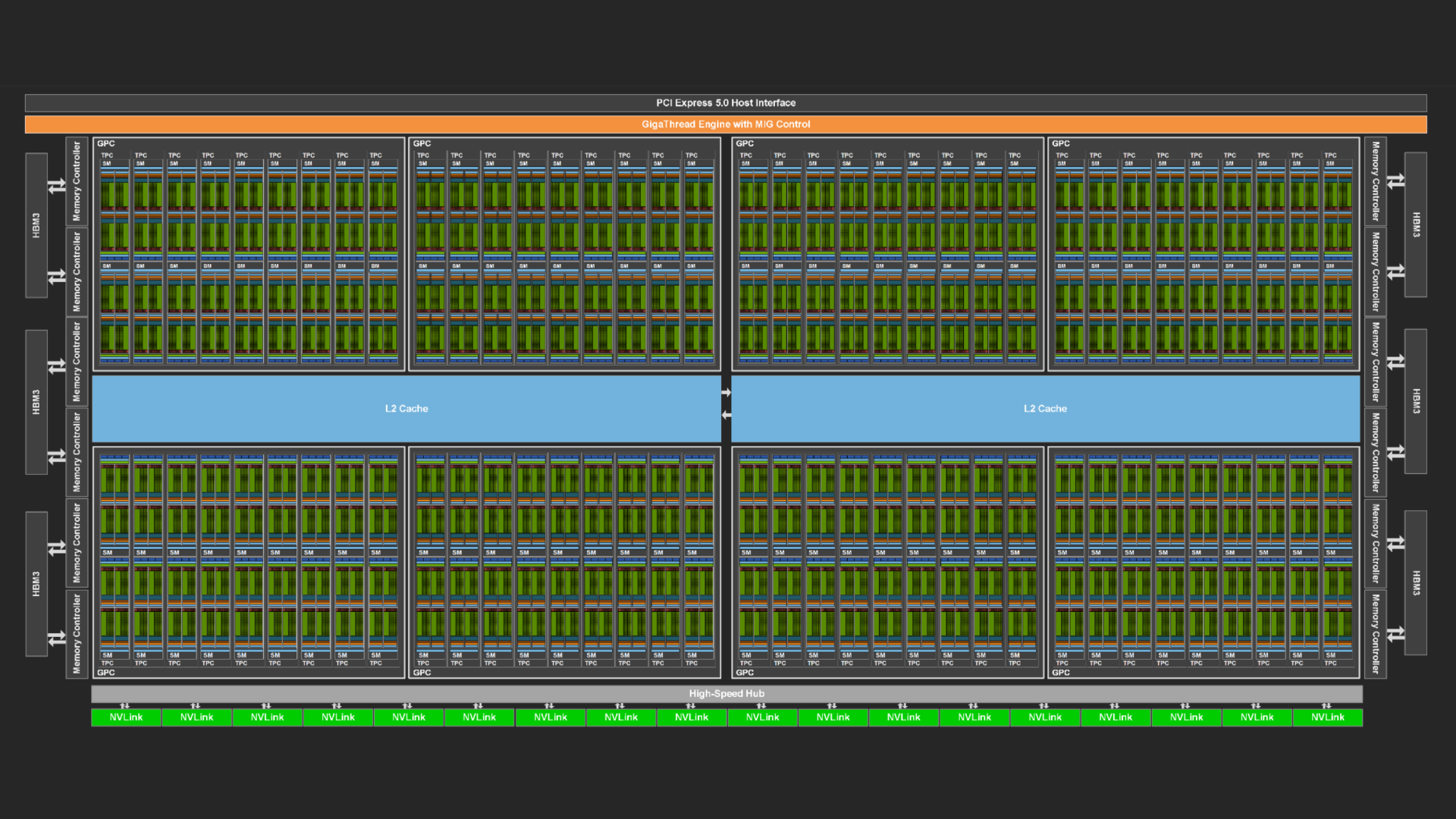
N.1. Unified Memory Introduction
统一内存是 CUDA 编程模型的一个组件,在 CUDA 6.0 中首次引入,它定义了一个托管内存空间,在该空间中所有处理器都可以看到具有公共地址空间的单个连贯内存映像。
注意:处理器是指任何具有专用 MMU 的独立执行单元。这包括任何类型和架构的 CPU 和 GPU。
底层系统管理 CUDA 程序中的数据访问和位置,无需显式内存复制调用。这在两个主要方面有利于 GPU 编程:
- 通过统一系统中所有 GPU 和 CPU 的内存空间以及为 CUDA 程序员提供更紧密、更直接的语言集成,可以简化 GPU 编程。
- 通过透明地将数据迁移到使用它的处理器,可以最大限度地提高数据访问速度。
简单来说,统一内存消除了通过 cudaMemcpy*() 例程进行显式数据移动的需要,而不会因将所有数据放入零拷贝内存而导致性能损失。当然,数据移动仍然会发生,因此程序的运行时间通常不会减少;相反,统一内存可以编写更简单、更易于维护的代码。
统一内存提供了一个“单指针数据”模型,在概念上类似于 CUDA 的零拷贝内存。两者之间的一个关键区别在于,在零拷贝分配中,内存的物理位置固定在 CPU 系统内存中,因此程序可以快速或慢速地访问它,具体取决于访问它的位置。另一方面,统一内存将内存和执行空间解耦,以便所有数据访问都很快。
统一内存一词描述了一个为各种程序提供内存管理服务的系统,从针对运行时 API 的程序到使用虚拟 ISA (PTX) 的程序。该系统的一部分定义了选择加入统一内存服务的托管内存空间。
托管内存可与特定于设备的分配互操作和互换,例如使用 cudaMalloc() 例程创建的分配。所有在设备内存上有效的 CUDA 操作在托管内存上也有效;主要区别在于程序的主机部分也能够引用和访问内存。
注意:连接到 Tegra 的离散 GPU 不支持统一内存。
N.1.1. System Requirements
统一内存有两个基本要求:
- 具有 SM 架构 3.0 或更高版本(Kepler 类或更高版本)的 GPU
- 64 位主机应用程序和非嵌入式操作系统(Linux 或 Windows) 具有 SM 架构 6.x 或更高版本(Pascal 类或更高版本)的 GPU 提供额外的统一内存功能,例如本文档中概述的按需页面迁移和 GPU 内存超额订阅。 请注意,目前这些功能仅在 Linux 操作系统上受支持。 在 Windows 上运行的应用程序(无论是 TCC 还是 WDDM 模式)将使用基本的统一内存模型,就像在 6.x 之前的架构上一样,即使它们在具有 6.x 或更高计算能力的硬件上运行也是如此。 有关详细信息,请参阅数据迁移和一致性。
N.1.2. Simplifying GPU Programming
内存空间的统一意味着主机和设备之间不再需要显式内存传输。在托管内存空间中创建的任何分配都会自动迁移到需要的位置。
程序通过以下两种方式之一分配托管内存: 通过 cudaMallocManaged() 例程,它在语义上类似于 cudaMalloc();或者通过定义一个全局 __managed__ 变量,它在语义上类似于一个 __device__ 变量。在本文档的后面部分可以找到这些的精确定义。 注意:在具有计算能力 6.x 及更高版本的设备的支持平台上,统一内存将使应用程序能够使用默认系统分配器分配和共享数据。这允许 GPU 在不使用特殊分配器的情况下访问整个系统虚拟内存。有关更多详细信息,请参阅系统分配器。 以下代码示例说明了托管内存的使用如何改变主机代码的编写方式。首先,一个没有使用统一内存的简单程序:
__global__ void AplusB(int *ret, int a, int b) {
ret[threadIdx.x] = a + b + threadIdx.x;
}
int main() {
int *ret;
cudaMalloc(&ret, 1000 * sizeof(int));
AplusB<<< 1, 1000 >>>(ret, 10, 100);
int *host_ret = (int *)malloc(1000 * sizeof(int));
cudaMemcpy(host_ret, ret, 1000 * sizeof(int), cudaMemcpyDefault);
for(int i = 0; i < 1000; i++)
printf("%d: A+B = %d\n", i, host_ret[i]);
free(host_ret);
cudaFree(ret);
return 0;
}
第一个示例在 GPU 上将两个数字与每个线程 ID 组合在一起,并以数组形式返回值。 如果没有托管内存,则返回值的主机端和设备端存储都是必需的(示例中为 host_ret 和 ret),使用 cudaMemcpy() 在两者之间显式复制也是如此。
将此与程序的统一内存版本进行比较,后者允许从主机直接访问 GPU 数据。 请注意 cudaMallocManaged() 例程,它从主机和设备代码返回一个有效的指针。 这允许在没有单独的 host_ret 副本的情况下使用 ret,大大简化并减小了程序的大小。
__global__ void AplusB(int *ret, int a, int b) {
ret[threadIdx.x] = a + b + threadIdx.x;
}
int main() {
int *ret;
cudaMallocManaged(&ret, 1000 * sizeof(int));
AplusB<<< 1, 1000 >>>(ret, 10, 100);
cudaDeviceSynchronize();
for(int i = 0; i < 1000; i++)
printf("%d: A+B = %d\n", i, ret[i]);
cudaFree(ret);
return 0;
}
最后,语言集成允许直接引用 GPU 声明的 __managed__ 变量,并在使用全局变量时进一步简化程序。
__device__ __managed__ int ret[1000];
__global__ void AplusB(int a, int b) {
ret[threadIdx.x] = a + b + threadIdx.x;
}
int main() {
AplusB<<< 1, 1000 >>>(10, 100);
cudaDeviceSynchronize();
for(int i = 0; i < 1000; i++)
printf("%d: A+B = %d\n", i, ret[i]);
return 0;
}
请注意没有明确的 cudaMemcpy() 命令以及返回数组 ret 在 CPU 和 GPU 上都可见的事实。
值得一提的是主机和设备之间的同步。 请注意在非托管示例中,同步 cudaMemcpy() 例程如何用于同步内核(即等待它完成运行)以及将数据传输到主机。 统一内存示例不调用 cudaMemcpy(),因此需要显式 cudaDeviceSynchronize(),然后主机程序才能安全地使用 GPU 的输出。
