
NVIDIA는 MLPerf 추론 v3.0에서 새롭게 도입된 네트워크 부문을 처음으로 제출했으며, 이는 이제 MLPerf 추론 데이터센터 제품군의 일부가 되었습니다. 네트워크 부문은 실제 데이터 센터 설정을 시뮬레이션하도록 설계되었으며 하드웨어와 소프트웨어를 포함한 네트워킹의 효과를 엔드투엔드 추론 성능에 포함하기 위해 노력하고 있습니다.
네트워크 디비전(Division)에는 두 가지 유형의 노드가 있습니다: 프론트엔드 노드는 쿼리를 생성하고, 이 쿼리는 네트워크를 통해 전송되어 추론을 수행하는 액셀러레이터 노드에서 처리합니다. 이들은 이더넷이나 InfiniBand와 같은 표준 네트워크 패브릭을 통해 연결됩니다.
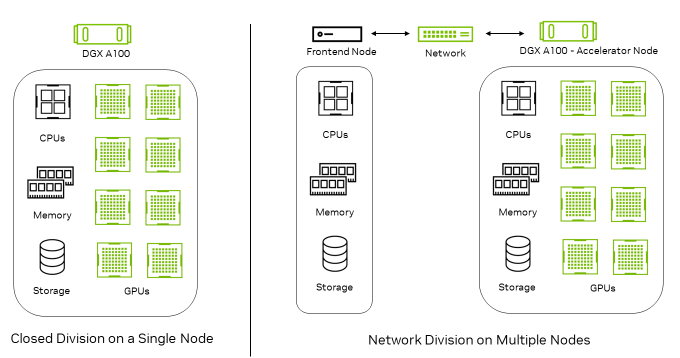
그림 1은 폐쇄형 디비전이 전적으로 단일 노드에서 실행됨을 보여줍니다. 네트워크 부문에서 쿼리는 프론트엔드 노드에서 생성되어 추론을 위해 액셀러레이터 노드로 전송됩니다.
네트워크 부문에서 가속기 노드는 추론 가속기뿐만 아니라 모든 네트워킹 구성 요소를 통합합니다. 여기에는 네트워크 인터페이스 컨트롤러(NIC), 네트워크 스위치, 네트워크 패브릭이 포함됩니다. 따라서 네트워크 부문에서는 가속기 노드와 네트워크의 성능을 측정하려고 하지만, 프론트엔드 노드는 벤치마킹에서 제한적인 역할을 하므로 그 영향은 제외됩니다.
MLPerf 추론 v3.0 네트워크 부문의 NVIDIA 성능
MLPerf Inference v3.0에서 NVIDIA는 ResNet-50 및 BERT 워크로드 모두에서 네트워크 부문을 제출했습니다. NVIDIA는 NVIDIA ConnectX-6 InfiniBand 스마트 어댑터 카드에서 매우 높은 네트워크 대역폭과 짧은 지연 시간을 제공하는 GPUDirect RDMA 기술을 사용하여 ResNet-50에서 단일 노드 성능의 100%를 달성했습니다.
| 벤치마크 | DGX A100 (8x A100 80GB) | 네트워크 디비전과 폐쇄 디비전의 성능 비교 |
| ResNet-50(낮은 정확도) | Offline | 100% |
| 서버 | 100% | |
| BERT (낮은 정확도) | Offline | 94% |
| 서버 | 96% | |
| BERT (높은 정확도) | Offline | 90% |
| 서버 | 96% |
NVIDIA 플랫폼은 또한 호스트 측 배치 오버헤드로 인해 해당 비공개 디비전 제출에 비해 약간의 성능 영향만 관찰된 가운데 BERT 워크로드에서 뛰어난 성능을 보여주었습니다.
NVIDIA 네트워크 부문 출품작에 사용된 기술
다양한 풀스택 기술이 강력한 NVIDIA 네트워크 부문의 성능을 가능하게 했습니다:
- 최적화된 추론 엔진을 위한 NVIDIA TensorRT 백엔드
- Mellanox OFED 소프트웨어 스택의 IBV 버브(Verb)를 기반으로 구축된 지연 시간이 짧고 처리량이 높은 텐서 통신을 위한 InfiniBand RDMA 네트워크 전송
- 구성 교환, 실행 상태 동기화 및 하트비트 모니터링을 위한 이더넷 TCP 소켓
- 최상의 성능을 위해 CPU, GPU 및 NIC 리소스를 사용하는 NUMA 인식 구현
네트워크 분할 구현 세부 정보
MLPerf 추론 네트워크 부문의 구현 세부 사항을 자세히 살펴보세요:
- 처리량이 많고 지연 시간이 짧은 통신을 위한 InfiniBand
- 네트워크 분할 추론 흐름
- 성능 최적화
높은 처리량, 저지연 통신을 위한 InfiniBand
네트워크 부문에서는 제출자가 로드 생성기에서 쿼리를 가져와서 제출자의 설정에 적합한 방식으로 가속기 노드에 보내는 쿼리 디스패치 라이브러리(QDL)를 구현해야 합니다.
