
使用微服务架构部署应用程序有几个优点:更容易进行主系统集成、更简单的测试和可重用的代码组件。 FastAPI 最近已成为 Python 中用于开发微服务的最流行的 web 框架之一。 FastAPI 比 Flask ( Python 中常用的 web 框架),因为它是基于 异步服务器网关接口( ASGI ) 而不是 Web 服务器网关接口( WSGI ) .
什么是微服务
微服务定义了构建软件应用程序的架构和组织方法。微服务的一个关键方面是它们是分布式的,并且具有松散耦合。实现更改不太可能破坏整个应用程序。
您还可以将使用微服务架构构建的应用程序视为由几个通过应用程序编程接口( API )通信的小型独立服务组成。通常,每个服务都由一个较小的、自包含的团队拥有,负责在必要时实现更改和更新。
使用微服务的一个主要好处是,它们使团队能够快速为其应用程序构建新组件。这对于与不断变化的业务需求保持一致至关重要。
另一个好处是它们使按需扩展应用程序变得多么简单。企业可以加快上市时间,以确保不断满足客户需求。
微服务和整体服务的区别
单片是另一种软件体系结构,它为设计软件应用程序提供了一种更传统、统一的结构。这里有一些不同之处。
微服务是解耦的
想想微服务如何将应用程序分解为其核心功能。每个功能都称为服务,并执行单个任务。
换句话说,服务可以独立构建和部署。这样做的好处是,单个服务在不影响其他服务的情况下工作。例如,如果一项服务比其他服务的需求更大,则可以独立扩展。
巨石是紧密耦合的
另一方面,整体架构是紧密耦合的,并作为单个服务运行。缺点是,当一个进程遇到需求高峰时,必须扩展整个应用程序,以防止该进程成为瓶颈。由于单个进程故障会影响整个应用程序,因此应用程序停机的风险也会增加。
对于单片架构,随着代码库的增长,更新或向应用程序添加新功能要复杂得多。这限制了实验的空间。
何时使用微服务或巨石?
这些差异并不一定意味着微服务比单一服务更好。在某些情况下,使用单体仍然更有意义,例如构建一个不需要太多业务逻辑、优异的可伸缩性或灵活性的小型应用程序。
然而,机器学习( ML )应用程序通常是具有许多运动部件的复杂系统,必须能够扩展以满足业务需求。通常需要为 ML 应用程序使用微服务架构。
包装机器学习模型
在我深入了解用于此微服务的体系结构的细节之前,有一个重要的步骤需要完成:模型打包。只有当 ML 模型的预测可以提供给最终用户时,您才能真正实现 ML 模型的价值。在大多数情况下,这意味着从笔记本电脑到脚本,以便将模型投入生产。
