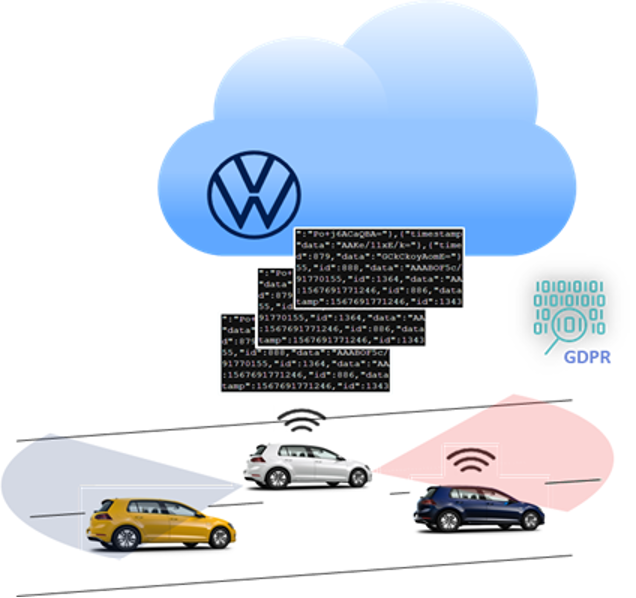
互联汽车是指使用后端系统与其他车辆进行通信的车辆,以增强可用性,实现便捷的服务,并保持分布式软件的维护和更新。
在大众汽车公司,我们正在使用 NVIDIA 开发互联汽车,以解决在原生 python 和 pandas 中实现时存在计算效率低下的问题,如地理空间索引和 K 近邻。
处理驾驶和传感器数据对于联网汽车了解其环境至关重要。它使连接的车辆能够执行诸如停车点检测、基于位置的服务、防盗、通过实时交通推荐路线、车队管理等任务。位置信息是大多数这些用例的关键,需要一个快速的处理管道来支持实时服务。
全球联网汽车的销量正在迅速增长,而这反过来又增加了可用的数据量。根据 Gartner ,平均连接车辆每年将产生 280 PB 的数据,其中至少一天会产生 4 TB 的数据。研究还指出,到 2025 年,将部署约 4 . 7 亿辆联网车辆。
这篇博文将集中讨论处理基于位置的地理空间信息和为联网汽车提供必要服务所需的数据管道。
互联汽车数据的挑战
使用互联汽车数据带来了技术和业务挑战:
需要快速处理大量的流数据,因为用户希望获得近乎实时的体验,以便及时做出决策。例如,如果一个用户请求一个停车位,而系统需要 5 分钟的响应时间,那么这个停车位很可能在回答时就已经被占用了。更快地处理和分析数据是克服这一挑战的关键因素。
还有数据隐私问题需要考虑。连接的车辆必须满足 通用数据保护条例( GDPR ) 。简而言之, GDPR 要求在数据分析之后,不应该有机会从分析的数据中识别单个用户。此外,禁止存储与个人用户有关的数据(除非用户书面同意)。匿名化可以通过屏蔽识别单个用户的数据或者通过分组和聚合数据来满足这些要求,这样就不可能跟踪用户。为此,我们需要确保处理联网车辆数据的软件符合 GDPR 关于数据匿名化的规定,这在数据处理过程中增加了额外的计算要求。

采用数据科学方法
RAPIDS 可以解决互联汽车的技术和业务难题。开放源码软件( OSS )库和 API 的 RAPIDS 套件使您能够完全在 GPU 上执行端到端的数据科学和分析管道。根据 Apache 2 . 0 , RAPIDS 由 NVIDIA 孵育 许可,并基于广泛的硬件和数据科学经验。 RAPIDS 利用 NVIDIA CUDA 开关 原语进行低级计算优化,并通过用户友好的 Python 接口公开 GPU 并行性和高带宽内存速度。
在下面的部分中,我们将讨论 RAPIDS (软件)和 NVIDIA GPU s (硬件)如何使用测试数据帮助解决原型应用程序的技术和业务挑战。将评估两种不同的方法:地理空间索引和 k- 近邻。
通过使用 RAPIDS ,我们可以将这个管道的速度提高 100 倍。
地理空间索引简介
地理空间索引是互联汽车领域许多算法的基础。它是将地球的各个区域划分成可识别的网格单元的过程。在查询互联汽车产生的海量数据时,对搜索空间进行修剪是一种有效的方法。
流行的方法包括 军用网格参考系统 ( MGRS )和 Uber 六边形层次空间索引 ( Uber H3 )。
在这个数据管道示例中,我们使用 Uber H3 在空间上将记录拆分为一组较小的子集。
以下是将记录拆分为子集后需要满足的条件 :
- 每个子集最多由 N 个记录组成。这个“ N ”是根据计算能力限制来选择的。对于这个实验,我们考虑“ n ”等于 2500 个记录。
- 子集由 subset _ id 表示,它是从 0 开始的自动递增数字。
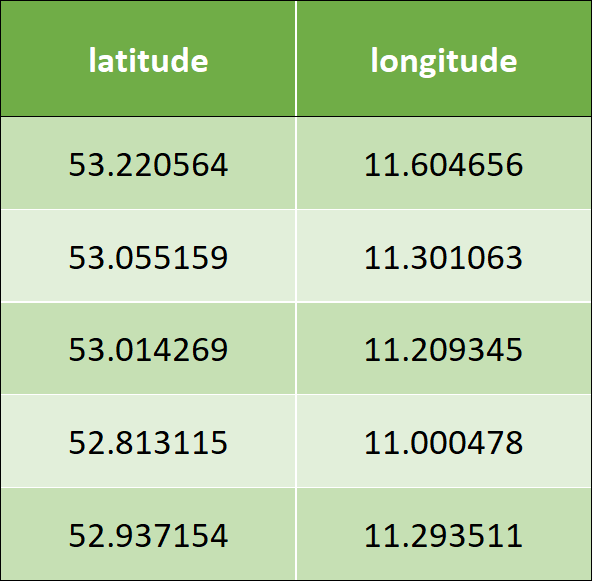
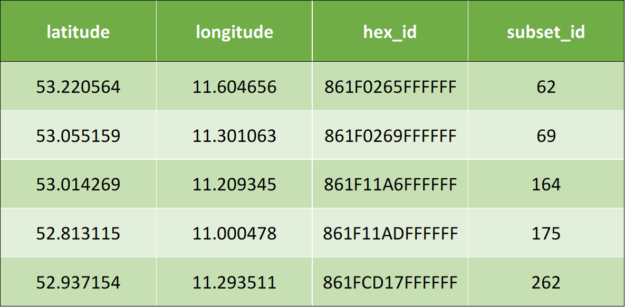
以下是示例输入数据,它有两列–纬度和经度:
下面是将 Uber H3 应用于用例需要实现的算法
- 迭代 latitude 和 longitude ,并从分辨率 0 分配 hex_id 。
- 如果发现任何包含少于 2500 条记录的 hex_id ,则从 0 开始递增地分配 subset_id 。
- 识别包含超过 2500 条记录的 hex \ u id 。
- 以增量分辨率拆分前面的记录,现在分辨率为 1 。
- 重复第 3 步和第 4 步,直到所有记录都分配给 subset \ u id 和 hex \ u id ,或者直到分辨率达到 15 。
应用上述算法后,将产生以下输出数据:
Uber H3 实现的代码片段
