
随着 AI 、 ML 和 HPC 应用程序的计算从 CPU 转移到更快的 GPU ,输入输出 GPU 的 IO 可能成为整体应用程序性能的主要瓶颈。
NVIDIA 创建了 Magnum IO GPU 直接存储( GDS ),以简化存储和 GPU 内存之间的数据移动,并消除平台中的性能瓶颈,例如被迫通过 CPU 内存中的缓冲区存储和转发数据。
GDS 通过在本地 NVMe 存储或 NIC 后面的远程存储和 GPU 内存之间启用直接内存访问( DMA ),提高了带宽,减少了延迟,减轻了 CPU 利用率的负担。从 DGX 平台上的 GDS 本身的深度学习推理、数据分析可视化和视频分析中分别观察到 2 . 5x 、 8x 和 9x 的性能优势。

要在部署的平台范围内加速各种各样的客户应用程序和框架,需要一系列合作关系。我们的目标是实现整个丰富的数据存储生态系统,该生态系统由近 180 家软件和硬件供应商以及 2500 多个贡献者组成。有关更多信息,请参阅SNIA网站。
本文概述了 GDS 合作生态系统,并分享了我们合作伙伴的最新成果。
GDS 生态系统
NVIDIA 寻求一个开放的生态系统,与供应商、框架开发人员和最终客户建立越来越多的合作伙伴关系。自 GPU Direct Storage 的 1 . 0 产品发布以来,合作伙伴供应商的生态系统已经发展,如表 1 所示。
每个类别中的项目按时间顺序排列。尚未发布的项目和正在开发的项目均为斜体。以黄色突出显示的项目具有自本系列最后一篇 GDS 文章发布以来的新数据。
| Vendor partners | Frameworks and applications | Systems software |
| File systems – DDN EXAScaler – Weka FS – VAST NFSoRDMA – EXT4 via NVMe or NVMoF drivers from MLNX_OFED – IBM Spectrum Scale (GPFS) – DELL Technologies PowerScale – NetApp/SFW/BeeGFS – NetApp/NFS – HPE Cray ClusterStor Lustre Block systems – Excelero – ScaleFlux smart storage |
Storage -HDF5 – ADIOS – OMPIO Deep learning – PyTorch – MXNet Data analytics – cuDF – DALI – Spark – cuSIM/Clara – NVTabular Databases – HeteroDB for PostgreSQL acceleration Visualization – IndeX |
– Ubuntu 18.04 – Ubuntu 20.04 – RHEL 8.3 – RHEL 8.4 – DGX BaseOS Compatibility mode only: – Debian 10 – RHEL7.9 – CentOS 7.9 – Ubuntu 18.04 (desktop) – Ubuntu 20.04 (desktop) – SLES 15.2 – OpenSUSE 15.2 |
| Contributions to a repo | Systems vendors | Media vendors |