在本例中,将用于训练和预测新实例的脚本转换为 Python 包。软件包是编程的重要组成部分。没有它们,大部分开发时间都浪费在重写现有代码上。
为了更好地理解包是什么,从脚本开始,然后介绍模块要容易得多。
- 脚本:预期将直接运行的文件。每个脚本执行都执行开发人员定义的特定行为。创建脚本就像保存扩展名为.py 的文件以表示 Python 文件一样简单。
- 模块:为导入其他脚本或模块而创建的程序。一个模块通常由几个类和函数组成,这些类和函数用于其他文件。将模块视为代码的另一种方式是反复重用。
包可以被定义为相关模块的集合。这些模块以特定的方式相互作用,从而使您能够完成任务。在 Python 中,包通常通过 PyPi 并且可以使用 pip ,一个 Python 包安装程序。
对于这篇文章,捆绑 ML 模型。要遵循代码,请参见 kurtispykes/car-evaluation-project github 回购。
图 1 显示了该模型的目录结构。
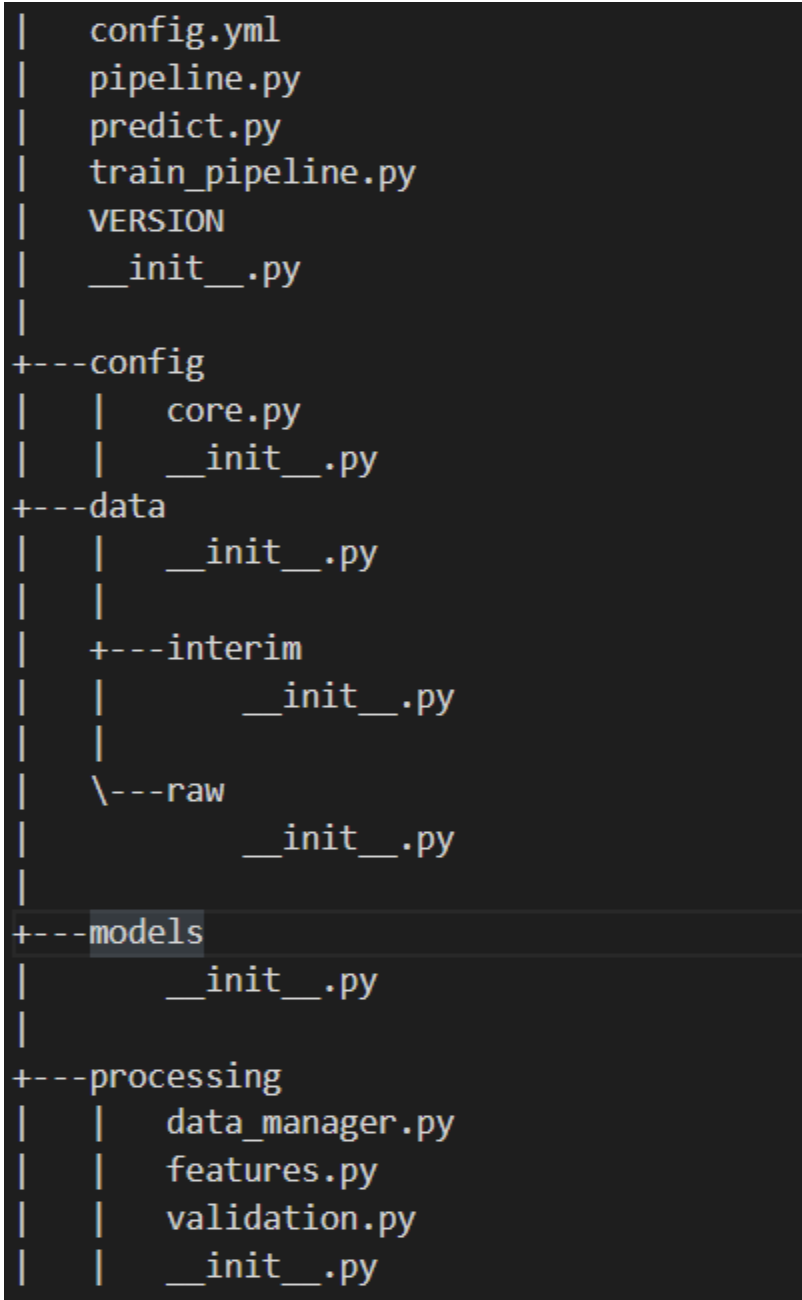
包模块包括以下内容:
- config.yml: YAML 文件以定义常量变量。
- pipeline.py:执行所有特征转换和建模的管道。
- predict.py:使用训练模型对新实例进行预测。
- train_pipeline.py:进行模型培训。
- 版本:当前版本。
- config/core.py:用于解析 YAML 文件的模块,以便可以在 Python 中访问常量变量。
- 资料/:用于项目的所有数据。
- 模型/:经过训练的序列化模型。
- processing/data_manager.py:用于数据管理的实用功能。
- processing/features.py:要在管道中使用的特征转换。
- processing/validation.py:数据验证架构。
该模型没有针对这个问题进行优化,因为本文的主要重点是展示如何使用微服务架构构建 ML 应用程序。
现在该模型已经准备好分发,但存在一个问题。通过 PyPi 索引分发包意味着它可以在全球范围内访问。对于模型中没有业务价值的场景,这可能是可以的。然而,在真实的业务场景中,这将是一场彻底的灾难。
您可以使用第三方工具,如 Gemfury 完成此操作的步骤超出了本文的范围。有关详细信息,请参阅 安装专用 Python 软件包 .
