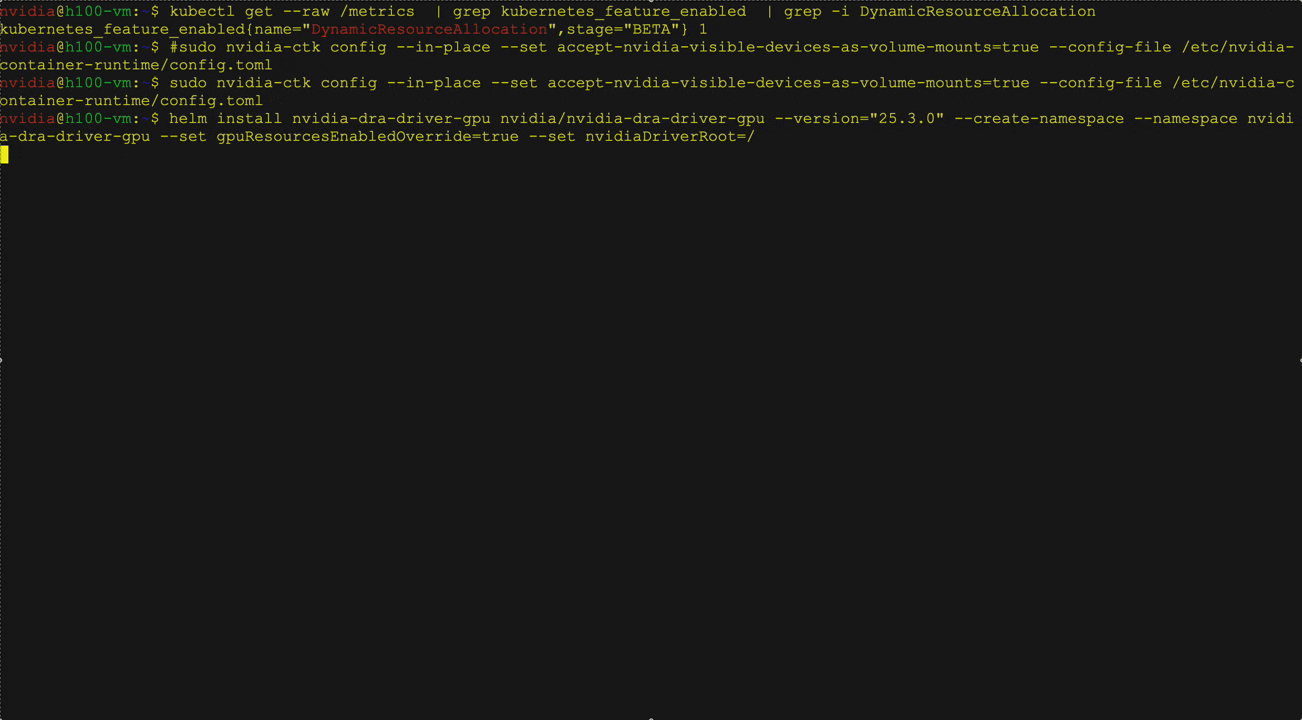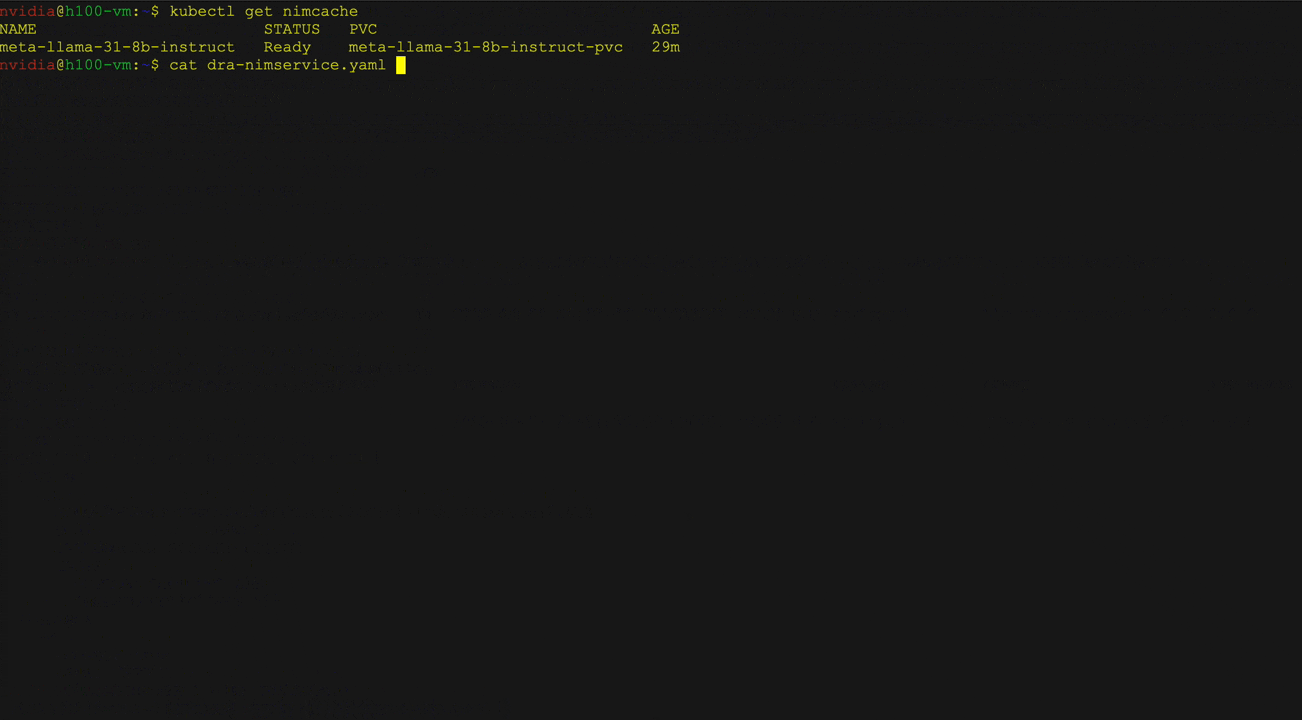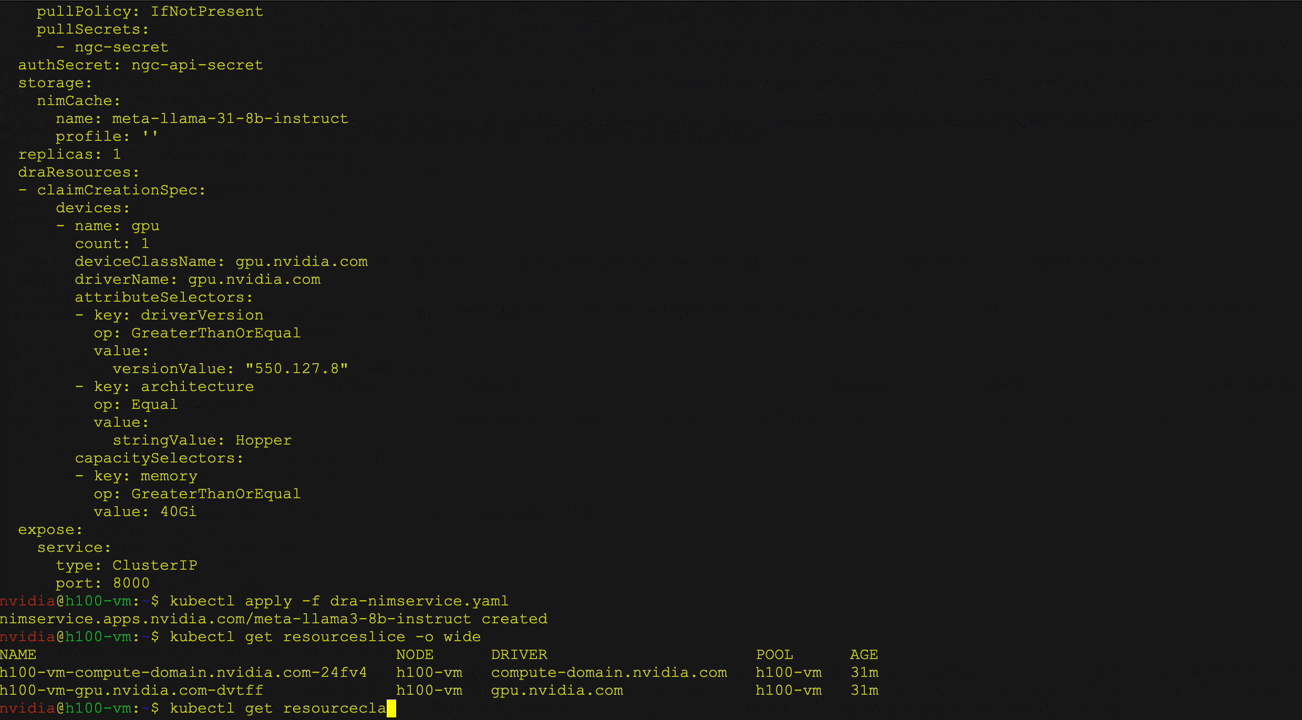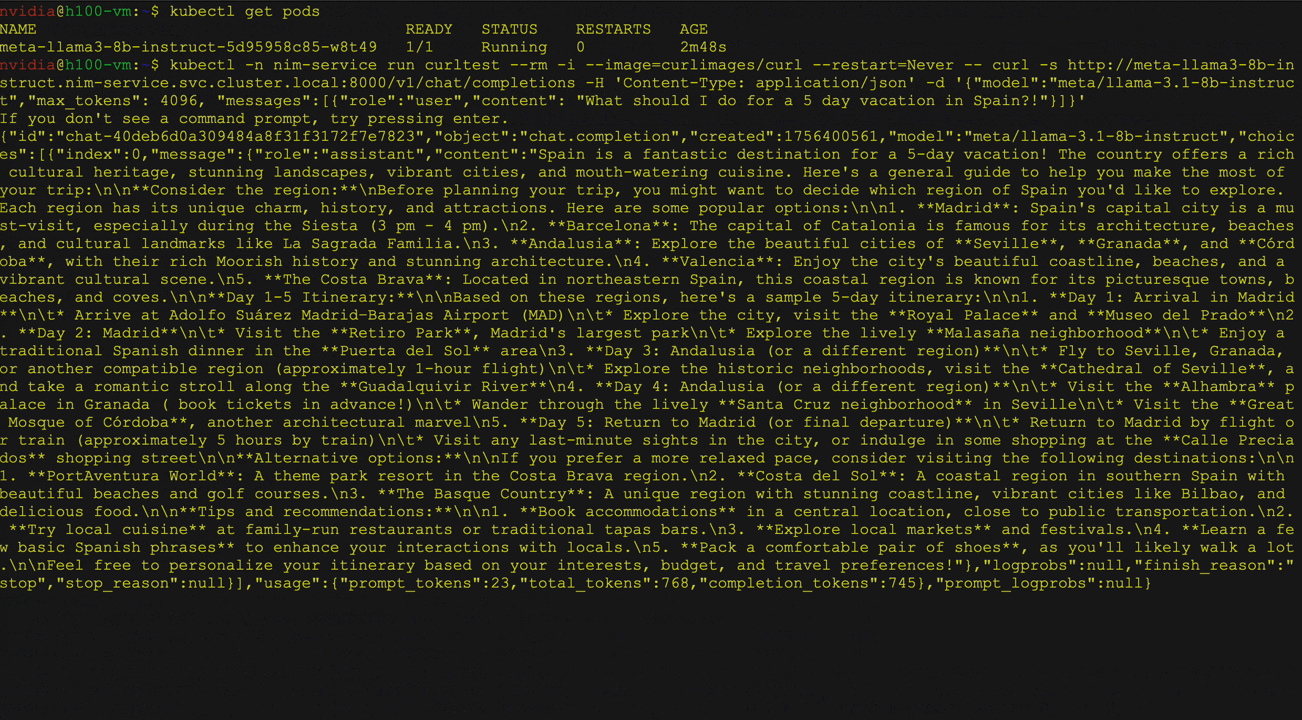
图 3 展示了如何利用 Llama 3 8B Instruct NIM 使用 Kubernetes DRA 和 NIM Operator。用户可在 NIM 服务中定义资源请求,以指定所需的硬件特性(如 GPU 架构和内存),并通过 curl 与已部署的 LLM 进行交互。
在 KServe 上无缝部署
KServe 是一个广受合作伙伴和客户采用的开源推理服务平台。 NIM Operator 3.0.0 通过配置 InferenceService 自定义资源,支持在 KServe 上进行传统部署和无服务器部署,并实现 NIM 的部署、升级与自动扩缩容管理。