| Readers – Serial HDF5 – IOR Containers – PyTorch/DALI Samples – Transparent threading – Buffer agnostic |
– Dell – Hitachi – HPE – IBM – Liqid – Pavilion |
– Kioxia – Micron – Samsung – Western Digital |
供应商合作伙伴
我们有几种不同类型的供应商合作伙伴,他们的产品具有不同的成熟度。供应商合作伙伴分为两类:直接参与 GDS 软件支持的合作伙伴和提供系统和组件解决方案的合作伙伴。
GDS 支持合作伙伴全面提供
本节涵盖了那些积极地使英伟达 GPU 直接存储到他们拥有的软件栈中的合作伙伴,满足 NVIDIA 基本功能和性能标准,并将其集成到一般可用性的生产解决方案中。

- DDN 将 GDS 集成到基于 Lustre 的 EXAScaler 并行文件系统中。他们正在与社区合作,将 GDS 支持上游到开源发行版。
- Dell Power Scale 是 NFS 的优化实现。
- IBM Spectrum Scale ,以前称为 GPFS ,是 HPC 、数据和 AI 中广泛使用的分布式并行文件系统。
- 庞大的并行分布式文件系统开创了通过 RDMA ( NFSoRDMA )提供多路径 NFS 的先河。 VAST 还使 nconnect 中 NFSoRDMA 中的 GDS 在将来的上游版本中可用。
- Weka 将 GDS 集成到自己的 Weka FS 并行分布式文件系统中。
解决方案和组件提供商全面提供
一些供应商对 GDS 的支持处于通用可用性级别。一些供应商提供软件解决方案,对代码进行更改以启用 GDS ,而其他供应商则是已经或将要使用 GDS 的组件或系统供应商。
提供硬件或 GDS 特性数据的供应商
NVIDIA 与我们的 NPN 和 GPU 直接存储合作伙伴密切合作,以鉴定 GDS 的全部功能。他们还使用硬件和软件解决方案,结合 NVIDIA 带来的最佳 GPU 加速技术,量化测量的性能增益。这些措施包括:。
使用其他支持 GDS 的解决方案(如 MLNX _ OFED 中提供的解决方案)提供完整端到端解决方案的系统供应商合作伙伴包括:

- 数字数据网
- 戴尔科技
- 惠普企业
- 国际商用机器公司
- 亭阁
- 巨大的
与我们合作最密切的组件供应商包括:

- 基奥西亚
- 微米
- 桑孙
- 标度通量
表达兴趣的供应商
对 GDS 表示强烈兴趣的其他供应商包括:
- 日立
- 轻盈
- 西部数字
开发中的 GDS 支持合作伙伴
有些合作伙伴的产品可供您评估,但尚未达到全面可用的成熟期:

- BeeGFS 并行分布式文件系统是 HPC 中常用的文件系统。 System Fabric Works 一直在与 NetApp 合作为 BeeGFS 启用 GDS 。
- Excelero NVMesh 将任何网络上的 NVMe 驱动器转换为支持任何本地或分布式文件系统的企业级受保护共享存储。
- HPE 促成了 Cray ClusterStor E1000 Storage System中使用的支持 GDS 的 Lustre 并行分布式文件系统代码的升级。
- NetApp 目前正在致力于启用服务器端 NFSoRDMA ,因此他们可以利用其他人在客户端启用 NFS 的 GDS 。