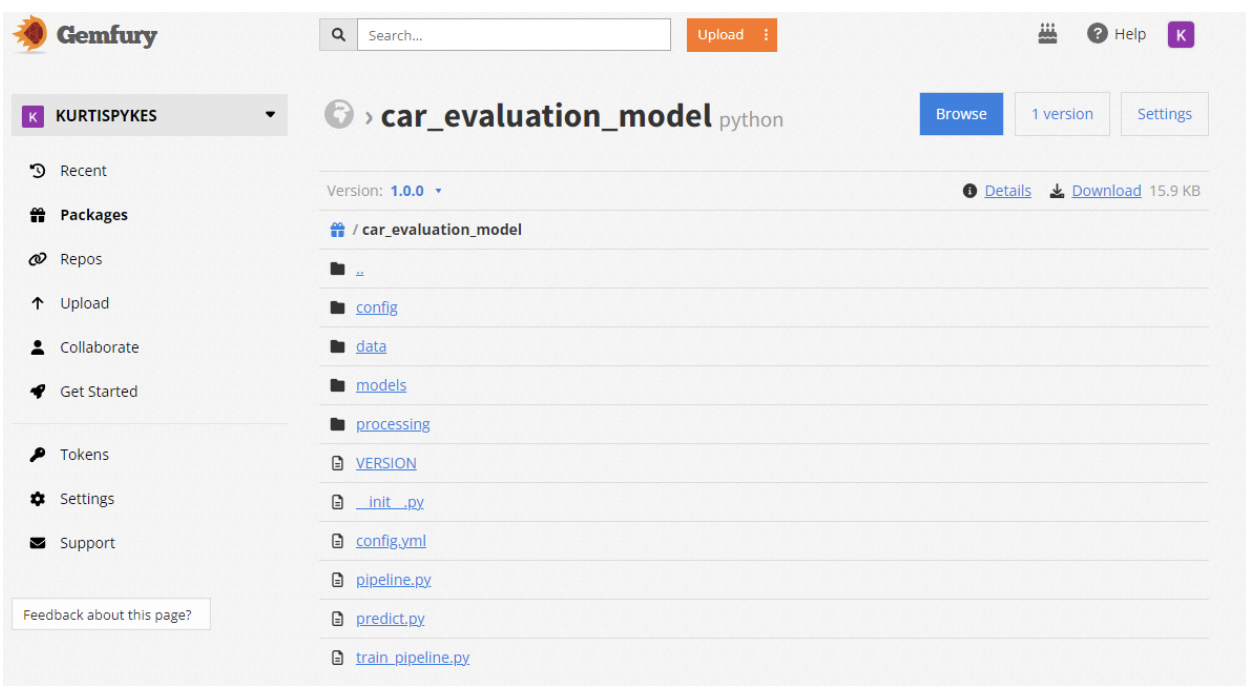
图 2 显示了我的 Gemfury 存储库中的私有打包模型。我做了这个 用于演示目的的包公开 .