NIM Operator 能够自动在 InferenceService CRD 中配置所有必需的环境变量和资源,从而简化部署流程。
该集成具备两大额外优势:
- 使用 NIM 缓存进行智能缓存,可减少初始推理时间和自动扩展延迟,从而实现更快、响应更灵敏的部署。
- NeMo 微服务支持评估、护栏和自定义,可增强 AI 系统的延迟、准确性、成本和合规性。
图 4 展示了在 KServe 上使用 NIM Operator 部署 Llama 3.2 1B Instruct NIM 的两种不同方式:RawDeployment 和 Serverless。其中,Serverless 部署通过 Kubernetes 标注实现了自动扩缩容功能。两种部署策略均通过 curl 命令对 NIM 的响应进行了测试。

开始使用 NIM Operator 3.0.0 扩展 AI 推理
NVIDIA NIM Operator 3.0.0 让部署可扩展的 AI 推理变得更加简便。无论是部署多 LLM 兼容方案或多节点 NIM,通过 DRA 优化 GPU 利用率,还是在 KServe 上进行部署,该版本都能帮助您构建高性能、灵活且可扩展的 AI 应用。
NIM Operator 通过自动化部署、扩展和管理 NVIDIA NIM 与 NVIDIA NeMo 微服务的生命周期,帮助企业团队更高效地采用 AI 工作流。该方案与 NVIDIA AI Blueprint 协同,可简化 AI 工作流的部署过程,加快生产环境的落地。作为 NVIDIA AI Enterprise 的组成部分,NIM Operator 提供企业级支持、稳定的 API 接口以及主动的安全补丁,保障 AI 应用的可靠运行。
可通过 NGC 或从 NVIDIA/k8s-nim-operator 开源 GitHub 仓库开始使用。如需了解安装、使用方法或遇到技术问题,请在 NVIDIA/k8s-nim-operator GitHub 仓库 中提交问题。






