
거대 언어 모델(LLM)은 엔터프라이즈 조직 전반에서 점점 더 많이 채택되고 있으며, 많은 기업이 이를 AI 애플리케이션에 구축하고 있습니다. 파운데이션 모델은 강력한 시작이지만 프로덕션 준비가 완료된 환경을 구축하려면 많은 작업이 필요합니다. NVIDIA NIM은 이 프로세스를 단순화하여 조직이 데이터센터, 클라우드, 워크스테이션, PC 전반의 어디에서나 AI 모델을 실행할 수 있도록 지원합니다.
엔터프라이즈용으로 설계된 NIM은 기존 인프라에 쉽게 통합되는 사전 구축된 클라우드 기반 마이크로서비스의 포괄적인 제품군을 제공합니다. 이러한 마이크로서비스는 유지 관리되고 지속적으로 업데이트되어 기본 성능을 제공하고 AI 추론 기술의 최신 발전 사항에 대한 액세스를 보장합니다.
LLM을 위한 새로운 NVIDIA NIM
파운데이션 모델의 성장은 다양한 엔터프라이즈 요구 사항을 충족할 수 있는 능력 때문입니다. 단일 모델도 조직의 요구 사항을 충족할 수 없으며, 일반적으로 기업은 특정 데이터 요구 사항 및 AI 애플리케이션 워크플로우를 기반으로 사용 사례 전반에 걸쳐 다양한 파운데이션 모델을 사용합니다.
NVIDIA는 엔터프라이즈의 다양한 요구 사항을 수용하여 Mistral -7B, Mixtral-8x7B, Mixtral-8x22B를 포함하도록 NIM 제품을 확장했습니다. 각 파운데이션 모델은 각 작업에서 뛰어난 성능을 보입니다.
Mistral 7B NIM