具有 GDS 的供应商证明点
自 NVIDIA 发布last GDS post以来,已有几项新数据的开发。我们在这篇文章中分享了其中的一个示例,作为证明 GPU 直接存储的好处和通用性的证据。
配置
GDS 可以通过跳过各种平台上的 CPU 跳出缓冲区来增加价值,无论是 NVIDIA 的 DGX 系统还是第三方 OEM 平台。如前一篇文章Accelerating IO in the Modern Data Center: Magnum IO Storage所述,当 NIC PCIe 交换机 – GPU 数据路径不经过 CPU 就可用时, GDS 可用的理论峰值带宽有 2 倍的差异,尽管实际增益可能要大得多。
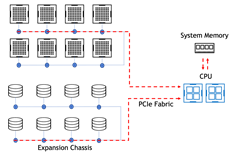
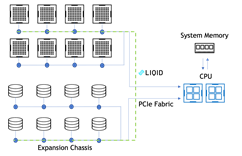
在 DGX 中,某些 NIC 插槽的数据路径必须经过 CPU ,而对于其他插槽,直接 NIC PCIe 交换机 GPU 路径可绕过 CPU 。图 2 显示了 DGX A100 背面的标记图片。
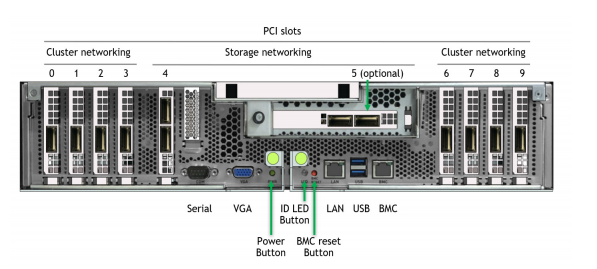
有两种配置可以在 DGX A100 上评估存储性能。经批准的标准配置在插槽 4 和 5 中专用于连接到用户管理平面和外部存储平面的两个“南北”(朝向数据中心边缘) NIC ,以及在插槽 0-3 和 6-9 中专用于连接到节点间计算平面的八个“东西”(集群内) NIC 。
我们正朝着使用八个东西方 NIC 访问高带宽存储的方向发展,从而在完成 QoS 评估之前创建一个聚合计算存储平面。现在,我们称之为实验的配置
以前提供的合作伙伴数据
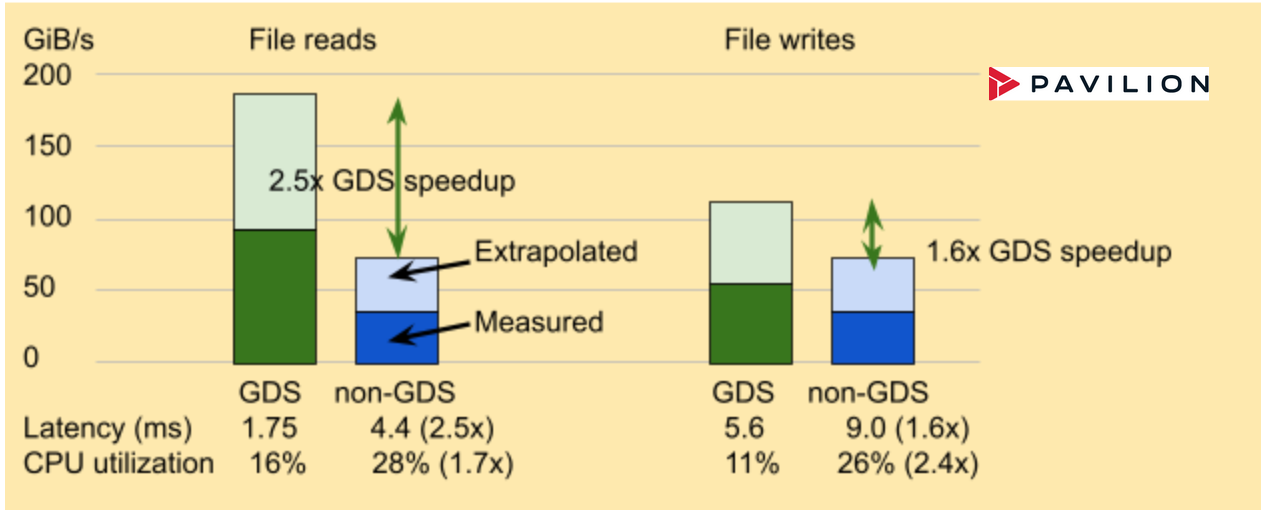
自从第一次发布 GDS 后, NVIDIA 已经公开了其他供应商的数据。其中包括来自 DDN EXAScaler 、 Pavilion NFSoRDMA 、 VAST NFSoRDMA 和 Weka FS 的数字。使用 DGX A100 上的实验性 8-NIC 配置,我们已经看到供应商提供的带宽范围为 152 到 178 GiB ( 186 GB / s )的 GDS 。如果没有 GDS ,他们报告的带宽范围为 40-103 GiB / s 。
今后, NVIDIA 要求任何合作伙伴的 DGX 系统性能报告(包括 8-NIC 数据)也应包括两个南北 NIC 的特性描述。这些数据还没有全部出来,所以这里没有介绍。我们的政策是不在供应商合作伙伴之间进行直接性能比较。
以太网上的海量数据
以前在 InfiniBand 上报告了海量数据通用存储。他们提供了一个单一(插槽 4 ) NIC 和 DGX A100 中的 1 GPU 的新结果,该 DGX A100 具有庞大的入门级 1 × 1 配置,使用以太网而不是 InfiniBand 。以太网显示了完整的功能和相当的性能。从单个链路实现超过 22 GiB / s 的速度接近最高性能。这表明,除了 InfiniBand 之外, GDS 同样适用于以太网。
IBM 频谱规模
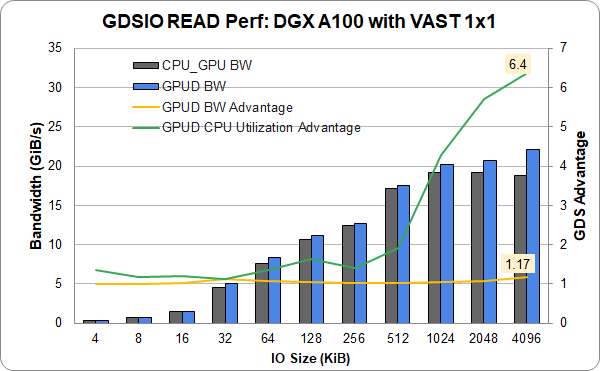