N.1.3. Data Migration and Coherency
统一内存尝试通过将数据迁移到正在访问它的设备来优化内存性能(也就是说,如果 CPU 正在访问数据,则将数据移动到主机内存,如果 GPU 将访问它,则将数据移动到设备内存)。数据迁移是统一内存的基础,但对程序是透明的。系统将尝试将数据放置在可以最有效地访问而不违反一致性的位置。
数据的物理位置对程序是不可见的,并且可以随时更改,但对数据的虚拟地址的访问将保持有效并且可以从任何处理器保持一致,无论位置如何。请注意,保持一致性是首要要求,高于性能;在主机操作系统的限制下,系统被允许访问失败或移动数据,以保持处理器之间的全局一致性。
计算能力低于 6.x 的 GPU 架构不支持按需将托管数据细粒度移动到 GPU。每当启动 GPU 内核时,通常必须将所有托管内存转移到 GPU 内存,以避免内存访问出错。计算能力 6.x 引入了一种新的 GPU 页面错误机制,可提供更无缝的统一内存功能。结合系统范围的虚拟地址空间,页面错误提供了几个好处。首先,页面错误意味着 CUDA 系统软件不需要在每次内核启动之前将所有托管内存分配同步到 GPU。如果在 GPU 上运行的内核访问了一个不在其内存中的页面,它就会出错,从而允许该页面按需自动迁移到 GPU 内存。或者,可以将页面映射到 GPU 地址空间,以便通过 PCIe 或 NVLink 互连进行访问(访问映射有时可能比迁移更快)。请注意,统一内存是系统范围的:GPU(和 CPU)可以从 CPU 内存或系统中其他 GPU 的内存中发生故障并迁移内存页面。
N.1.4. GPU Memory Oversubscription
计算能力低于 6.x 的设备分配的托管内存不能超过 GPU 内存的物理大小。
计算能力 6.x 的设备扩展了寻址模式以支持 49 位虚拟寻址。 这足以覆盖现代 CPU 的 48 位虚拟地址空间,以及 GPU 自己的内存。 大的虚拟地址空间和页面错误能力使应用程序可以访问整个系统的虚拟内存,而不受任何一个处理器的物理内存大小的限制。 这意味着应用程序可以超额订阅内存系统:换句话说,它们可以分配、访问和共享大于系统总物理容量的数组,从而实现超大数据集的核外处理。 只要有足够的系统内存可用于分配,cudaMallocManaged 就不会耗尽内存。
N.1.5. Multi-GPU
对于计算能力低于 6.x 的设备,托管内存分配的行为与使用 cudaMalloc() 分配的非托管内存相同:当前活动设备是物理分配的主站,所有其他 GPU 接收到内存的对等映射。这意味着系统中的其他 GPU 将以较低的带宽通过 PCIe 总线访问内存。请注意,如果系统中的 GPU 之间不支持对等映射,则托管内存页面将放置在 CPU 系统内存(“零拷贝”内存)中,并且所有 GPU 都会遇到 PCIe 带宽限制。有关详细信息,请参阅 6.x 之前架构上的多 GPU 程序的托管内存。
具有计算能力 6.x 设备的系统上的托管分配对所有 GPU 都是可见的,并且可以按需迁移到任何处理器。统一内存性能提示(请参阅性能调优)允许开发人员探索自定义使用模式,例如跨 GPU 读取重复数据和直接访问对等 GPU 内存而无需迁移。
N.1.6. System Allocator
计算能力 7.0 的设备支持 NVLink 上的地址转换服务 (ATS)。 如果主机 CPU 和操作系统支持,ATS 允许 GPU 直接访问 CPU 的页表。 GPU MMU 中的未命中将导致向 CPU 发送地址转换请求 (ATR)。 CPU 在其页表中查找该地址的虚拟到物理映射并将转换提供回 GPU。 ATS 提供 GPU 对系统内存的完全访问权限,例如使用 malloc 分配的内存、在堆栈上分配的内存、全局变量和文件支持的内存。 应用程序可以通过检查新的 pageableMemoryAccessUsesHostPageTables 属性来查询设备是否支持通过 ATS 一致地访问可分页内存。
这是一个适用于任何满足统一内存基本要求的系统的示例代码(请参阅系统要求):
int *data; cudaMallocManaged(&data, sizeof(int) * n); kernel<<<grid, block>>>(data);
具有 pageableMemoryAccess 属性的系统支持这些新的访问模式:
int *data = (int*)malloc(sizeof(int) * n); kernel<<<grid, block>>>(data);
int data[1024]; kernel<<<grid, block>>>(data);
extern int *data; kernel<<<grid, block>>>(data);
在上面的示例中,数据可以由第三方 CPU 库初始化,然后由 GPU 内核直接访问。 在具有 pageableMemoryAccess 的系统上,用户还可以使用 cudaMemPrefetchAsync 将可分页内存预取到 GPU。 这可以通过优化数据局部性产生性能优势。
注意:目前仅 IBM Power9 系统支持基于 NVLink 的 ATS。
N.1.7. Hardware Coherency
第二代 NVLink 允许从 CPU 直接加载/存储/原子访问每个 GPU 的内存。结合新的 CPU 主控功能,NVLink 支持一致性操作,允许从 GPU 内存读取的数据存储在 CPU 的缓存层次结构中。从 CPU 缓存访问的较低延迟是 CPU 性能的关键。计算能力 6.x 的设备仅支持对等 GPU 原子。计算能力 7.x 的设备可以通过 NVLink 发送 GPU 原子并在目标 CPU 上完成它们,因此第二代 NVLink 增加了对由 GPU 或 CPU 发起的原子的支持。
请注意,CPU 无法访问 cudaMalloc 分配。因此,要利用硬件一致性,用户必须使用统一内存分配器,例如 cudaMallocManaged 或支持 ATS 的系统分配器(请参阅系统分配器)。新属性 directManagedMemAccessFromHost 指示主机是否可以直接访问设备上的托管内存而无需迁移。默认情况下,驻留在 GPU 内存中的 cudaMallocManaged 分配的任何 CPU 访问都会触发页面错误和数据迁移。应用程序可以使用带有 cudaCpuDeviceId 的 cudaMemAdviseSetAccessedBy 性能提示来启用对受支持系统上 GPU 内存的直接访问。
考虑下面的示例代码:
__global__ void write(int *ret, int a, int b) {
ret[threadIdx.x] = a + b + threadIdx.x;
}
__global__ void append(int *ret, int a, int b) {
ret[threadIdx.x] += a + b + threadIdx.x;
}
int main() {
int *ret;
cudaMallocManaged(&ret, 1000 * sizeof(int));
cudaMemAdvise(ret, 1000 * sizeof(int), cudaMemAdviseSetAccessedBy, cudaCpuDeviceId); // set direct access hint