Mistral 7B Instruct 모델은 텍스트 생성 및 언어 이해 작업에서 탁월한 성능을 보이며 단일 GPU에 적합하므로 언어 번역, 콘텐츠 생성, 챗봇과 같은 애플리케이션에 완벽한 제품입니다. NVIDIA H100 데이터센터 GPU에 Mistral 7B NIM을 배포할 때 개발자는 NIM 없이 모델을 배포할 때와 비교하여 콘텐츠를 생성하는 데 초당 최대 2.3배의 즉각적인 성능 향상을 달성할 수 있습니다.
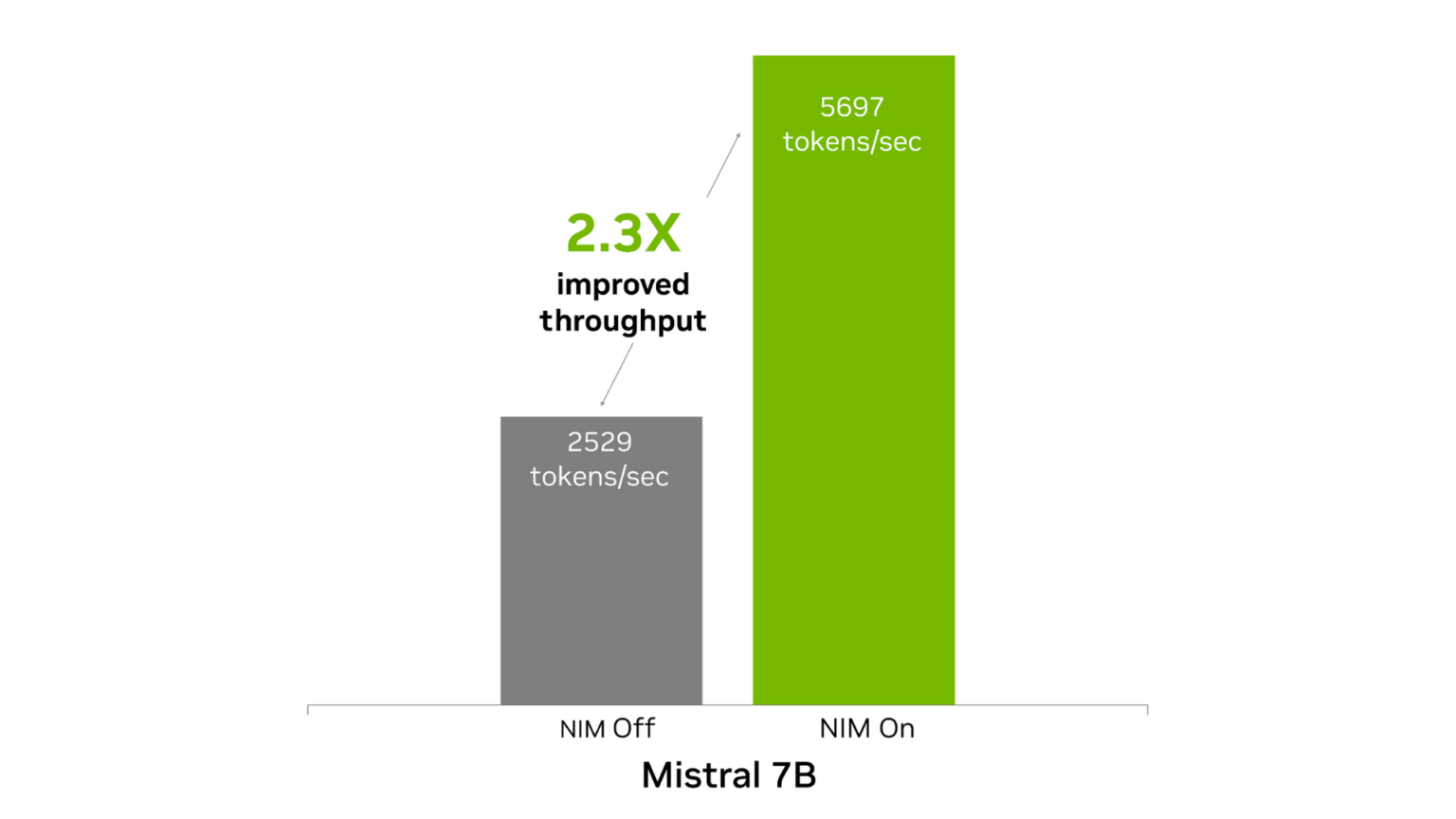
입력: 토큰 500개, 출력: 토큰 2,000개. NIM 켬: FP8. 처리량 5,697토큰/초, TTFT 0.6초, ITL: 26밀리초. NIM 꺼짐: FP16, 처리량 2,529 토큰/초, TTFT: 1.4초, ITL: 1xH100에서 60밀리초
Mixtral-8x7B 및 Mixtral-8x22B NIM
Mixtral-8x7B 및 Mixtral-8x22B 모델은 Mixture of Experts(MoE) 아키텍처를 활용하여 빠르고 비용 효율적인 추론을 제공합니다. 이러한 모델은 요약, 질문 답변, 코드 생성과 같은 작업에서 탁월한 성능을 발휘하며 실시간 응답이 필요한 애플리케이션에 이상적입니다.
NIM은 이러한 두 모델 모두에 즉시 최적화된 성능을 제공합니다. 콘텐츠 생성에 사용하는 경우 Mixtral-8x7B NIM은 4개의 H100에서 최대 4.1배 향상된 처리량을 보여줍니다. Mixtral-8x22B NIM은 콘텐츠 생성 및 번역 사용 사례에 대해 8개의 H100에서 최대 2.9배 향상된 처리량을 보여줍니다.