下面是使用 pandas 实现 Uber H3 的代码片段:
#while loop until all the records are assigned to subset_id
while resolution < 16 and df["subset_id"].isnull().any():
#assignment of hex_id
df['hex_id']= df.apply(lambda row: h3.geo_to_h3(row["latitude"],
row["longitude"], resolution), axis = 1)
df_aggreg = df.groupby(by = "hex_id").size().reset_index()
df_aggreg.columns = ["hex_id", "value"]
#filtering the records that are less than 2500 count
hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id']
#assignment of subset_id
for index, value in hex_id.items():
df.loc[df['hex_id'] == value, 'subset_id'] = subset_id
subset_id += 1
df_return = df_return.append(df[~df['subset_id'].isna()],
ignore_index=True)
df = df[df['subset_id'].isna()]
resolution += 1
下面是使用 PySpark 实现 Uber H3 的代码片段:
#while loop until all the records are assigned to subset_id
while resolution < 16 and (len(df.head(1)) != 0):
#assignment of hex_id
df = df.rdd.map(lambda x: (x["latitude"], x["longitude"],
x["subset_id"],h3.geo_to_h3(x["latitude"], x["longitude"],
resolution)))
df = sqlContext.createDataFrame(df, schema)
df_aggreg = df.groupby("hex_id").count()
df_aggreg = df_aggreg.withColumnRenamed("hex_id", "hex_id")
.withColumnRenamed("count", "value")
#filtering the records that are less than 2500 count
hex_id = df_aggreg.filter(df_aggreg.value < 2500)
var_hex_id = list(hex_id.select('hex_id').toPandas()['hex_id'])
for i in var_hex_id:
#assignment of subset_id
df = df.withColumn('subset_id',F.when(df.hex_id==i,subset_id)
.otherwise(df.subset_id)).select(df.latitude, df.longitude,
'subset_id', df.hex_id)
subset_id += 1
df_return = df_return.union(df.filter(df.subset_id != 0))
df = df.filter(df.subset_id == 0)
resolution += 1
通过对 Uber H3 模型的 pandas 实现,我们发现了一个非常缓慢的执行过程。代码的执行速度太慢导致生产力大大降低,因为只能做很少的实验。具体目标是将执行时间缩短 10 倍。
为了加快管道的速度,我们采取了如下一步一步的方法。
第一步:简单 CPU 并行版本
这个版本的思想是为 H3 库处理实现一个简单的基于多处理的内核。处理的第二部分,即根据数据分配子集,是 pandas 库函数,它不容易并行化。