- 입력 텐서 시퀀스가 생성되는 프론트엔드 노드에서 QDL은 LoadGen 시스템 언더 테스트(SUT) API를 추상화하여 로컬에서 가속기를 테스트할 수 있는 것으로 MLPerf 추론 LoadGen에 표시합니다.
- 가속기 노드에서 QDL은 추론 요청 및 응답을 위해 LoadGen과 직접 상호 작용하는 것처럼 보이게 합니다. NVIDIA가 구현한 QDL 내에서 InfiniBand IBV 동사와 이더넷 TCP 소켓을 사용하여 원활한 데이터 통신 및 동기화를 구현합니다.
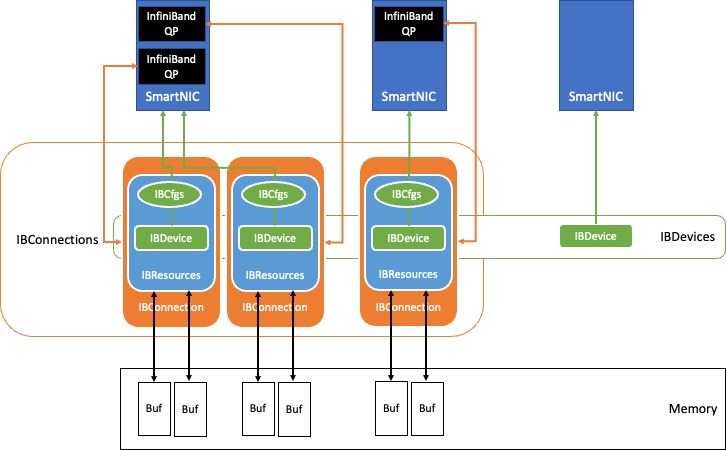
그림 2는 InfiniBand 기술이 적용된 QDL에 내장된 데이터 교환 컴포넌트를 보여줍니다.
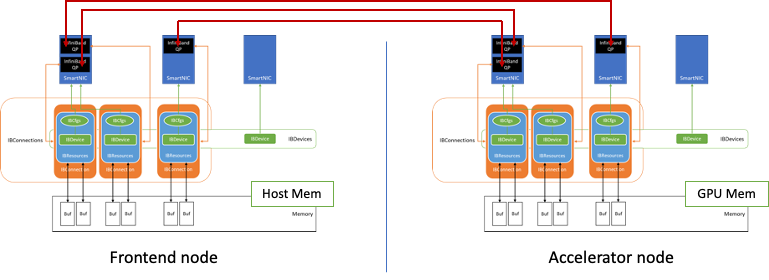
그림 3은 이 데이터 교환 구성 요소를 사용하여 두 노드 간에 연결이 설정되는 방법을 보여줍니다.
인피니밴드 큐(Queue) 쌍(QP)은 노드 간의 기본 연결 지점입니다. NVIDIA 구현은 TCP와 유사한 무손실 신뢰성 연결(RC)과 전송 모드를 사용하며, 최대 초당 200Gbits의 처리량을 유지하기 위해 InfiniBand HDR 옵티컬 패브릭 솔루션을 사용합니다.
벤치마킹이 시작되면 QDL 초기화가 시스템에서 사용 가능한 InfiniBand NIC를 검색합니다. IBCfgs에 저장된 구성에 따라 사용하도록 지정된 NIC가 IBDevice 인스턴스로 채워집니다. 이 인플레이션 중에 RDMA 전송을 위한 메모리 영역이 할당, 고정 및 RDMA 버퍼로 등록되어 적절한 핸들과 함께 IBResources에 보관됩니다.
가속기 노드의 RDMA 버퍼는 GPU 메모리에 상주하여 GPUDirect RDMA를 활용합니다. 그런 다음 RDMA 버퍼 정보와 적절한 보호 키가 이더넷을 통해 TCP 소켓을 통해 피어 노드와 통신합니다. 이렇게 하면 QDL에 대한 IBConnection 인스턴스가 생성됩니다.
QDL 구현은 NUMA를 인식하며 가장 가까운 NUMA 호스트 메모리, CPU, GPU를 각 NIC에 매핑합니다. 각 NIC는 IBConnection을 사용하여 피어의 NIC와 통신합니다.