微服务系统设计
在训练并保存模型后,您需要一种向最终用户提供预测的方法。 RESTAPI 是实现这一目标的好方法。有几种应用程序架构可用于集成 RESTAPI 。图 3 显示了我在本文中使用的嵌入式体系结构。
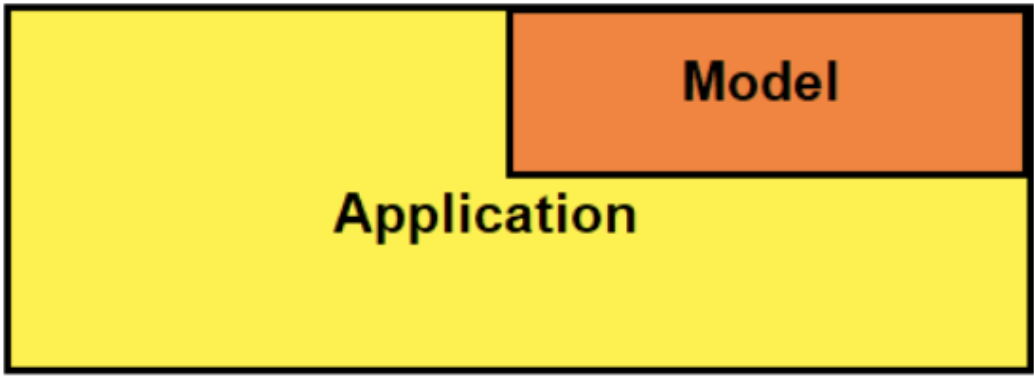
嵌入式体系结构指的是一个系统,其中训练的模型嵌入到 API 中并作为依赖项安装。
在简单性和灵活性之间有一个自然的权衡。嵌入式方法比其他方法简单得多,但灵活性较差。例如,每当进行模型更新时,必须重新部署整个应用程序。如果你的服务是在手机上提供的,那么你必须发布新版本的软件。
使用 FastAPI 构建 API
构建 API 时需要考虑的是依赖关系。您将不会创建虚拟环境,因为您正在使用运行应用程序 tox ,这是一个命令行驱动的自动化测试工具,也用于通用 虚拟人 经营因此,调用tox创建虚拟环境并运行应用程序。
尽管如此,以下是依赖项。
--extra-index-url="https://repo.fury.io/kurtispykes/" car-evaluation-model==1.0.0 uvicorn>=0.18.2, <0.19.0 fastapi>=0.79.0, <1.0.0 python-multipart>=0.0.5, <0.1.0 pydantic>=1.9.1, <1.10.0 typing_extensions>=3.10.0, <3.11.0 loguru>=0.6.0, <0.7.0
如果在 PyPI 中找不到包,pip还有一个额外的索引,用于搜索包。这是到托管打包模型的 Gemfury 帐户的公共链接,因此,您可以从 Gemfurry 安装经过训练的模型。这将是专业设置中的私有包,这意味着链接将被提取并隐藏在环境变量中。
另一件需要注意的事情是 uvicorn .Uvicorn 是实现 ASGI 接口的服务器网关接口。换句话说,它是一个专门的 web 服务器,负责处理入站和出站请求。它在Procfile中定义。
web: uvicorn app.main:app --host 0.0.0.0 --port $PORT
既然指定了依赖项,您就可以继续查看实际的应用程序了。 API 应用程序的主要部分是main.py脚本:
from typing import Any
from fastapi import APIRouter, FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import HTMLResponse
from loguru import logger
from app.api import api_router
from app.config import settings, setup_app_logging
# setup logging as early as possible
setup_app_logging(config=settings)
app = FastAPI(
title=settings.PROJECT_NAME, openapi_url=f"{settings.API_V1_STR}/openapi.json"
)
root_router = APIRouter()
@root_router.get("/")
def index(request: Request) -> Any:
"""Basic HTML response."""
body = (
"<html>"
"<body style='padding: 10px;'>"
"<h1>Welcome to the API</h1>"
"<div>"
"Check the docs: <a href='/docs'>here</a>"
"</div>"
"</body>"
"</html>"
)
return HTMLResponse(content=body)
app.include_router(api_router, prefix=settings.API_V1_STR)
app.include_router(root_router)
# Set all CORS enabled origins
if settings.BACKEND_CORS_ORIGINS:
app.add_middleware(
CORSMiddleware,
allow_origins=[str(origin) for origin in settings.BACKEND_CORS_ORIGINS],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
if __name__ == "__main__":
# Use this for debugging purposes only
logger.warning("Running in development mode. Do not run like this in production.")