#Function to assign hex_id
def minikernel(df, resolution):
df['hex_id'] = np.vectorize(lambda latitude, longitude:
h3.geo_to_h3(latitude, longitude, resolution))(
np.array(df['latitude']), np.array(df['longitude']))
return df
#while loop until all the records are assigned to subset_id
while resolution < 16 and df["subset_id"].isnull().any():
#CPU Parallelization
df_chunk = np.array_split(df, n_cores)
pool = Pool(n_cores)
#assigning hex_id by calling the function minikernel()
df_chunk_res=pool.map(partial(minikernel, resolution=resolution),
df_chunk)
df = pd.concat(df_chunk_res)
pool.close()
pool.join()
df_aggreg = df.groupby(by = "hex_id").size().reset_index()
df_aggreg.columns = ["hex_id", "value"]
#filtering the records that are less than 2500 count
hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id']
for index, value in hex_id.items():
#assignment of subset_id is pandas library function
#which cannot be parallelized
df.loc[df['hex_id'] == value, 'subset_id'] = subset_id
subset_id += 1
df_return = df_return.append(df[~df['subset_id'].isna()],
ignore_index=True)
df = df[df['subset_id'].isna()]
resolution += 1
通过对线程池应用简单的并行化,我们可以显著减少代码的第一部分( H3 库),但第二部分( pandas 库)是完全单线程的,速度非常慢。
第二步:应用 RAPIDS [ZBK9
这里的想法是尽可能多地使用 cuDF 中的标准特性(因此,最轻微的代码更改)来实现最佳性能。由于 cuDF 现在在 CUDA 统一内存上运行,因此不可能简单地并行化第一部分( H3 库),因为 cuDF 不处理 CPU 分区。代码如下所示。注意,以下代码在 cuDF 数据帧上运行。
#while loop until all the records are assigned to subset_id
while resolution < 16 and df["subset_id"].isnull().any():
#assignment of hex_id
#df is a cuDF
df['hex_id'] = np.vectorize(lambda latitude, longitude:
h3.geo_to_h3(latitude, longitude, resolution))
(df['latitude'].to_array(), df['longitude']
.to_array())
df_aggreg = df.groupby('hex_id').size().reset_index()
df_aggreg.columns = ["hex_id", "value"]
#filtering the records that are less than 2500 count
hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id']
