
训练自动语音识别( ASR )模型的损失函数并不是一成不变的。旧的损失函数规则不一定是最优的。考虑一下 connectionist temporal classification ( CTC ),看看改变它的一些规则如何能够减少 GPU 内存,这是训练和推断基于 CTC 的模型所需的内存,等等。
联结主义时间分类综述
若你们要训练一个 ASR 模型,无论是卷积神经网络还是递归神经网络、transformer 还是组合,你们很可能是用 CTC 损失训练它。
CTC 简单方便,因为它不需要每帧关于“什么声音何时发音”(所谓的音频文本时间对齐)的信息。在大多数情况下,这种知识是不可用的,就像在一个典型的 ASR 音频数据集中,关联文本没有时间标记。
真正的时间校准并不总是微不足道的。假设大部分录音没有讲话,结尾只有一个简短短语。 CTC 损失并不能告诉模型何时准确地发出预测。相反,它允许每一种可能的对齐,并且只调整这些对齐的形式。
下面是 CTC 如何管理所有可能的方式来将音频与文本对齐。
首先,对目标文本进行标记化,即将单词切成字母或单词片段。结果单元的数量(无论它们是什么)应小于音频“时间段”的数量:长度为 0.01 到 0.08 秒的音频段。
如果时间段少于单位,则算法失败。在这种情况下,你应该缩短时间。否则,只有 RNN 传感器可以挽救您。如果时间框架与单位一样多,那么只能有一个对齐(百万分之一的情况)。
大多数时候,时间段比单位要长得多,因此一些帧没有单位。对于这种空帧, CTC 有一个特殊的 单元。本单元告诉您,在这个特定的框架下,模型没有任何内容可以提供给您。这可能是因为没有演讲,或者模型太懒,无法预测有意义的东西。 CTC 最重要的规则 提供了如果模型不想做什么也不能预测的能力。
其他规则与单元延续有关。假设您的单元是一个持续时间超过一帧的元音。模型应在两帧中的哪一帧上输出单元? CTC 允许在多个连续帧上进行相同的单位发射。但是,应该将相同的连续单元合并为一个单元,以将识别结果转换为一系列类似文本的单元。
现在,如果标记化文本本身包含相同的重复单位,如“ ll ”或“ pp ”,该怎么办?如果不进行处理,这些单元将合并为一个单元,即使它们不应该合并。对于这种特殊情况, CTC 有一条规则,如果目标文本有重复的单位,那么在推理过程中这些单位必须用 分隔。
综上所述,在几乎每一帧中,模型都可以从上一帧 发射相同的单元,或者如果下一帧与上一帧不同,则可以发射下一个单元。这些规则比 规则更为复杂,对于反恐委员会来说,它们并不完全必要。
反恐委员会的执行
以下是如何表示 CTC 损失。与机器学习中的大多数损失函数一样,它通常表示为一个动态算法,将这些规则应用于训练语句或模型的 softmax 输出。
在训练中,损失值和梯度由适用于 CTC 规则的 Baum–Welch algorithm 根据所有可能路线的条件概率计算得出。 CTC 实现通常有数百到数千行代码,很难修改。
幸运的是,还有另一种执行反恐委员会的方法。除了其他应用领域外,加权有限状态传感器( WFST )方法允许模型将动态算法表示为一组图形和相关图形操作。这种方法使您能够通过将 CTC 规则应用于特定的音频和文本,并通过计算损失和梯度来解耦 CTC 规则。
CTC WFST 应用程序
有了 WFST ,您可以轻松地采用 CTC 规则,并使用不同的标准,如最大互信息( MMI )。这些模型通常具有比 CTC 模型更低的字错误率( WER )。 MMI 将先前的语言信息纳入培训过程。
与 CTC 相比, MMI 不仅最大化了最可行路径的概率,而且最小化了其他路径的概率。为此, MMI 有一个所谓的分母图,它可以在训练期间占用大量 GPU 内存。幸运的是,可以修改一些 CTC 规则以减少分母内存消耗,而不会影响语音识别的准确性。