import uvicorn # type: ignore
uvicorn.run(app, host="localhost", port=8001, log_level="debug")
如果你不能跟上,不要担心。需要注意的关键是,主应用程序中有两个路由器:
root_router:此端点定义返回 HTML 响应的主体。您几乎可以将其视为称为索引的主端点。api_router:此端点用于指定允许其他应用程序与 ML 模型交互的更复杂的端点。
深入了解api.py模块以更好地理解api_router。首先,本模块中定义了两个端点:health和predict。
看看代码示例:
@api_router.get("/health", response_model=schemas.Health, status_code=200)
def health() -> dict:
"""
Root Get
"""
health = schemas.Health(
name=settings.PROJECT_NAME, api_version=__version__, model_version=model_version
)
return health.dict()
@api_router.post("/predict", response_model=schemas.PredictionResults, status_code=200)
async def predict(input_data: schemas.MultipleCarTransactionInputData) -> Any:
"""
Make predictions with the Fraud detection model
"""
input_df = pd.DataFrame(jsonable_encoder(input_data.inputs))
# Advanced: You can improve performance of your API by rewriting the
# `make prediction` function to be async and using await here.
logger.info(f"Making prediction on inputs: {input_data.inputs}")
results = make_prediction(inputs=input_df.replace({np.nan: None}))
if results["errors"] is not None:
logger.warning(f"Prediction validation error: {results.get('errors')}")
raise HTTPException(status_code=400, detail=json.loads(results["errors"]))
logger.info(f"Prediction results: {results.get('predictions')}")
return results
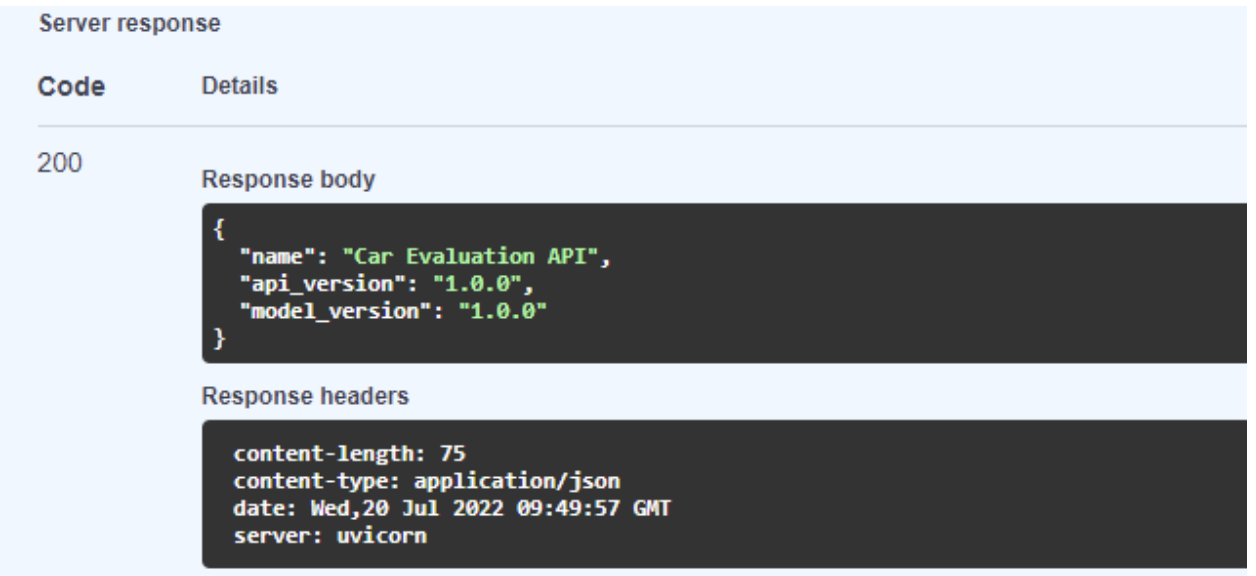
health端点非常简单。当您访问 web 服务器时,它返回模型的健康响应模式(图 4 )。您在schemas目录中的health.py模块中定义了此架构。
predict端点稍微复杂一些。以下是所涉及的步骤:
- 获取输入并将其转换为 pandas 数据帧 : jsonable_encoder 返回的 JSON 兼容版本 pydantic model.