IBM Spectrum Scale (前身为 GPFS )的 GA 产品最近有了一个条目。在他们的配置中,一个运行 IBM Spectrum Scale 5 . 1 . 1 的 ESS 3200 存储文件服务器提供了 71 GiB / s ( 77 GB / s )。它通过 4 个 HDR NIC 的 NIC 插槽 4 和 5 连接到两个采用传统存储网络配置的 DGX A100 。 IO 大小为 1MB 。通常情况下,绝对性能随着使用的线程数的增加而提高(图 4 )。与没有 GDS 的情况相比, GDS 的相对改进在线程数量方面仍然相当稳定,但在线程数量较少的情况下显然是最好的。
展馆数据结果
Pavilion 为分布式并行文件系统、块和对象接口提供存储解决方案。它使用 NFSoRDMA 启用 GDS 。 Pavilion Data 提供占用四个机架单元( RU )的存储节点,提供足够的带宽,其中两个节点可以使四个 DGX A100 上的两个 NIC 或单个 DGX A100 上的八个 NIC 达到饱和。图 5 中的结果仅来自实验配置, Pavilion 软件版本 2 执行文件访问。
Liqid 结果
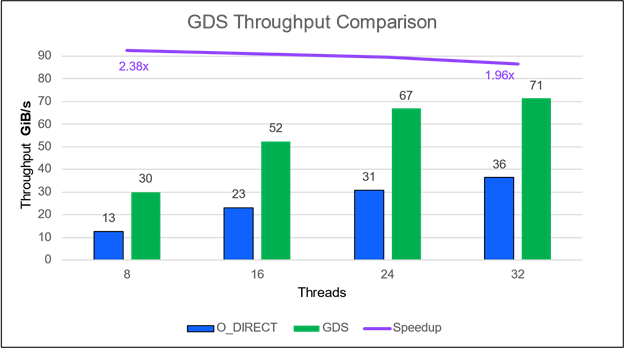
最近在 Liqid 系统上测量的性能表明,基于 PCIe 的 P2P 路径比基于以太网/ InfiniBand 的 NVMe 更快。 GPU 和与 GDS 集成的 SSD 之间的 P2P 通信达到 2900K IOPS ,吞吐量提高了 16 倍。与非 GDS 路径相比,延迟从 712 us 提高了 1 . 86 倍至 112 us (图 6 )。
GPU 到 SSD 且禁用 P2P
IOPS 潜伏期: 712 us
GPU 到 SSD ,带启用 GDS 的 P2P
IOPS 潜伏期: 112 us
收集了三种不同配置的数据:
- 配置 1 : GPU – 到 NVMe 。使用 Liqid 结构连接同一 PCIe 结构上的所有设备。
- 配置# 2 : GPU – 到 – CPU – 到 NVMe 。将 GPU 和 NVMe 驱动器直接连接到 CPU 主板。
- 配置# 3 : GPU – 到的 NIC NVMe 。使用 GPU 到( CX-5 )的 NVMe 通过网络访问远程 NVMe 。
以下是配置的详细信息:
- 主板: AsROCK 机架 ROME8D-2T ,配备 AMD Epyc 7702p 、 512GB DDR4 2933
- 系统软件: Ubuntu 服务器 20 . 04 . 2 , NVIDIA 驱动程序版本 470 . 63 . 01 , CUDA 11 . 4
- Liqid QD4500 配备 Phison E16 800GB 、 Gen4 PCIe 、运行 Liqid v3 . 0 的 24 端口 Gen4 数据交换机( Astek )的 24 端口管理交换机( TOR )
- NVIDIA A100 40GB , PCIe Gen4 与 LQS4500 位于同一 PCIe 交换机上
- BIOS 设置 ACS = Off ,在 Liqid 中启用 P2P 。
图 6 。 GPU 和 SSD (或 NVMe 驱动器)之间的点对点( P2P )通信通过 GPU 直接存储实现了几个数量级的 IOPS 改进.GPU Liqid Matrix 扩展机箱中的直接存储支持 GPU 和 SSD 之间的直接 P2P 通信,实现了高达 1620% 的 IOPS 加速和 86% 的延迟改善.
InfiniBand 和以太网
虽然 Infiniband 在传统 HPC 系统中很受欢迎,但以太网在企业数据中心中有着广泛的应用。 GDS 在以太网和 IB 上无处不在。关键要求是底层系统和远程文件管理器支持 RDMA 。这在 RoCE 中是可能的。
那么,两者之间的比较如何呢?以下是初步调查的一些结果。对通过扩展网络访问存储的全面分析不在本文讨论范围之内,但对于那些希望就其网络设计做出数据驱动决策的人来说,这是值得鼓励的。
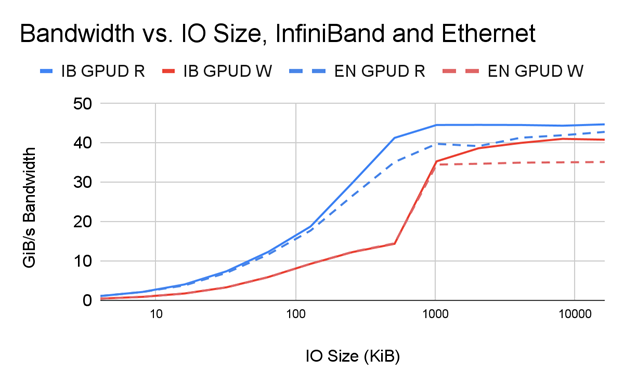
图 7 显示了在以下条件下带宽随 IO 大小变化的并排比较:
- 单个 PCIe 树中的两个 NIC 使用 InfiniBand 连接到一个 DDN AI400x 文件服务器
- 单个 PCIe 树中的两个 NIC 使用以太网连接到同一 DDN AI400x 文件服务器
如您所见, IB 和带有 GDS 的以太网的性能相当, GDS 显然是建立在 GPU 直接 RDMA 之上的。 IB 比以太网具有高达 1 . 17 倍的性能优势,尤其是在性能最高且网络速度差异最大的更大 IO 尺寸下。
社区光泽
不同的供应商为 Lustre 的社区版本增加了自己的价值。但我们的一些客户仅限于使用 OSS 社区 Lustre 。他们还能在非专有解决方案中享受 GDS 的好处吗?答案是肯定的!
与不使用 GDS 相比, GDS 的带宽、延迟和 CPU 利用率增益都与其他启用 GDS 的实现类似。可下载版本 2 . 15 的每个发行版本。今天就试试吧!