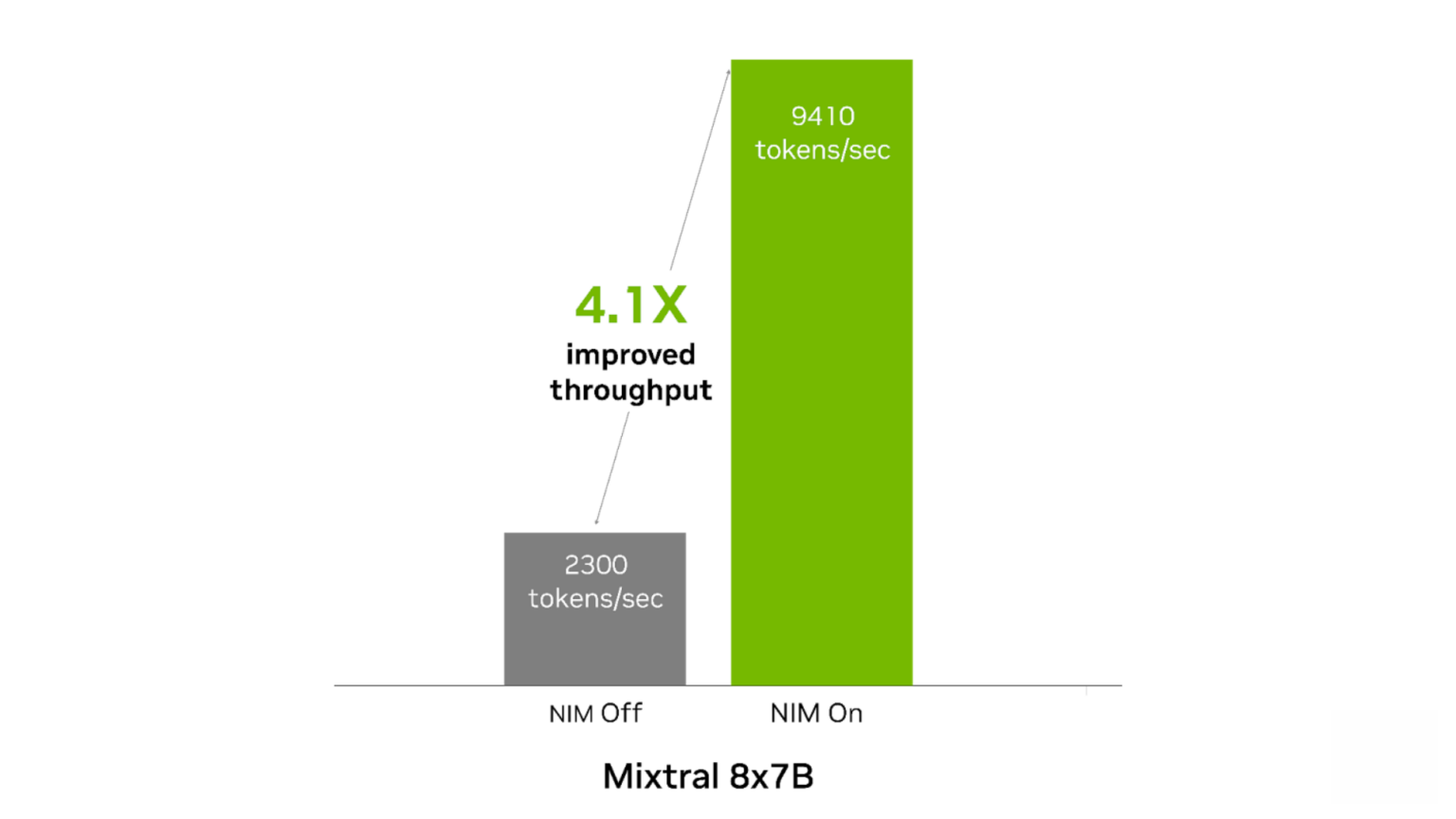
입력: 토큰 500개, 출력: 토큰 2,000개. 동시 요청 200개. NIM 켜짐: FP8. 처리량 9,410토큰/초. TTFT 740밀리초, ITL 21밀리초. NIM 꺼짐: FP16. 처리량 2,300토큰/초, TTFT 1,321밀리초, ITL 86밀리초