- 记录输入数据以进行审计。
- 使用 ML 模型的
make_prediction函数进行预测。 - 捕获模型产生的任何错误。
- 如果模型没有错误,则返回结果。
通过从终端窗口使用以下命令启动服务器,检查所有功能是否正常:
py -m tox -e run
如果服务器正在运行,这将显示多个日志,如图 5 所示。
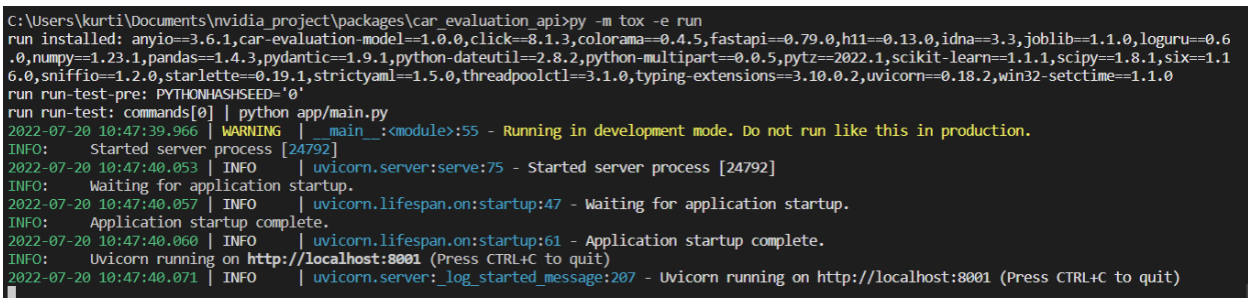
现在,您可以导航到 http://localhost:8001 查看 API 的交互端点。
测试微服务 API
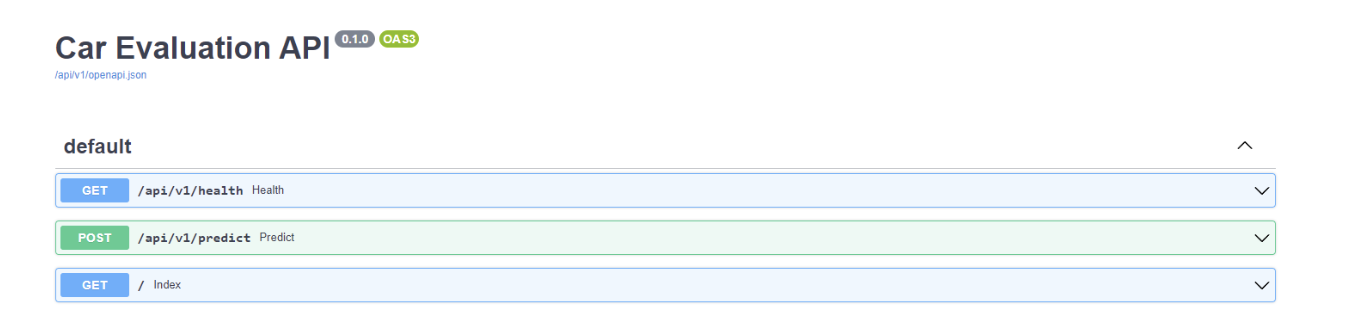
导航到本地服务器将从main.py脚本转到root_rooter中定义的索引端点。您可以通过在本地主机服务器 URL 的末尾添加/docs来获得有关 API 的更多信息。
例如,图 6 显示您已经将predict端点创建为 POST 请求,health端点是 GET 请求。
首先,展开predict标题以接收有关端点的信息。在本标题中,您将看到请求主体中的一个示例。我在其中一个模式中定义了这个示例,以便您可以测试 API 。这超出了本文的范围,但您可以浏览 模式代码 .