for index, value in hex_id.to_pandas().items():
#assignment of subset_id
df.loc[df['hex_id'] == value, 'subset_id'] = subset_id
subset_id += 1
df_return = df_return.append(df[~df['subset_id'].isna()],
ignore_index=True)
df = df[df['subset_id'].isna()]
resolution += 1
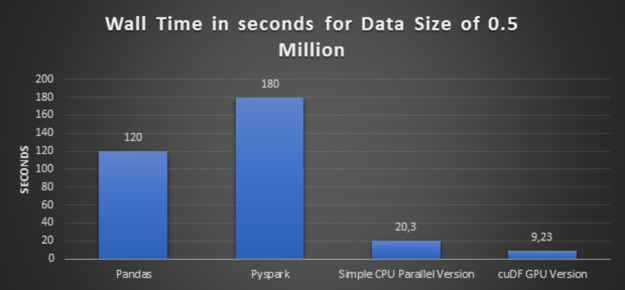
步骤 3 :使用较大的数据执行简单的 CPU 并行版本和 cuDF GPU 版本
在这一步中,我们将数据量增加了三倍,从 50 万条记录增加到 150 万条记录,并执行一个简单的 CPU 并行版本及其等价的 cuDF GPU 版本。
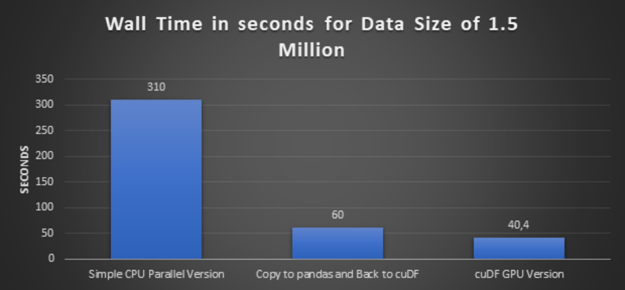
第四步:再做一次实验,复制到 pandas 和 cuDF
如步骤 2 所述, cuDF 在 CUDA 统一内存上运行,由于 cuDF 缺少 CPU 分区,因此无法并行化第一部分( H3 库)。因此,我们没有使用函数数组\ u split 。为了克服这个挑战,我们首先将 cuDF 转换为 pandas 数据帧,然后应用函数数组\ u split ,然后将分割的块转换回 cuDF ,并进一步进行 H3 库处理。
#while loop until all the records are assigned to subset_id
while resolution < 16 and df["subset_id"].isnull().any():
#copy to pandas
df_temp = df.to_pandas()
#CPU Parallelization
df_chunk = np.array_split(df_temp, n_cores)
pool = Pool(n_cores)
df_chunk_res=pool.map(partial(minikernel, resolution=resolution),
df_chunk)
pool.close()
pool.join()
df_temp = pd.concat(df_chunk_res)
#Back to cuDF
df = cudf.DataFrame(df_temp)
#assignment of hex_id
df['hex_id'] = np.vectorize(lambda latitude, longitude:
h3.geo_to_h3(latitude, longitude, resolution))
(df['latitude'].to_array(), df['longitude']
.to_array())
df_aggreg = df.groupby('hex_id').size().reset_index()
df_aggreg.columns = ["hex_id", "value"]
#filtering the records that are less than 2500 count
hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id']
for index, value in hex_id.to_pandas().items():
#assignment of subset_id
df.loc[df['hex_id'] == value, 'subset_id'] = subset_id
subset_id += 1
df_return = df_return.append(df[~df['subset_id'].isna()],
ignore_index=True)
df = df[df['subset_id'].isna()]
resolution += 1
浏览所有上述方法的执行时间图:
加快地理空间指数计算的经验教训
- 高性能: 前面的略图得出的结论很清楚, cuDF GPU 版本提供了最佳性能。而且数据集越大,速度就越快。