write<<< 1, 1000 >>>(ret, 10, 100); // pages populated in GPU memory
cudaDeviceSynchronize();
for(int i = 0; i < 1000; i++)
printf("%d: A+B = %d\n", i, ret[i]); // directManagedMemAccessFromHost=1: CPU accesses GPU memory directly without migrations
// directManagedMemAccessFromHost=0: CPU faults and triggers device-to-host migrations
append<<< 1, 1000 >>>(ret, 10, 100); // directManagedMemAccessFromHost=1: GPU accesses GPU memory without migrations
cudaDeviceSynchronize(); // directManagedMemAccessFromHost=0: GPU faults and triggers host-to-device migrations
cudaFree(ret);
return 0;
}
写内核完成后,会在GPU内存中创建并初始化ret。 接下来,CPU 将访问 ret,然后再次使用相同的 ret 内存追加内核。 此代码将根据系统架构和硬件一致性支持显示不同的行为:
- 在
directManagedMemAccessFromHost=1的系统上:CPU 访问托管缓冲区不会触发任何迁移; 数据将保留在 GPU 内存中,任何后续的 GPU 内核都可以继续直接访问它,而不会造成故障或迁移。 - 在
directManagedMemAccessFromHost=0的系统上:CPU 访问托管缓冲区将出现页面错误并启动数据迁移; 任何第一次尝试访问相同数据的 GPU 内核都会出现页面错误并将页面迁移回 GPU 内存。
N.1.8. Access Counters
计算能力 7.0 的设备引入了一个新的访问计数器功能,该功能可以跟踪 GPU 对位于其他处理器上的内存进行的访问频率。 访问计数器有助于确保将内存页面移动到最频繁访问页面的处理器的物理内存中。 访问计数器功能可以指导 CPU 和 GPU 之间以及对等 GPU 之间的迁移。
对于 cudaMallocManaged,访问计数器迁移可以通过使用带有相应设备 ID 的 cudaMemAdviseSetAccessedBy 提示来选择加入。 驱动程序还可以使用访问计数器来实现更有效的抖动缓解或内存超额订阅方案。
注意:访问计数器当前仅在 IBM Power9 系统上启用,并且仅用于 cudaMallocManaged 分配器。
N.2. Programming Model
N.2.1. Managed Memory Opt In
大多数平台要求程序通过使用 __managed__ 关键字注释 __device__ 变量(请参阅语言集成部分)或使用新的 cudaMallocManaged() 调用来分配数据来选择自动数据管理。
计算能力低于 6.x 的设备必须始终在堆上分配托管内存,无论是使用分配器还是通过声明全局存储。 无法将先前分配的内存与统一内存相关联,也无法让统一内存系统管理 CPU 或 GPU 堆栈指针。
从 CUDA 8.0 和具有计算能力 6.x 设备的支持系统开始,可以使用相同的指针从 GPU 代码和 CPU 代码访问使用默认 OS 分配器(例如 malloc 或 new)分配的内存。 在这些系统上,统一内存是默认设置:无需使用特殊分配器或创建专门管理的内存池。
N.2.1.1. Explicit Allocation Using cudaMallocManaged()
统一内存最常使用在语义和语法上类似于标准 CUDA 分配器 cudaMalloc() 的分配函数创建。 功能说明如下:
cudaError_t cudaMallocManaged(void **devPtr,
size_t size,
unsigned int flags=0);
cudaMallocManaged() 函数保留托管内存的 size 字节,并在 devPtr 中返回一个指针。 请注意各种 GPU 架构之间 cudaMallocManaged() 行为的差异。 默认情况下,计算能力低于 6.x 的设备直接在 GPU 上分配托管内存。 但是,计算能力 6.x 及更高版本的设备在调用 cudaMallocManaged() 时不会分配物理内存:在这种情况下,物理内存会在第一次触摸时填充,并且可能驻留在 CPU 或 GPU 上。 托管指针在系统中的所有 GPU 和 CPU 上都有效,尽管程序访问此指针必须遵守统一内存编程模型的并发规则(请参阅一致性和并发性)。 下面是一个简单的例子,展示了 cudaMallocManaged() 的使用:
__global__ void printme(char *str) {
printf(str);
}
int main() {
// Allocate 100 bytes of memory, accessible to both Host and Device code
char *s;
cudaMallocManaged(&s, 100);
// Note direct Host-code use of "s"
strncpy(s, "Hello Unified Memory\n", 99);
// Here we pass "s" to a kernel without explicitly copying
printme<<< 1, 1 >>>(s);
cudaDeviceSynchronize();
// Free as for normal CUDA allocations
cudaFree(s);
return 0;
}
当 cudaMalloc() 被 cudaMallocManaged() 替换时,程序的行为在功能上没有改变; 但是,该程序应该继续消除显式内存拷贝并利用自动迁移。 此外,可以消除双指针(一个指向主机,一个指向设备存储器)。
设备代码无法调用 cudaMallocManaged()。 所有托管内存必须从主机或全局范围内分配(请参阅下一节)。 在内核中使用 malloc() 在设备堆上的分配不会在托管内存空间中创建,因此 CPU 代码将无法访问。
N.2.1.2. Global-Scope Managed Variables Using managed
文件范围和全局范围的 CUDA __device__ 变量也可以通过在声明中添加新的 __managed__ 注释来选择加入统一内存管理。 然后可以直接从主机或设备代码中引用它们,如下所示:
__device__ __managed__ int x[2];
__device__ __managed__ int y;
__global__ void kernel() {
x[1] = x[0] + y;
}
int main() {
x[0] = 3;