此外, CTC 规则的 WFST 表示,或所谓的 topology ,可用于对 CTC 模型进行 WFST 解码。为此,您可以将 N -gram 语言模型转换为 WFST 图,并将其与拓扑图组合在一起。生成的解码图可以传递给,例如, Riva CUDA WFST Decoder 。
解码图可能很大,以至于无法放入 GPU 内存。但通过一些 CTC 拓扑修改,您可以减少 CTC 的解码图形大小。
CTC 拓扑
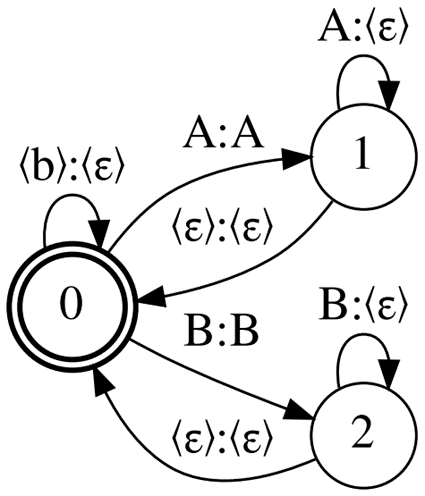
图 1 显示了 CTC 拓扑, Correct CTC 。这是一个带自循环的有向完整图,因此对于 N 单元(包括空白),有 N 状态和弧的平方数。
正确的反恐委员会是最常用的反恐委员会代表。看看这个拓扑产生的典型大小。对于 LibriSpeech 4 字语言模型和 256 个模型词汇单元,解码图大小为~ 16Gb 。对于型号词汇表大小为 2048 的 32Gb GPU ,仅当批次大小为 1 时,才可以进行冷启动 MMI 培训。

通过删除一些 CTC 规则来减少 Correct CTC 引起的内存消耗。首先,使用 删除重复单元的强制分隔。如果没有这个规则,您最终会得到一个名为 CompactCTC 的拓扑(图 2 )。它有 3 个 N – 2 个弧用于 N 单元。
尽管有纯
使用 Compact CTC 的解码图形大小比使用 Correct CTC 的小四分之一。它还需要 2x 更少的 GPU 内存用于 MMI 训练。
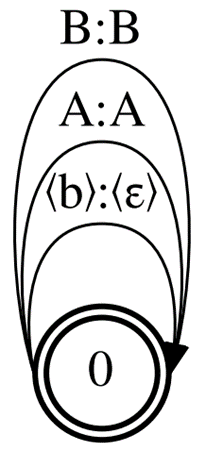
现在在多个连续帧上丢弃相同的单位发射,只保留 规则。这样,您得到的拓扑只有一个状态和 N 单元的 N 弧。
这是可能的最小 CTC 拓扑,所以我们称之为最小 CTC (图 3 )。它需要更少的 GPU 内存用于 MMI 训练(与 Correct CTC 相比减少了 4 倍),但与基线相比,使用 Minimal CTC 拓扑的 MMI 训练模型的精度会降低。
最小的拓扑还产生最小的解码 WFST ,其大小为基线图的一半。用 Minimal CTC 编译的解码图与用 Correct CTC 或 Compact CTC 构建的模型不兼容。
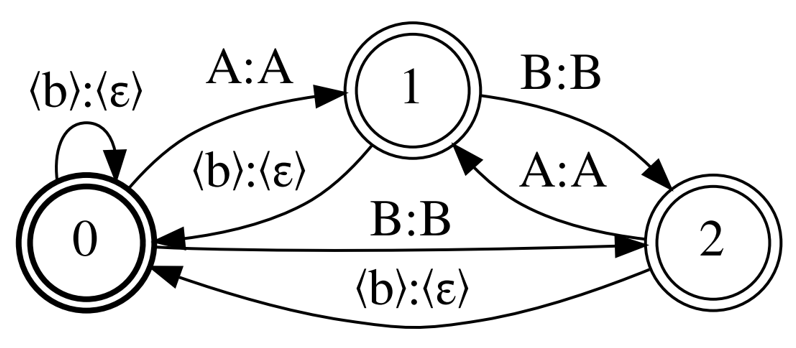
最后,我回到了 Correct CTC ,但这次离开了强制分离重复单元,并放弃了单元继续。名为 Selfless CTC 的拓扑结构旨在弥补 Minimal CTC 的缺点。
图 1 和图 4 显示, Correct CTC 和 Selfles CTC 仅在非 自我循环中有所不同。这两种拓扑结构还提供了相同的 MMI 模型精度,如果模型具有较长的上下文窗口,则可以提供更好的精度。然而, Selfless CTC 在解码时也与 Minimal CTC 兼容。通过 Minimal CTC ,您只需增加 0.2% 的 WER ,即可将图形大小减少 2 倍。
结论
有几个技巧可以提高性能:
- 在解码图构造和 MMI 训练中,使用 Compact CTC 代替 Correct CTC 。
- 为了最大程度地减小解码图形的大小,请使用 Selfles CTC 训练您的模型,并使用 Minimal CTC 解码。
- 损失函数不是一成不变的:尝试使用现有损失函数的 WFST 表示法并创建新的表示法。这很有趣!
有关更多信息,请参阅 CTC Variations Through New WFST Topologies 或查看 INTERSPEECH 会话。
其他有用资源:
- MMI training with NVIDIA NeMo
- A fast standalone WFST decoder that supports CTC models with different topologies
- 不同的 WFST 用于制作拓扑和其他:




