压缩可以在各种用例中提高性能,例如 DL 工作负载、数据库和通用 HPC 。在 GPU 上,压缩可以加速协作工作流的 GPU 间通信。它可以通过在数据存储到全局内存之前压缩数据来增加单个 GPU 可以处理的数据集的大小。它还可以加速 CPU 和 GPU 之间的数据链路。
为了让这些工作流中的任何一个都变得有用,压缩和解压缩必须快速,并且在给定数据集上以足够高的压缩比运行,才能发挥作用。然而,不同算法的压缩比和吞吐量因数据集而异。如果没有大量关于算法和数据统计的专业知识,可能很难选择最佳算法。
NVIDIA NVCOMP 库使您可以在应用程序中结合高性能 GPU 压缩和解压缩。该库提供了一组统一的 API ,允许您快速交换压缩格式,以在数据集上实现最佳性能,而对代码的更改最少。
使用 nvCOMP ,您可以快速、轻松地使用不同的算法进行实验,以找到最适合您的用例的算法。在最近的版本中,我们更新了 nvCOMP 以进一步改进和统一接口。在新发布的 2.2 版本中,我们提供了一个易于使用的、高级的 C ++ API 和一个通用的低级别批量 C API 。在本文中,我们将详细介绍这两个接口。你还可以学习如何有效地使用它们,以及何时应该选择其中一个。
高级 API
高级 API 更易于使用,并抽象了向 GPU 公开并行性的工作。当您必须将连续缓冲区压缩为连续的压缩缓冲区时,它最有用。例如,在通过网络发送缓冲区或将其保存到磁盘之前压缩缓冲区时,这种方法效果很好。
以下示例使用高通量GDeflate压缩格式。GDeflate类似于 deflate ,可以有效地映射到数据并行架构,如 GPU 。如果您对使用的压缩格式没有限制,那么这是一个很好的起点。
高级接口是基于nvcompManagerBase类层次结构的C++ API。每个派生的Manager类都在nvcomp/include中与其关联的头中声明。例如,本文中使用的GDeflateManager在nvcomp/include/gdeflate.hpp中声明。
首先,构建所需的Manager类。每个Manager构造函数都有一组唯一的参数;然而,有一些观点通常是一致的。所有子类都允许使用指定的流 ID 构造用于所有内核和内存传输。您还可以指定要使用的设备 ID 。如果不为这两个参数指定值,则使用默认的流和设备。
另一个常见的输入是未压缩的块大小。这在压缩过程中用于将缓冲区拆分为独立的块进行处理。较大的块大小通常会导致更高的压缩比,但代价是暴露在 GPU 中的并行性会降低。一个好的起始数据块大小是 64KB ,但是可以自由地使用这些值来探索数据集的相关权衡。
Manager类也使用特定于格式的参数构造。您可以查看nvcomp/include中的相关标题,了解Manager类构造函数参数的描述,并了解如何为所选格式构造Manager对象。
const size_t uncomp_chunk_size = 64 * 1024; cudaStream_t stream;
cudaStreamCreate(&stream));
const int gdeflate_algorithm = 0; // Use standard GDeflate
const int device_id = 0; // Use the default device GdeflateManager gdeflate_manager{chunk_size, gdeflate_algorithm, stream, device_id};
nvcompManager需要一个临时的 scratch 工作区来进行压缩和解压缩。根据特定的压缩格式参数以及压缩和解压缩内核的最大占用率,所需的暂存空间大小是固定的。如果对您的用例有意义,您可以在构造后使用set_scratch_buffer为nvcompManager对象提供一个临时缓冲区。
size_t scratch_buffer_size = gdeflate_manager.get_required_scratch_buffer_size(); uint8_t* scratch_buffer; cudaMalloc(&scratch_buffer, scratch_buffer_size); gdeflate_manager.set_scratch_buffer(scratch_buffer);
手动设置暂存缓冲区可能有助于控制用于此分配的内存分配方案。如果您同意默认设置,我们建议跳过此步骤并启用nvcompManager对象来处理分配。
此缓冲区可用于nvcompManager执行的所有压缩和解压缩操作。如果nvcompManager对象分配了暂存缓冲区,则在销毁该对象时会释放该缓冲区。
压缩
现在可以压缩缓冲区了。首先,使用configure_compression API 配置压缩。此异步操作返回CompressionConfig对象。
配置步骤只需要input-uncompressed缓冲区的大小。您必须分配一个 GPU 可访问的内存缓冲区,其大小至少为该大小,以用作压缩例程的结果缓冲区。有了这些信息,可以执行压缩,如下面的代码示例所示:
CompressionConfig comp_config = gdeflate_manager.configure_compression(input_buffer_len); uint8_t* comp_buffer; cudaMallocAsync(&comp_buffer, comp_config.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer, comp_buffer, comp_config);
您还可以在 GPU 上排队进行其他压缩。
uint8_t* comp_buffer1, comp_buffer2; CompressionConfig comp_config1 = gdeflate_manager.configure_compression(input_buffer_len1); cudaMallocAsync(&comp_buffer1, comp_config1.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer1, comp_buffer1, comp_config1); CompressionConfig comp_config2 = gdeflate_manager.configure_compression(input_buffer_len2); cudaMallocAsync(&comp_buffer2, comp_config2.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer2, comp_buffer2, comp_config2); cudaStreamSynchronize(stream);
减压
高级接口压缩产生的缓冲区在压缩数据之前包含一个头(图 1 )。此标题包含有关缓冲区如何压缩的信息,因此您可以从压缩的缓冲区构造nvcompManager对象,而不知道它是如何压缩的。这使您可以在不知道缓冲区是如何压缩的情况下对其进行解压缩。

为此,请使用nvcompManagerFactory.hpp中声明的create_manager API 。这个同步 API 将压缩的缓冲区以及可选的流和设备 ID 作为输入。
auto decomp_nvcomp_manager = create_manager(comp_buffer, stream);
如果您已经掌握了有关缓冲区压缩方式的信息,那么可以使用前面描述的配置构造一个新的管理器。您还可以重用用于压缩的同一nvcompManager对象来执行解压缩。这些方法的优点是不需要同步流。
给定一个nvcompManager对象和一个压缩的缓冲区,解压的执行与压缩类似,但有几个细微的区别。首先,有两种可能的方式来进行解压缩配置。如果压缩使用CompressionConfig对象,则可以完全异步配置解压缩。
DecompressionConfig decomp_config = gdeflate_manager->configure_decompression(comp_config);
该 API 的一个示例用例是大型神经网络的训练。可以使用的神经网络或训练集的大小取决于 GPU 的内存容量。使用压缩,您可以有效地增加此容量,而无需将数据卸载到 CPU 或使用多个 GPU 。
具体来说,基于反向传播的训练包括在向前传球时计算激活图,然后在向后传球的计算中重用它们。这些激活映射比较大且相对稀疏,因此非常适合压缩。使用gdeflate_manager压缩地图,并在内存中保存网络各层的压缩缓冲区和CompressionConfig对象。这可以实现完全异步的反向传播,包括解压缩。
如果没有使用的CompressionConfig对象,也可以使用压缩缓冲区配置解压缩。这是一个同步操作,必须从设备执行cudaMemcpyAsync操作。所有同步都在nvcompManager构造函数中指定的流上,并且不是设备范围的。
DecompressionConfig decomp_config = gdeflate_manager->configure_decompression(comp_buffer);
与压缩一样,在同步流之前,您可以一次将多个解压缩项目排队。
uint8_t* res_decomp_buffer1, res_decomp_buffer2; DecompressionConfig decomp_config1 = gdeflate_manager->configure_decompression(comp_config1); DecompressionConfig decomp_config2 = gdeflate_manager->configure_decompression(comp_config2); cudaMallocAsync(&res_decomp_buffer1, decomp_config1.decomp_data_size, stream); cudaMallocAsync(&res_decomp_buffer2, decomp_config2.decomp_data_size, stream); gdeflate_manager->decompress(res_decomp_buffer1, comp_buffer1, decomp_config1); gdeflate_manager->decompress(res_decomp_buffer2, comp_buffer2, decomp_config2); cudaStreamSynchronize(stream));
最后,在高级 API 中有两种类型的错误检查:std::runtime_error异常和检查nvcompStatus_t值。
如果任何 CUDA API 失败,就会引发std::runtime_error异常。您可以在应用程序中捕获这些错误,也可以不处理它们,在这种情况下,您的应用程序会失败,并显示一条描述错误的消息。例如,如果您提供的输出缓冲区大小不足或无法在 GPU 上访问,就会发生这种情况。
错误检查的第二种形式是检查CompressionConfig或DecompressionConfig对象中的nvcompStatus_t值。此状态在相关的内核调用期间设置。损坏的输入缓冲区和其他错误会触发它。
低级 API
低级 API 为更高级的工作流提供了 C API 。低级 API 同时压缩和解压缩您提供的一批独立块。这取决于您对数据进行分块,并提供足够数量的分块来利用 GPU 的并行处理能力。
如果有许多独立的、不连续的缓冲区,这是处理数据最有效的方法。低级 API 避免了将生成的压缩块打包到单个连续的压缩缓冲区的工作量。它还避免了与在高级 API 中保存有关缓冲区如何压缩的信息相关的压缩比开销。
该工作流非常适合数据库应用程序,例如,在这些应用程序中,往往需要压缩或解压缩许多独立的列。这个 API 用于 RAPIDS 和 NVIDIA Spark 实现。
压缩
对于低级 API 中的压缩,必须分配一个临时暂存缓冲区。临时缓冲区与高级 API 中描述的类似。然而,缓冲区大小取决于输入缓冲区的大小,因此必须重新定义它,并可能与每一组新的用户输入一起重新分配。
size_t temp_bytes; nvcompBatchedGdeflateCompressGetTempSize(batch_size, chunk_size, nvcompBatchedGdeflateDefaultOpts, &temp_bytes); void* device_temp_ptr; cudaMalloc(&device_temp_ptr, temp_bytes);
接下来,应该计算批处理中压缩块的最大大小。这允许您分配一组结果缓冲区。在下面的示例中,batch_size是要处理的块数。结果指针的设备数组在复制到设备之前在固定的主机内存中构造。
size_t max_out_bytes;
nvcompBatchedGdeflateCompressGetMaxOutputChunkSize(chunk_size, nvcompBatchedGdeflateDefaultOpts, &max_out_bytes); // Allocate output space on the device
void ** host_compressed_ptrs;
cudaMallocHost((void**)&host_compressed_ptrs, sizeof(size_t) * batch_size);
for(size_t ix_chunk = 0; ix_chunk < batch_size; ++ix_chunk) { cudaMalloc(&host_compressed_ptrs[ix_chunk], max_out_bytes);
} void** device_compressed_ptrs;
cudaMalloc(&device_compressed_ptrs, sizeof(size_t) * batch_size);
cudaMemcpy( device_compressed_ptrs, host_compressed_ptrs, sizeof(size_t) * batch_size,cudaMemcpyHostToDevice);
通过计算所有这些输入,您现在可以异步进行压缩,如图所示。
nvcompStatus_t comp_res = nvcompBatchedGdeflateCompressAsync( device_uncompressed_ptrs, device_uncompressed_bytes, chunk_size, batch_size, device_temp_ptr, temp_bytes, device_compressed_ptrs, device_compressed_bytes, nvcompBatchedGdeflateDefaultOpts,
减压
要开始解压,请根据压缩的缓冲区预计算解压的大小。如果您已经有此信息,请跳过此步骤。
nvcompBatchedGdeflateGetDecompressSizeAsync( device_compressed_ptrs, device_compressed_bytes, device_uncompressed_bytes, batch_size, stream);
与压缩类似,您还必须计算所需的临时大小,并分配临时暂存缓冲区。
size_t decomp_temp_bytes; nvcompBatchedGdeflateDecompressGetTempSize(batch_size, chunk_size, &decomp_temp_bytes); void * device_decomp_temp; cudaMalloc(&device_decomp_temp, decomp_temp_bytes);
最后,可以进行异步解压缩。
nvcompStatus_t decomp_res = nvcompBatchedGdeflateDecompressAsync( device_compressed_ptrs, device_compressed_bytes, device_uncompressed_bytes, device_actual_uncompressed_bytes, batch_size, device_decomp_temp, decomp_temp_bytes, device_uncompressed_ptrs, device_statuses, stream);
标杆管理
nvCOMP 为低级和高级格式的每种格式提供了一组基准。图 2 比较了在几个不同的数据集上使用大型连续缓冲区时高级和低级的性能。使用 A100 GPU 收集结果。
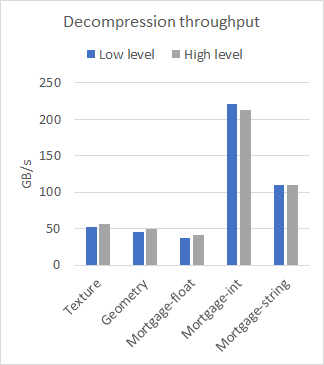
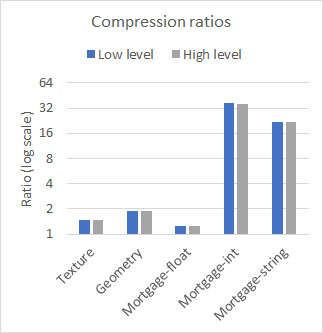
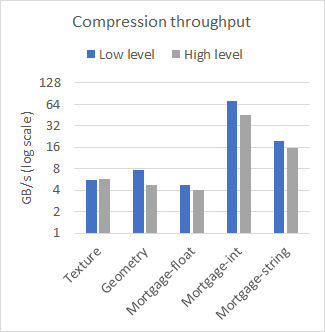
从结果中可以看出,在使用大型连续缓冲区时,低级和高级 API 之间的性能差异可以忽略不计。使用哪一个取决于您的用例。如果有许多小缓冲区,请使用低级 API ,或者避免与高级 API 相关的内存占用。
图 3 显示了日志规模下不同缓冲区大小的性能。为了产生这些结果,图 2 中显示的 mortgage int 数据集被分成许多批batchSize,如图所示。该文件超过 314 MB 。对于 1 MB 的批量大小,执行 315 次压缩和解压缩操作。批量大小为 400 MB 时,执行单个压缩和解压缩操作。
以这种方式批处理数据不会影响低级批处理 API 。
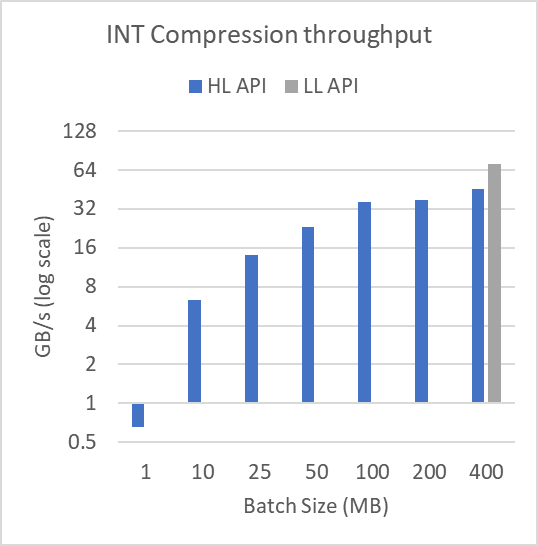
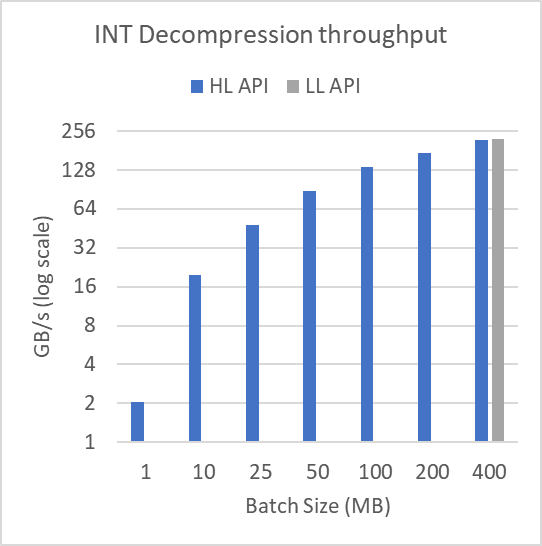
正如所证明的,对于小批量,高级接口的性能会严重下降。这显示了在压缩或解压缩许多较小的缓冲区时使用低级批处理 API 的实用性。低级批处理 API 可以使用更少、占用率更高的内核来完成操作,而高级 API 需要许多具有相关尾部效应和占用率问题的小型内核启动。
我们在库中加入了基准测试应用程序,以便您可以尝试不同的压缩格式,并查看哪种格式对您的数据最有效。提供的基准是benchmark_hlif和benchmark_<format>_chunked。有关更多信息,请参阅 nvCOMP README 。
总结
现在,您已经了解了如何使用高级 nvCOMP API 来轻松压缩和解压缩。您已经了解了何时使用低级 API 更好,以及如何使用它。
有关更多信息,请参阅 NVIDIA/nvcomp GitHub 回购协议的最新版本。有关可以适应您的用例的完整工作、可编译的示例,请参阅 lowlevel_c_quickstart.md 和 highlevel_cpp_quickstart.md 演练以及相关的示例文件。
如果您有任何问题,请在下面评论。你也可以在 联系专家: nvCOMP:GPU 压缩/解压缩 GTC 会议将于 3 月 21 日星期一上午 10 点举行。