要在请求体示例中尝试该模型,请选择试试看.
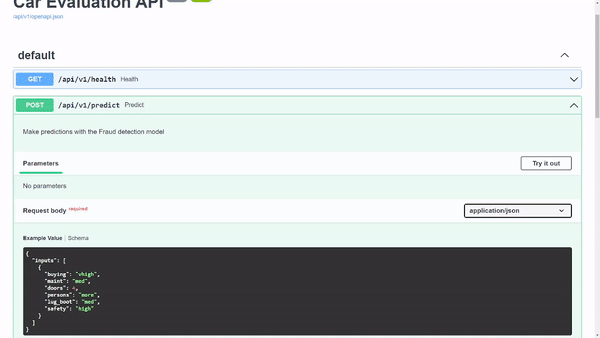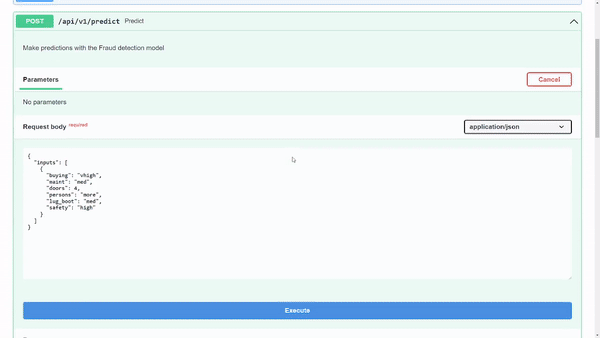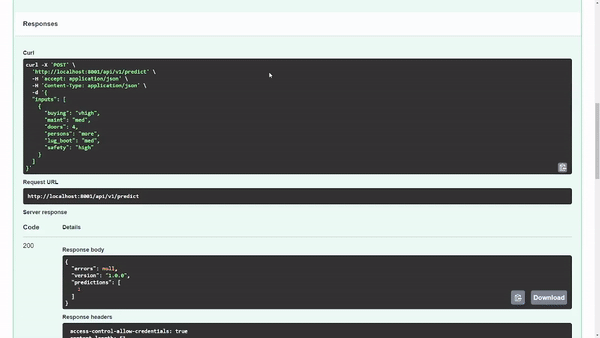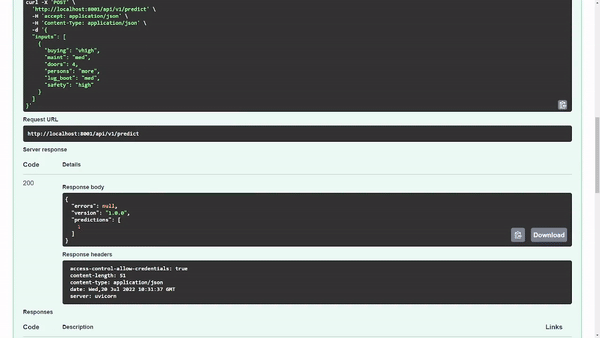
图 7 显示了模型返回的预测输出类为 1 。在内部,您知道 1 表示acc类值,但您可能希望在用户界面中显示时向用户显示该值。
下一步是什么?
恭喜您,您现在已经为微服务构建了自己的 ML 模型。接下来的步骤涉及部署它,以便它可以在生产中运行。
总而言之,微服务是一种架构和组织设计方法,用于安排松散耦合的服务。在 ML 应用程序中使用微服务方法的主要好处之一是独立于主要软件产品。拥有与主软件产品分离的功能服务( ML 应用程序)有两个关键好处:
- 它使跨职能团队能够参与分布式开发,从而加快部署速度。
- 软件的可扩展性得到了显著提高。
你觉得本教程有用吗?请在评论中留下您的反馈,或通过以下方式与我联系: 柯蒂斯皮克斯 (LinkedIn).