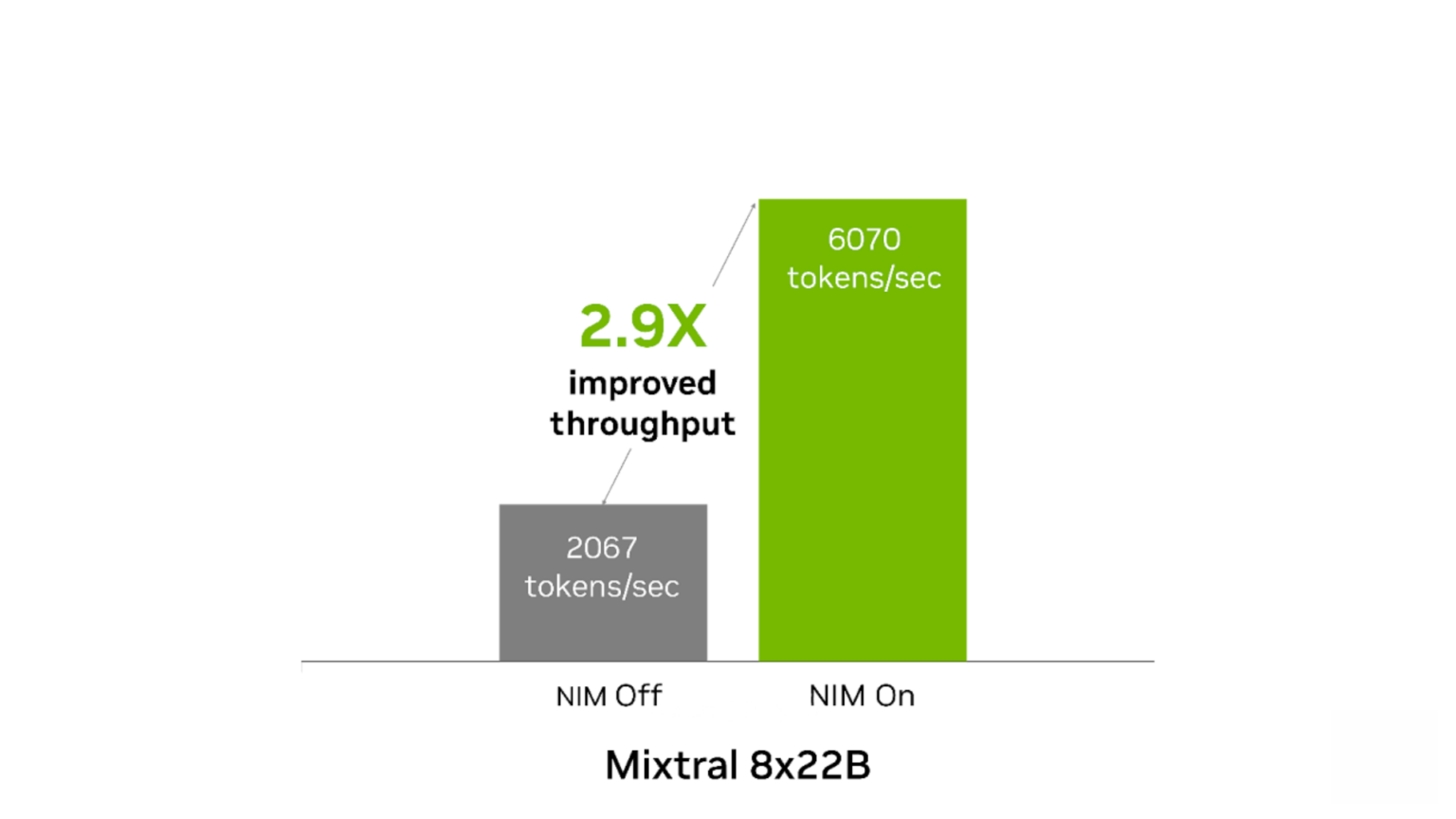
입력: 토큰 1,000개, 출력: 토큰 1,000개. 동시 요청 250개. NIM 켜짐: 처리량 6,070토큰/초, TTFT 3초, ITL 38밀리초. NIM 꺼짐: 처리량 2,067토큰/초, TTFT 5초, ITL 116밀리초.