y = 5;
kernel<<< 1, 1 >>>();
cudaDeviceSynchronize();
printf("result = %d\n", x[1]);
return 0;
}
原始 __device__ 内存空间的所有语义,以及一些额外的统一内存特定约束,都由托管变量继承(请参阅使用 NVCC 编译)。
请注意,标记为 __constant__ 的变量可能不会也标记为 __managed__; 此注释仅用于 __device__ 变量。 常量内存必须在编译时静态设置,或者在 CUDA 中像往常一样使用 cudaMemcpyToSymbol() 设置。
N.2.2. Coherency and Concurrency
在计算能力低于 6.x 的设备上同时访问托管内存是不可能的,因为如果 CPU 在 GPU 内核处于活动状态时访问统一内存分配,则无法保证一致性。 但是,支持操作系统的计算能力 6.x 的设备允许 CPU 和 GPU 通过新的页面错误机制同时访问统一内存分配。 程序可以通过检查新的 concurrentManagedAccess 属性来查询设备是否支持对托管内存的并发访问。 请注意,与任何并行应用程序一样,开发人员需要确保正确同步以避免处理器之间的数据危险。
N.2.2.1. GPU Exclusive Access To Managed Memory
为了确保 6.x 之前的 GPU 架构的一致性,统一内存编程模型在 CPU 和 GPU 同时执行时对数据访问施加了限制。实际上,GPU 在执行任何内核操作时对所有托管数据具有独占访问权,无论特定内核是否正在积极使用数据。当托管数据与 cudaMemcpy*() 或 cudaMemset*() 一起使用时,系统可能会选择从主机或设备访问源或目标,这将限制并发 CPU 访问该数据,而 cudaMemcpy*()或 cudaMemset*() 正在执行。有关更多详细信息,请参阅使用托管内存的 Memcpy()/Memset() 行为。
不允许 CPU 访问任何托管分配或变量,而 GPU 对 concurrentManagedAccess 属性设置为 0 的设备处于活动状态。在这些系统上,并发 CPU/GPU 访问,即使是不同的托管内存分配,也会导致分段错误,因为该页面被认为是 CPU 无法访问的。
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
kernel<<< 1, 1 >>>();
y = 20; // Error on GPUs not supporting concurrent access
cudaDeviceSynchronize();
return 0;
}
在上面的示例中,当 CPU 接触(这里原文中用的是touch这个词) y 时,GPU 程序内核仍然处于活动状态。 (注意它是如何在 cudaDeviceSynchronize() 之前发生的。)由于 GPU 页面错误功能解除了对同时访问的所有限制,因此代码在计算能力 6.x 的设备上成功运行。 但是,即使 CPU 访问的数据与 GPU 不同,这种内存访问在 6.x 之前的架构上也是无效的。 程序必须在访问 y 之前显式地与 GPU 同步:
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
kernel<<< 1, 1 >>>();
cudaDeviceSynchronize();
y = 20; // Success on GPUs not supporing concurrent access
return 0;
}
如本例所示,在具有 6.x 之前的 GPU 架构的系统上,CPU 线程可能不会在执行内核启动和后续同步调用之间访问任何托管数据,无论 GPU 内核是否实际接触相同的数据(或 任何托管数据)。 并发 CPU 和 GPU 访问的潜力足以引发进程级异常。
请注意,如果在 GPU 处于活动状态时使用 cudaMallocManaged() 或 cuMemAllocManaged() 动态分配内存,则在启动其他工作或同步 GPU 之前,内存的行为是未指定的。 在此期间尝试访问 CPU 上的内存可能会也可能不会导致分段错误。 这不适用于使用标志 cudaMemAttachHost 或 CU_MEM_ATTACH_HOST 分配的内存。
N.2.2.2. Explicit Synchronization and Logical GPU Activity
请注意,即使内核快速运行并在上例中的 CPU 接触 y 之前完成,也需要显式同步。统一内存使用逻辑活动来确定 GPU 是否空闲。这与 CUDA 编程模型一致,该模型指定内核可以在启动后的任何时间运行,并且不保证在主机发出同步调用之前完成。
任何在逻辑上保证 GPU 完成其工作的函数调用都是有效的。这包括 cudaDeviceSynchronize(); cudaStreamSynchronize() 和 cudaStreamQuery()(如果它返回 cudaSuccess 而不是 cudaErrorNotReady),其中指定的流是唯一仍在 GPU 上执行的流; cudaEventSynchronize() 和 cudaEventQuery() 在指定事件之后没有任何设备工作的情况下;以及记录为与主机完全同步的 cudaMemcpy() 和 cudaMemset() 的使用。
将遵循流之间创建的依赖关系,通过在流或事件上同步来推断其他流的完成。依赖关系可以通过 cudaStreamWaitEvent() 或在使用默认 (NULL) 流时隐式创建。
CPU 从流回调中访问托管数据是合法的,前提是 GPU 上没有其他可能访问托管数据的流处于活动状态。此外,没有任何设备工作的回调可用于同步:例如,通过从回调内部发出条件变量的信号;否则,CPU 访问仅在回调期间有效。
有几个重要的注意点:
- 在 GPU 处于活动状态时,始终允许 CPU 访问非托管零拷贝数据。
- GPU 在运行任何内核时都被认为是活动的,即使该内核不使用托管数据。如果内核可能使用数据,则禁止访问,除非设备属性
concurrentManagedAccess为 1。 - 除了适用于非托管内存的多 GPU 访问之外,托管内存的并发 GPU 间访问没有任何限制。
- 并发 GPU 内核访问托管数据没有任何限制。
请注意最后一点如何允许 GPU 内核之间的竞争,就像当前非托管 GPU 内存的情况一样。如前所述,从 GPU 的角度来看,托管内存的功能与非托管内存相同。以下代码示例说明了这些要点:
int main() {
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
int *non_managed, *managed, *also_managed;
cudaMallocHost(&non_managed, 4); // Non-managed, CPU-accessible memory
cudaMallocManaged(&managed, 4);
cudaMallocManaged(&also_managed, 4);
// Point 1: CPU can access non-managed data.