混搭
我们在 NVIDIA 有一个实验集群,我们称之为 ForMIO (用于 Magnum IO ),因为它用于评估和审查与 Magnum IO ( MIO )相关的各种技术。 DDN 和 Pavilion 慷慨地让我们使用他们的设备进行文件管理。媒体供应商 Kioxia 、 Micron 和 Samsung 慷慨捐赠了驱动器来填充其中一些文件服务器。我们很兴奋,因为这加快了对 DL 框架和使用 GDS 的客户应用程序的评估。
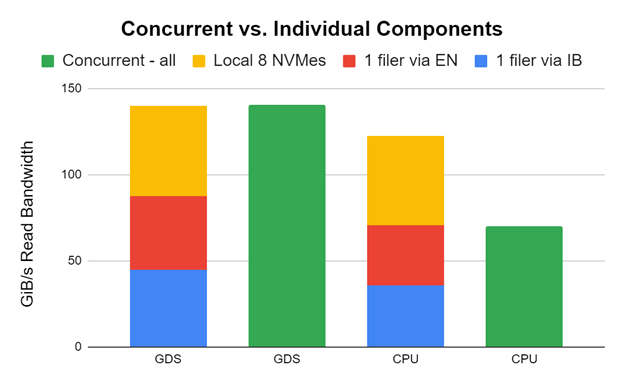
我们做了一些疯狂的尝试,结果成功了!我们使用两个 HDR 200 NIC 将一个 DDN AI400x 与 InfiniBand 连接起来,一个 DDN AI400s 与两个 HDR 200 NIC 的以太网连接起来,八个本地 NVME 与一个 DGX A100 连接起来。我们使用 GDSIO 性能评估工具对所有客户进行了测试。
图 8 中的早期和未调整的结果显示,存储带宽可以跨这些应用程序组合,以向应用程序提供带宽。虽然我们在实践中不一定推荐这一点,但知道这是可能的还是很酷的。感谢 DDN 支持实现这一点。
在单个 DGX A100 上分别(红色、蓝色、黄色)和同时(绿色)测量带有 InfiniBand 的一个 DDN AI400x (使用两个 HDR 200 NIC )、带有以太网的一个 DDN AI400s (使用两个 HDR 200 NIC )和八个本地 NVME 的性能。单个组件堆叠在每对的左侧。当它们都同时运行时,绿色条显示性能。
在 GDS 的情况下,性能完全匹配,因为 GPU 目标被仔细选择为无干扰。在 CPU 中使用跳出缓冲区的非 GDS 情况下,进出 CPU 的拥塞会抑制并发性能。这是一个巨大的不同。
摘要
我们鼓励您基于目前通用的产品部署生产解决方案,并考虑将新出现的解决方案纳入下一代系统。 GPU Direct Storage 现已在 v1 . 0 版中全面提供,更多的供应商合作伙伴正在将支持 GDS 的产品转移到 GA 状态。还有一系列案例研究,涵盖存储框架、深度学习、地震、数据分析和数据库。
在 GDS 上合作
NVIDIA 鼓励与供应商合作伙伴和客户接触,并提供清晰的使用案例。如果您感兴趣,reach out to our team。我们希望更多地了解您即将推出的支持 GDS 的端到端扩展存储解决方案。我们向准备使用 GDS 启用存储驱动程序的供应商合作伙伴推荐以下资源:
- 有关最终客户和 OEM ,请参阅NVIDIA GPUDirect Storage Design Guide。
- 有关最终客户、 OEM 和合作伙伴,请参阅NVIDIA GPUDirect Storage Overview Guide。
- 有关使用 GDS 编程的更多信息,请参阅cuFile API Reference Guide。
- 有关在存储系统中启用 GDS 或通过供应商合作伙伴支持工作的更多信息,请参阅NVIDIA GPUDirect Storage O_DIRECT Requirements Guide。
- 有关一般信息,请参阅NVIDIA GPUDirect Storage文档。
- 有关视频说明,请参阅Accelerating Storage with Magnum IO and GPUDirect Storage GTC 2020 课程。
我们希望您能加入即将到来的 SC21 鸟类功能会话Accelerating Storage IO to GPUs。
为 GDS 做出贡献
这里描述的 GDS 内核驱动程序nvidia-fs.ko是开源的。在MagnumIO/tree/main/gds GitHub repo 中,有一些代码签入主线或作为社区已开始贡献的请求提供,以加速开发并提高社区范围内的性能。来加入社区,关注新的开发空间吧!
致谢
感谢以下授予或出借设备进行评估的供应商,或向 NVIDIA 提供其 OEM 平台或其组件上的性能表征数据的供应商: DELL Technologies 、 DDN 、 Excelero 、 IBM 、 Kioxia 、 Micron 、 Pavilion 、三星、 ScaleFlux 、 VAST 和 Weka 。