- 代码适应性和易转换性: 请注意,所移植的代码并不是 GPU 加速的最佳方案。我们正在 CPU 上运行的第三方库( Uber H3 )上运行比较。为了利用这个库,我们需要在每个循环上将数据从 GPU 内存复制到 CPU 内存,这不是最佳方法。
除此之外,还有一个子集合 id 计算,它也是以行方式进行的,通过更改原始代码可能会加快计算速度。但代码仍然没有改变,因为我们的主要目标之一是检查代码的适应性以及库 pandas 和 cuDF 之间的轻松转换。 - 可重用代码: 正如您在前面已经观察到的,管道是一组标准化的函数,也可以用作解决其他用例的函数。
一种 CUDA 加速 K 近邻分类方法的研究
使用上述方案,而不是通过索引和分组的方式来测量相连车辆的密度——另一种方法是根据两个地点之间的地球距离进行地理分类。
我们选择的分类算法是 K- 近邻 。最近邻方法的原理是找到距离数据点最近的预定义数量的数据点( K )。我们将比较基于 CPU 的 KNN 实现与相同算法的 RAPIDS GPU 加速版本。
在我们当前的用例中,我们使用匿名流式连接的汽车数据(如前面的业务挑战中所述)。在这里,使用 KNN 对数据进行分组和聚合是匿名化的一部分。
然而,对于我们的用例,当我们在地理坐标上分组和聚合时,我们将使用 Haversine 度量,它是唯一可以对地理坐标进行聚类的度量。
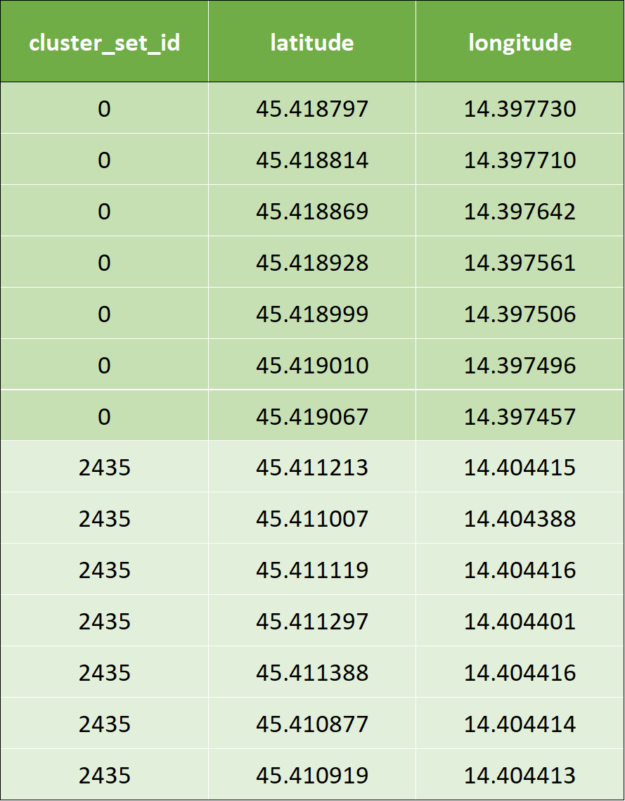
在我们的管道中,使用 haversine 作为距离度量的 KNN 的输入将是地理坐标(纬度、经度)和所需的最近数据点的数量。在下面的示例中,将创建 K = 7 。
在下面的例子中,我们展示了以元组(经度和纬度)表示的相同数据。
- 输入数据与上一个示例中显示的元组(经度和纬度)相同。
- 应用 KNN 后,通过 KNN 算法计算群集 id : 对于前两行输入数据,集群输出数据如下所示。为了避免混淆,我们用相应的颜色标记集群 id 。
以下是使用 pandas 实现 KNN 的代码片段:
nbrs = NearestNeighbors(n_neighbors=7, algorithm='ball_tree',
metric = "haversine").fit(coord_array_rad)
distances, indices = nbrs.kneighbors(coord_array_rad)
# Distance is computed in radians from haversine
distances_m = earth_radius * distances
# Drop KNN, which are not compliant with minimum distance
compliant_distances_mask = (distances_m<KNN_MAX_DISTANCE)
.all(axis = 1)
compliant_indices = indices[compliant_distances_mask]
采用 KNN 作为分类算法。 KNN 的缺点是它的计算性能,特别是当数据量较大时。我们的目的是最终利用 cuML 的 KNN 实现。
之前的实现在相当小的数据集中工作,但没有在 1 . 5 天内完成 300 万条记录的处理。所以我们阻止了它。
为了转向 CUDA 加速的 KNN 实现,我们必须用如下所示的等效度量来模拟 haversine 距离。
第 1 步:围绕哈弗斯线进行坐标变换
在运行此练习时,在 cuML 的 KNN 实现中, haversine 距离度量本机不可用。因此,使用欧几里德距离代替。尽管如此,公平地说,当前版本的 RAPIDS KNN 已经支持 haversine 度量。
首先,我们将坐标转换为以米为单位的距离,以便执行距离度量计算。[10]这是通过名为 df _ geo ()的函数实现的,该函数将在下一步中使用。
欧几里德距离的一个警告是,它不适用于地球上距离更远的坐标。相反,它基本上会在地球表面“挖洞”,而不是在地球表面。但是,对于小于等于 100 公里的较小距离,哈弗斯距离和欧几里德距离之间的差异最小。
步骤 2 :执行 KNN 算法
到目前为止,我们已经将所有坐标转换为东北坐标格式,在这一步中,可以应用实际的 KNN 算法。
我们在下面的设置中使用了 CUDA 加速 KNN 。我们注意到这个实现执行得非常快,绝对值得实现。
#defining the hyperparameters
n_neighbors = 7
algorithm = "brute"