kernel<<< 1, 1, 0, stream1 >>>(managed);
*non_managed = 1;
// Point 2: CPU cannot access any managed data while GPU is busy,
// unless concurrentManagedAccess = 1
// Note we have not yet synchronized, so "kernel" is still active.
*also_managed = 2; // Will issue segmentation fault
// Point 3: Concurrent GPU kernels can access the same data.
kernel<<< 1, 1, 0, stream2 >>>(managed);
// Point 4: Multi-GPU concurrent access is also permitted.
cudaSetDevice(1);
kernel<<< 1, 1 >>>(managed);
return 0;
}
N.2.2.3. Managing Data Visibility and Concurrent CPU + GPU Access with Streams
到目前为止,假设对于 6.x 之前的 SM 架构:1) 任何活动内核都可以使用任何托管内存,以及 2) 在内核处于活动状态时使用来自 CPU 的托管内存是无效的。在这里,我们提出了一个用于对托管内存进行更细粒度控制的系统,该系统旨在在所有支持托管内存的设备上工作,包括 concurrentManagedAccess 等于 0 的旧架构。
CUDA 编程模型提供流作为程序指示内核启动之间的依赖性和独立性的机制。启动到同一流中的内核保证连续执行,而启动到不同流中的内核允许并发执行。流描述了工作项之间的独立性,因此可以通过并发实现更高的效率。
统一内存建立在流独立模型之上,允许 CUDA 程序显式地将托管分配与 CUDA 流相关联。通过这种方式,程序员根据内核是否将数据启动到指定的流中来指示内核对数据的使用。这为基于程序特定数据访问模式的并发提供了机会。控制这种行为的函数是:
cudaError_t cudaStreamAttachMemAsync(cudaStream_t stream,
void *ptr,
size_t length=0,
unsigned int flags=0);
cudaStreamAttachMemAsync() 函数将从 ptr 开始的内存长度字节与指定的流相关联。 (目前,length 必须始终为 0 以指示应该附加整个区域。)由于这种关联,只要流中的所有操作都已完成,统一内存系统就允许 CPU 访问该内存区域,而不管其他流是否是活跃的。实际上,这将活动 GPU 对托管内存区域的独占所有权限制为每个流活动而不是整个 GPU 活动。
最重要的是,如果分配与特定流无关,则所有正在运行的内核都可以看到它,而不管它们的流如何。这是 cudaMallocManaged() 分配或 __managed__ 变量的默认可见性;因此,在任何内核运行时 CPU 不得接触数据的简单案例规则。
通过将分配与特定流相关联,程序保证只有启动到该流中的内核才会接触该数据。统一内存系统不执行错误检查:程序员有责任确保兑现保证。
除了允许更大的并发性之外,使用 cudaStreamAttachMemAsync() 可以(并且通常会)启用统一内存系统内的数据传输优化,这可能会影响延迟和其他开销。
N.2.2.4. Stream Association Examples
将数据与流相关联允许对 CPU + GPU 并发进行细粒度控制,但在使用计算能力低于 6.x 的设备时,必须牢记哪些数据对哪些流可见。 查看前面的同步示例:
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
cudaStream_t stream1;
cudaStreamCreate(&stream1);
cudaStreamAttachMemAsync(stream1, &y, 0, cudaMemAttachHost);
cudaDeviceSynchronize(); // Wait for Host attachment to occur.
kernel<<< 1, 1, 0, stream1 >>>(); // Note: Launches into stream1.
y = 20; // Success – a kernel is running but “y”
// has been associated with no stream.
return 0;
}
在这里,我们明确地将 y 与主机可访问性相关联,从而始终可以从 CPU 进行访问。 (和以前一样,请注意在访问之前没有 cudaDeviceSynchronize()。)GPU 运行内核对 y 的访问现在将产生未定义的结果。
请注意,将变量与流关联不会更改任何其他变量的关联。 例如。 将 x 与 stream1 关联并不能确保在 stream1 中启动的内核只能访问 x,因此此代码会导致错误:
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
cudaStream_t stream1;
cudaStreamCreate(&stream1);
cudaStreamAttachMemAsync(stream1, &x);// Associate “x” with stream1.
cudaDeviceSynchronize(); // Wait for “x” attachment to occur.
kernel<<< 1, 1, 0, stream1 >>>(); // Note: Launches into stream1.
y = 20; // ERROR: “y” is still associated globally
// with all streams by default
return 0;
}
请注意访问 y 将如何导致错误,因为即使 x 已与流相关联,我们也没有告诉系统谁可以看到 y。 因此,系统保守地假设内核可能会访问它并阻止 CPU 这样做。
N.2.2.5. Stream Attach With Multithreaded Host Programs
cudaStreamAttachMemAsync() 的主要用途是使用 CPU 线程启用独立任务并行性。 通常在这样的程序中,CPU 线程为它生成的所有工作创建自己的流,因为使用 CUDA 的 NULL 流会导致线程之间的依赖关系。
托管数据对任何 GPU 流的默认全局可见性使得难以避免多线程程序中 CPU 线程之间的交互。 因此,函数 cudaStreamAttachMemAsync() 用于将线程的托管分配与该线程自己的流相关联,并且该关联通常在线程的生命周期内不会更改。
这样的程序将简单地添加一个对 cudaStreamAttachMemAsync() 的调用,以使用统一内存进行数据访问:
// This function performs some task, in its own private stream.
void run_task(int *in, int *out, int length) {
// Create a stream for us to use.
cudaStream_t stream;
cudaStreamCreate(&stream);
// Allocate some managed data and associate with our stream.
// Note the use of the host-attach flag to cudaMallocManaged();
// we then associate the allocation with our stream so that
// our GPU kernel launches can access it.
int *data;
cudaMallocManaged((void **)&data, length, cudaMemAttachHost);
cudaStreamAttachMemAsync(stream, data);
cudaStreamSynchronize(stream);
// Iterate on the data in some way, using both Host & Device.
for(int i=0; i<N; i++) {
transform<<< 100, 256, 0, stream >>>(in, data, length);
cudaStreamSynchronize(stream);
host_process(data, length); // CPU uses managed data.
convert<<< 100, 256, 0, stream >>>(out, data, length);
}
cudaStreamSynchronize(stream);
cudaStreamDestroy(stream);
cudaFree(data);
}
在这个例子中,分配流关联只建立一次,然后主机和设备都重复使用数据。 结果是比在主机和设备之间显式复制数据时更简单的代码,尽管结果是相同的。
N.2.2.6. Advanced Topic: Modular Programs and Data Access Constraints
在前面的示例中,cudaMallocManaged() 指定了 cudaMemAttachHost 标志,它创建了一个最初对设备端执行不可见的分配。 (默认分配对所有流上的所有 GPU 内核都是可见的。)这可确保在数据分配和为特定流获取数据之间的时间间隔内,不会与另一个线程的执行发生意外交互。
如果没有这个标志,如果另一个线程启动的内核恰好正在运行,则新分配将被视为在 GPU 上使用。这可能会影响线程在能够将其显式附加到私有流之前从 CPU 访问新分配的数据的能力(例如,在基类构造函数中)。因此,为了启用线程之间的安全独立性,应指定此标志进行分配。
注意:另一种方法是在分配附加到流之后在所有线程上放置一个进程范围的屏障。这将确保所有线程在启动任何内核之前完成其数据/流关联,从而避免危险。在销毁流之前需要第二个屏障,因为流销毁会导致分配恢复到其默认可见性。 cudaMemAttachHost 标志的存在既是为了简化此过程,也是因为并非总是可以在需要的地方插入全局屏障。
N.2.2.7. Memcpy()/Memset() Behavior With Managed Memory
由于可以从主机或设备访问托管内存,因此 cudaMemcpy*() 依赖于使用 cudaMemcpyKind 指定的传输类型来确定数据应该作为主机指针还是设备指针访问。
如果指定了 cudaMemcpyHostTo* 并且管理了源数据,那么如果在复制流 (1) 中可以从主机连贯地访问它,那么它将从主机访问;否则将从设备访问。当指定 cudaMemcpy*ToHost 并且目标是托管内存时,类似的规则适用于目标。
如果指定了 cudaMemcpyDeviceTo* 并管理源数据,则将从设备访问它。源必须可以从复制流中的设备连贯地访问 (2);否则,返回错误。当指定 cudaMemcpy*ToDevice 并且目标是托管内存时,类似的规则适用于目标。
如果指定了 cudaMemcpyDefault,则如果无法从复制流中的设备一致地访问托管数据 (2),或者如果数据的首选位置是 cudaCpuDeviceId 并且可以从主机一致地访问,则将从主机访问托管数据在复制流 (1) 中;否则,它将从设备访问。
将 cudaMemset*() 与托管内存一起使用时,始终从设备访问数据。数据必须可以从用于 cudaMemset() 操作的流中的设备连贯地访问 (2);否则,返回错误。
当通过 cudaMemcpy* 或 cudaMemset* 从设备访问数据时,操作流被视为在 GPU 上处于活动状态。在此期间,如果 GPU 的设备属性 concurrentManagedAccess 为零值,则任何与该流相关联的数据或具有全局可见性的数据的 CPU 访问都将导致分段错误。在从 CPU 访问任何相关数据之前,程序必须适当同步以确保操作已完成。
(1) 要在给定流中从主机连贯地访问托管内存,必须至少满足以下条件之一:
- 给定流与设备属性
concurrentManagedAccess具有非零值的设备相关联。 - 内存既不具有全局可见性,也不与给定流相关联。
(2) 要在给定流中从设备连贯地访问托管内存,必须至少满足以下条件之一:
- 设备的设备属性
concurrentManagedAccess具有非零值。 - 内存要么具有全局可见性,要么与给定的流相关联。
###N.2.3. Language Integration
使用 nvcc 编译主机代码的 CUDA 运行时 API 用户可以访问其他语言集成功能,例如共享符号名称和通过 <<<...>>> 运算符启动内联内核。 统一内存为 CUDA 的语言集成添加了一个附加元素:使用 __managed__ 关键字注释的变量可以直接从主机和设备代码中引用。
下面的例子在前面的 Simplifying GPU Programming 中看到,说明了 __managed__ 全局声明的简单使用:
// Managed variable declaration is an extra annotation with __device__
__device__ __managed__ int x;
__global__ void kernel() {
// Reference "x" directly - it's a normal variable on the GPU.
printf( "GPU sees: x = %d\n" , x);
}
int main() {
// Set "x" from Host code. Note it's just a normal variable on the CPU.
x = 1234;
// Launch a kernel which uses "x" from the GPU.
kernel<<< 1, 1 >>>();
cudaDeviceSynchronize();
return 0;
}
__managed__ 变量的可用功能是该符号在设备代码和主机代码中都可用,而无需取消引用指针,并且数据由所有人共享。这使得在主机和设备程序之间交换数据变得特别容易,而无需显式分配或复制。
从语义上讲,__managed__ 变量的行为与通过 cudaMallocManaged() 分配的存储相同。有关详细说明,请参阅使用 cudaMallocManaged() 进行显式分配。流可见性默认为 cudaMemAttachGlobal,但可以使用 cudaStreamAttachMemAsync() 进行限制。
__managed__ 变量的正确操作需要有效的 CUDA 上下文。如果当前设备的上下文尚未创建,则访问 __managed__ 变量可以触发 CUDA 上下文创建。在上面的示例中,在内核启动之前访问 x 会触发设备 0 上的上下文创建。如果没有该访问,内核启动将触发上下文创建。
声明为 __managed__ 的 C++ 对象受到某些特定约束,尤其是在涉及静态初始化程序的情况下。有关这些约束的列表,请参阅 CUDA C++ 编程指南中的 C++ 语言支持。
N.2.3.1. Host Program Errors with managed Variables
__managed__ 变量的使用取决于底层统一内存系统是否正常运行。 例如,如果 CUDA 安装失败或 CUDA 上下文创建不成功,则可能会出现不正确的功能。
当特定于 CUDA 的操作失败时,通常会返回一个错误,指出失败的根源。 使用 __managed__ 变量引入了一种新的故障模式,如果统一内存系统运行不正确,非 CUDA 操作(例如,CPU 访问应该是有效的主机内存地址)可能会失败。 这种无效的内存访问不能轻易地归因于底层的 CUDA 子系统,尽管诸如 cuda-gdb 之类的调试器会指示托管内存地址是故障的根源。
N.2.4. Querying Unified Memory Support
N.2.4.1. Device Properties
统一内存仅在具有 3.0 或更高计算能力的设备上受支持。程序可以通过使用 cudaGetDeviceProperties() 并检查新的 managedMemory 属性来查询 GPU 设备是否支持托管内存。也可以使用具有属性 cudaDevAttrManagedMemory 的单个属性查询函数 cudaDeviceGetAttribute() 来确定能力。
如果在 GPU 和当前操作系统下允许托管内存分配,则任一属性都将设置为 1。请注意,32 位应用程序不支持统一内存(除非在 Android 上),即使 GPU 有足够的能力。
支持平台上计算能力 6.x 的设备无需调用 cudaHostRegister 即可访问可分页内存。应用程序可以通过检查新的 pageableMemoryAccess 属性来查询设备是否支持连贯访问可分页内存。
通过新的缺页机制,统一内存保证了全局数据的一致性。这意味着 CPU 和 GPU 可以同时访问统一内存分配。这在计算能力低于 6.x 的设备上是非法的,因为如果 CPU 在 GPU 内核处于活动状态时访问统一内存分配,则无法保证一致性。程序可以通过检查 concurrentManagedAccess 属性来查询并发访问支持。有关详细信息,请参阅一致性和并发性。
N.2.5. Advanced Topics
N.2.5.1. Managed Memory with Multi-GPU Programs on pre-6.x Architectures
在计算能力低于 6.x 的设备的系统上,托管分配通过 GPU 的对等能力自动对系统中的所有 GPU 可见。
在 Linux 上,只要程序正在使用的所有 GPU 都具有点对点支持,托管内存就会在 GPU 内存中分配。如果在任何时候应用程序开始使用不支持对等支持的 GPU 与任何其他对其进行了托管分配的 GPU,则驱动程序会将所有托管分配迁移到系统内存。
在 Windows 上,如果对等映射不可用(例如,在不同架构的 GPU 之间),那么系统将自动回退到使用零拷贝内存,无论两个 GPU 是否都被程序实际使用。如果实际只使用一个 GPU,则需要在启动程序之前设置 CUDA_VISIBLE_DEVICES 环境变量。这限制了哪些 GPU 是可见的,并允许在 GPU 内存中分配托管内存。
或者,在 Windows 上,用户还可以将 CUDA_MANAGED_FORCE_DEVICE_ALLOC 设置为非零值,以强制驱动程序始终使用设备内存进行物理存储。当此环境变量设置为非零值时,该进程中使用的所有支持托管内存的设备必须彼此对等兼容。如果使用支持托管内存的设备并且它与之前在该进程中使用的任何其他托管内存支持设备不兼容,则将返回错误 ::cudaErrorInvalidDevice,即使 ::cudaDeviceReset 具有在这些设备上被调用。这些环境变量在附录 CUDA 环境变量中进行了描述。请注意,从 CUDA 8.0 开始,CUDA_MANAGED_FORCE_DEVICE_ALLOC 对 Linux 操作系统没有影响。
N.2.5.2. Using fork() with Managed Memory
统一内存系统不允许在进程之间共享托管内存指针。 它不会正确管理通过 fork() 操作复制的内存句柄。 如果子级或父级在 fork() 之后访问托管数据,则结果将不确定。
然而,fork() 一个子进程然后通过 exec() 调用立即退出是安全的,因为子进程丢弃了内存句柄并且父进程再次成为唯一的所有者。 父母离开并让孩子接触句柄是不安全的。
N.3. Performance Tuning
为了使用统一内存实现良好的性能,必须满足以下目标:
- 应避免错误:虽然可重放错误是启用更简单的编程模型的基础,但它们可能严重损害应用程序性能。故障处理可能需要几十微秒,因为它可能涉及 TLB 无效、数据迁移和页表更新。与此同时,应用程序某些部分的执行将停止,从而可能影响整体性能。
- 数据应该位于访问处理器的本地:如前所述,当数据位于访问它的处理器本地时,内存访问延迟和带宽明显更好。因此,应适当迁移数据以利用较低的延迟和较高的带宽。
- 应该防止内存抖动:如果数据被多个处理器频繁访问并且必须不断迁移以实现数据局部性,那么迁移的开销可能会超过局部性的好处。应尽可能防止内存抖动。如果无法预防,则必须进行适当的检测和解决。
为了达到与不使用统一内存相同的性能水平,应用程序必须引导统一内存驱动子系统避免上述陷阱。值得注意的是,统一内存驱动子系统可以检测常见的数据访问模式并自动实现其中一些目标,而无需应用程序参与。但是,当数据访问模式不明显时,来自应用程序的明确指导至关重要。 CUDA 8.0 引入了有用的 API,用于为运行时提供内存使用提示 (cudaMemAdvise()) 和显式预取 (cudaMemPrefetchAsync())。这些工具允许与显式内存复制和固定 API 相同的功能,而不会恢复到显式 GPU 内存分配的限制。
注意:Tegra 设备不支持 cudaMemPrefetchAsync()。
N.3.1. Data Prefetching
数据预取意味着将数据迁移到处理器的内存中,并在处理器开始访问该数据之前将其映射到该处理器的页表中。 数据预取的目的是在建立数据局部性的同时避免故障。 这对于在任何给定时间主要从单个处理器访问数据的应用程序来说是最有价值的。 由于访问处理器在应用程序的生命周期中发生变化,因此可以相应地预取数据以遵循应用程序的执行流程。 由于工作是在 CUDA 中的流中启动的,因此预计数据预取也是一种流操作,如以下 API 所示:
cudaError_t cudaMemPrefetchAsync(const void *devPtr,
size_t count,
int dstDevice,
cudaStream_t stream);
其中由 devPtr 指针和 count 字节数指定的内存区域,ptr 向下舍入到最近的页面边界,count 向上舍入到最近的页面边界,通过在流中排队迁移操作迁移到 dstDevice。 为 dstDevice 传入 cudaCpuDeviceId 会导致数据迁移到 CPU 内存。 考虑下面的一个简单代码示例:
void foo(cudaStream_t s) {
char *data;
cudaMallocManaged(&data, N);
init_data(data, N); // execute on CPU
cudaMemPrefetchAsync(data, N, myGpuId, s); // prefetch to GPU
mykernel<<<..., s>>>(data, N, 1, compare); // execute on GPU
cudaMemPrefetchAsync(data, N, cudaCpuDeviceId, s); // prefetch to CPU
cudaStreamSynchronize(s);
use_data(data, N);
cudaFree(data);
}
如果没有性能提示,内核 mykernel 将在首次访问数据时出错,这会产生额外的故障处理开销,并且通常会减慢应用程序的速度。 通过提前预取数据,可以避免页面错误并获得更好的性能。 此 API 遵循流排序语义,即迁移在流中的所有先前操作完成之前不会开始,并且流中的任何后续操作在迁移完成之前不会开始。
N.3.2. Data Usage Hints
当多个处理器需要同时访问相同的数据时,单独的数据预取是不够的。 在这种情况下,应用程序提供有关如何实际使用数据的提示很有用。 以下咨询 API 可用于指定数据使用情况:
cudaError_t cudaMemAdvise(const void *devPtr,
size_t count,
enum cudaMemoryAdvise advice,
int device);
其中,为从 devPtr 地址开始的区域中包含的数据指定的通知和计数字节的长度,四舍五入到最近的页面边界,可以采用以下值:
cudaMemAdviseSetReadMostly:这意味着数据大部分将被读取并且只是偶尔写入。 这允许驱动程序在处理器访问数据时在处理器内存中创建数据的只读拷贝。 同样,如果在此区域上调用cudaMemPrefetchAsync,它将在目标处理器上创建数据的只读拷贝。 当处理器写入此数据时,相应页面的所有副本都将失效,但发生写入的拷贝除外。 此建议忽略设备参数。 该建议允许多个处理器以最大带宽同时访问相同的数据,如以下代码片段所示:
char *dataPtr;
size_t dataSize = 4096;
// Allocate memory using malloc or cudaMallocManaged
dataPtr = (char *)malloc(dataSize);
// Set the advice on the memory region
cudaMemAdvise(dataPtr, dataSize, cudaMemAdviseSetReadMostly, 0);
int outerLoopIter = 0;
while (outerLoopIter < maxOuterLoopIter) {
// The data is written to in the outer loop on the CPU
initializeData(dataPtr, dataSize);
// The data is made available to all GPUs by prefetching.
// Prefetching here causes read duplication of data instead
// of data migration
for (int device = 0; device < maxDevices; device++) {
cudaMemPrefetchAsync(dataPtr, dataSize, device, stream);
}
// The kernel only reads this data in the inner loop
int innerLoopIter = 0;
while (innerLoopIter < maxInnerLoopIter) {
kernel<<<32,32>>>((const char *)dataPtr);
innerLoopIter++;
}
outerLoopIter++;
}
cudaMemAdviseSetPreferredLocation:此建议将数据的首选位置设置为属于设备的内存。传入设备的cudaCpuDeviceId值会将首选位置设置为 CPU 内存。设置首选位置不会导致数据立即迁移到该位置。相反,它会在该内存区域发生故障时指导迁移策略。如果数据已经在它的首选位置并且故障处理器可以建立映射而不需要迁移数据,那么迁移将被避免。另一方面,如果数据不在其首选位置,或者无法建立直接映射,那么它将被迁移到访问它的处理器。请务必注意,设置首选位置不会阻止使用cudaMemPrefetchAsync完成数据预取。cudaMemAdviseSetAccessedBy:这个advice意味着数据将被设备访问。这不会导致数据迁移,并且对数据本身的位置没有影响。相反,只要数据的位置允许建立映射,它就会使数据始终映射到指定处理器的页表中。如果数据因任何原因被迁移,映射会相应更新。此advice在数据局部性不重要但避免故障很重要的情况下很有用。例如,考虑一个包含多个启用对等访问的 GPU 的系统,其中位于一个 GPU 上的数据偶尔会被其他 GPU 访问。在这种情况下,将数据迁移到其他 GPU 并不那么重要,因为访问不频繁并且迁移的开销可能太高。但是防止故障仍然有助于提高性能,因此提前设置映射很有用。请注意,在 CPU 访问此数据时,由于 CPU 无法直接访问 GPU 内存,因此数据可能会迁移到 CPU 内存。任何为此数据设置了cudaMemAdviceSetAccessedBy标志的 GPU 现在都将更新其映射以指向 CPU 内存中的页面。
每个advice也可以使用以下值之一取消设置:cudaMemAdviseUnsetReadMostly、cudaMemAdviseUnsetPreferredLocation 和 cudaMemAdviseUnsetAccessedBy。
N.3.3. Querying Usage Attributes
程序可以使用以下 API 查询通过 cudaMemAdvise 或 cudaMemPrefetchAsync 分配的内存范围属性:
cudaMemRangeGetAttribute(void *data,
size_t dataSize,
enum cudaMemRangeAttribute attribute,
const void *devPtr,
size_t count);
此函数查询从 devPtr 开始的内存范围的属性,大小为 count 字节。内存范围必须引用通过 cudaMallocManaged 分配或通过 __managed__ 变量声明的托管内存。可以查询以下属性:
cudaMemRangeAttributeReadMostly:如果给定内存范围内的所有页面都启用了重复读取,则返回的结果将为 1,否则返回 0。cudaMemRangeAttributePreferredLocation:如果内存范围内的所有页面都将相应的处理器作为首选位置,则返回结果将是 GPU 设备 ID 或cudaCpuDeviceId,否则将返回cudaInvalidDeviceId。应用程序可以使用此查询 API 来决定通过 CPU 或 GPU 暂存数据,具体取决于托管指针的首选位置属性。请注意,查询时内存范围内页面的实际位置可能与首选位置不同。cudaMemRangeAttributeAccessedBy: 将返回为该内存范围设置了该建议的设备列表。cudaMemRangeAttributeLastPrefetchLocation:将返回使用cudaMemPrefetchAsync显式预取内存范围内所有页面的最后位置。请注意,这只是返回应用程序请求将内存范围预取到的最后一个位置。它没有指示对该位置的预取操作是否已经完成或什至开始。
此外,还可以使用对应的 cudaMemRangeGetAttributes 函数查询多个属性。