NVIDIA NIM을 통해 AI 애플리케이션 배포 가속화
개발자는 NIM을 사용하여 프로덕션 배포를 위한 AI 애플리케이션을 구축하는 데 걸리는 시간을 단축하고, AI 추론 효율성을 향상하며, 운영 비용을 절감할 수 있습니다. NIM을 사용하면 최적화된 AI 모델이 컨테이너화되어 개발자에게 다음과 같은 이점을 제공합니다.
성능 및 확장성
이러한 클라우드 기반 마이크로서비스는 쉽게 확장되는 짧은 지연 시간, 높은 처리량의 AI 추론을 제공하여 Llama 3 70B NIM을 통해 최대 5배 높은 처리량을 제공합니다. NIM은 AI 추론 성능을 더욱 향상하여 처음부터 시작하지 않고도 탁월한 정확도를 위해 정밀하고 파인튜닝된 모델도 지원합니다.
사용 편의성
기존 시스템으로의 통합을 간소화하여 시장 진입을 가속화하고 NVIDIA 가속 인프라에서 최적화된 성능을 제공합니다. 엔터프라이즈용으로 설계된 API 및 도구를 통해 개발자는 AI 기능을 극대화할 수 있습니다.
보안 및 관리 용이성
AI 애플리케이션 및 데이터에 대한 강력한 제어 및 보안을 보장합니다. NIM은 NVIDIA AI Enterprise를 통해 모든 인프라에서 유연한 셀프 호스팅 배포를 지원하며, 엔터프라이즈급 소프트웨어, 엄격한 검증, NVIDIA AI 전문가와의 직접적인 상담을 제공합니다.
AI 추론의 미래: NVIDIA NIM과 그 이상
NVIDIA NIM은 AI 추론의 중요한 발전을 나타냅니다. 다양한 산업 전반에서 AI 기반 애플리케이션의 필요성이 커짐에 따라 이러한 애플리케이션을 효율적으로 배포하는 것이 중요해지고 있습니다. AI의 혁신적인 성능을 활용하려는 엔터프라이즈는 NVIDIA NIM을 사용하여 사전 구축된 클라우드 기반 마이크로서비스를 기존 시스템에 쉽게 통합할 수 있습니다. 이를 통해 제품 출시 속도를 높이고 앞서 나갈 수 있습니다.
AI 추론은 개별 NVIDIA NIM을 뛰어넘는 미래입니다. 고급 AI 애플리케이션에 대한 수요가 증가함에 따라 여러 NVIDIA NIM을 연결하는 것이 중요해질 것입니다. 이 마이크로서비스 네트워크는 함께 작동하고 다양한 작업에 적응할 수 있는 더 스마트한 애플리케이션을 지원하여 기술 사용 방식을 혁신할 것입니다. 인프라에 NIM 추론 마이크로서비스를 배포하려면 NVIDIA NIM을 통한 생성형 AI 배포를 위한 간단한 가이드를 확인하세요.
NVIDIA는 정기적으로 새로운 NIM을 출시하여 엔터프라이즈 애플리케이션을 지원하는 가장 강력한 AI 모델을 제공합니다. API 카탈로그를 방문하여 LLM, 비전, 검색, 3D, 디지털 생물학 모델에 대한 최신 NVIDIA NIM을 확인하세요.
관련 리소스
- GTC 세션: 생성형 AI 극장: Mixtral of Experts 설명
- GTC 세션: Mistral AI: 프론티어 AI 경험
- GTC 세션: 오픈 소스 LLM 애플리케이션을 위한 GPU는? 추론 성능 인사이트(발표: NexGen)
- NGC 컨테이너: Mistral-7B-Instruct-v0.3
- NGC 컨테이너: Mixtral-8x7B-Instruct-v0.1
- NGC 컨테이너: Mixtral-8x22B-Instruct-v0.1