metric = "euclidean"
#Implementation of kNN by calling df_geo() which converts the coordinates #into Northing and Easting coordinate format
nbrs = NearestNeighbors(n_neighbors=n_neighbors, algorithm=algorithm,
metric=metric).fit(df_geo[['northing', 'easting']])
distances, indices = nbrs.kneighbors(df_geo[['northing', 'easting']])
步骤 3 :执行距离掩蔽和过滤
这一部分是在 CPU 上完成的,因为在 GPU 上没有明显的加速。
distances = cp.asnumpy(distances.values) indices = cp.asnumpy(indices.values)
#running on CPU KNN_MAX_DISTANCE = 10000 # meters # Drop KNN, which are not compliant with minimum distance compliant_distances_mask = (distances < KNN_MAX_DISTANCE).all(axis = 1) compliant_indices = indices[compliant_distances_mask]
我们的结果是在 naive pandas 实现的基础上应用到一个有 300 万个样本的数据集时,加速了 800 倍。
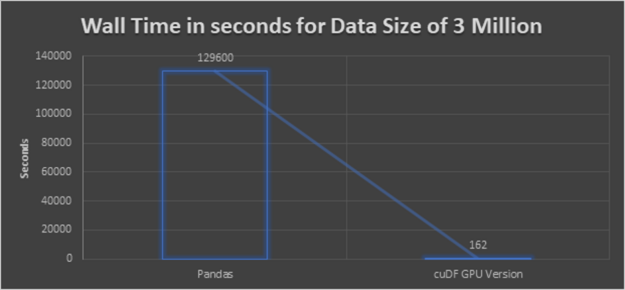
K 近邻聚类的经验教训
- 高性能: 前面的略图得出的结论很清楚, cuDF GPU 版本提供了最佳性能。即使数据集更大,执行也不会像 CPU 执行那样花费很长时间。
- 比较 cuML 和 scikit 的 KNN : 基于 cuML 的实现速度极快。但是我们不得不多走一英里来模拟缺失的距离指标。考虑到所取得的性能提升,做比要求更多的事情绝对值得。同时, haversine 距离在 RAPIDS AI 中受支持,并且与 scikit 实现一样方便。
我们利用欧几里德距离和北向东距的方法来克服缺失的哈弗斯距离。根据我们代码中的研究“ 在相当长的距离上——可能长达几千公里或更多,欧几里德开始错误的计算 ”,我们将距离限制为 10 公里。通过使用北距 – 东距,我们首先需要转换坐标。由于整体性能更好,我们可以接受转换坐标所需的时间。 - 代码适应性和易转换性: 除北距 – 东距功能外。
- 剩下的代码类似于 CPU 代码,仍然获得了更好的性能。我们没有更改代码,因为我们的主要目标之一也是检查代码的适应性以及库 pandas 和 cuDF 之间的轻松转换。
- 可重用代码: 正如您在前面已经观察到的, pipeline 是一组标准化的函数,也可以用作解决其他用例的函数。
概括
本文总结了 RAPIDS 如何通过在两个模型(即地理空间索引( Uber H3 )和 K 近邻分类( KNN ))上对数据管道进行评估,从而将数据管道的速度提高 100 倍。此外,我们分析了 NVIDIA RAPIDS AI 相对于前两种模型在性能、代码适应性和可重用性等方面的优缺点。我们的结论是 RAPIDS 肯定是一种流数据处理技术(连接的汽车数据)。它提供了更快的数据处理的好处,这是流数据分析的关键因素。而且, RAPIDS 支持大量的机器学习算法。加速的 RAPIDS cuDF 和 cuML 库的 API 与 pandas 保持相似,以实现简单的转换。改造现有的 ML 管道并使其受益于 cuDF 和 cuML 非常容易。
何时选择 RAPIDS 而不是标准 Python 和 pandas :
- 当应用程序需要更快的数据处理时。
- 如果您确信该代码在 GPU 中运行比在 CPU 中运行有好处。
- 如果推荐的算法作为 cuML 的一部分可用。
本文针对汽车工程师、数据工程师、大数据架构师、项目经理和行业顾问,他们对探索或处理数据科学的可能性以及使用 Python 分析数据感兴趣。
- 听 GTC 会话: 使用 RAPIDS [E31421]将大众连接的汽车数据管道加速 100 倍