네트워크 분할 추론 흐름
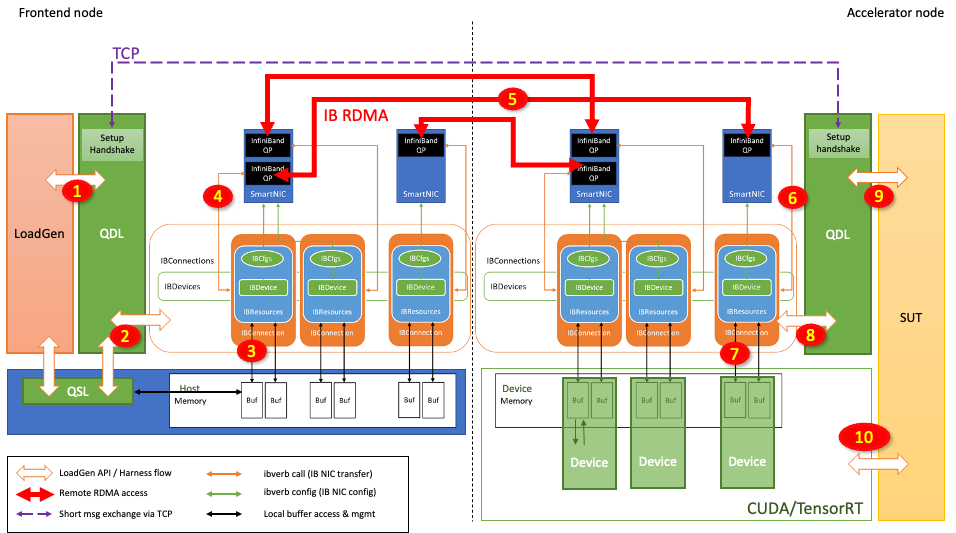
그림 4는 프론트엔드 노드에서 추론 요청이 전송되어 액셀러레이터 노드에서 처리되는 과정을 보여줍니다:
- LoadGen은 입력 텐서(tensor)를 포함하는 쿼리(추론 요청)를 생성합니다.
- QDL은 중재 체계에 따라 이 쿼리를 적절한 IBConnection으로 리디렉션합니다.
- 쿼리 샘플 라이브러리(QSL)가 RDMA 버퍼 내에 이미 등록되어 있을 수 있습니다. 그렇지 않은 경우 QDL은 쿼리를 RDMA 버퍼로 스테이징(복사)합니다.
- QDL은 연결된 QP로 RDMA 전송을 시작합니다.
- 인피니밴드 네트워크 전송은 네트워크 스위치를 통해 이루어집니다.
- 쿼리가 피어의 QP에 도착합니다.
- 그런 다음 쿼리는 직접 메모리 액세스를 통해 대상 RDMA 버퍼로 전송됩니다.
- RDMA 완료는 가속기 노드 QDL에서 확인됩니다.
- QDL은 액셀러레이터 노드가 이 쿼리를 일괄 처리할 수 있도록 합니다. QDL은 쿼리 일괄 처리를 액셀러레이터 노드의 액셀러레이터 중 하나에 발급하도록 태그를 지정합니다.
- 가속기 노드의 가속기는 CUDA 및 TensorRT를 사용하여 추론을 수행하고 RDMA 버퍼에 응답을 생성합니다.
10단계에서와 같이 추론이 최종적으로 수행되면 출력 텐서가 생성되어 RDMA 버퍼(buffer)에 채워집니다. 그런 다음 가속기 노드는 비슷한 방식으로 응답 텐서를 프론트엔드 노드로 전송하기 시작하지만 반대 방향으로 전송합니다.
성능 최적화
NVIDIA 구현은 InfiniBand RDMA 쓰기를 사용하며 가장 짧은 지연 시간을 활용합니다. RDMA 쓰기가 성공적으로 수행되려면 발신자가 대상 메모리 버퍼를 명시적으로 관리해야 합니다.
프론트엔드 노드와 액셀러레이터 노드 모두 버퍼(buffer) 추적기를 관리하여 각 쿼리와 응답이 소비될 때까지 메모리에 유지되도록 합니다. 예를 들어, ResNet-50은 성능을 유지하기 위해 연결(QP) 당 최대 8K 트랜잭션을 관리해야 합니다.
다음 주요 최적화 중 일부는 NVIDIA 솔루션 구현에 포함되어 있습니다.
다음 주요 최적화는 더 나은 확장성을 지원합니다:
- IBConnection(QP) 당 트랜잭션 트래커: 각 IBConnection에는 격리된 트랜잭션 트래커가 있어 잠금이 없는 연결 내 트랜잭션 북키핑이 가능합니다.
- NIC당 다중 QP 지원: 임의의 수의 IBConnections를 모든 NIC에 인스턴스화할 수 있으므로 많은 수의 트랜잭션을 자발적으로 쉽게 지원할 수 있습니다.
다음과 같은 주요 최적화를 통해 InfiniBand 리소스 효율성이 향상됩니다:
- 소규모 메시지에 인라인 전송 사용: INLINE 전송을 통해 작은 메시지(일반적으로 64바이트 미만)를 전송하면 PCIe 전송을 피할 수 있어 성능과 효율성이 크게 향상됩니다.
- 시그널링되지 않은 RDMA 쓰기 사용: 시그널링되지 않은 트랜잭션은 시그널링된 트랜잭션이 발생할 때까지 CQ에서 대기하여 동일한 노드에서 지금까지 대기 중인 모든 트랜잭션의 완료 처리(일괄 완료)를 트리거하므로 CQ 유지 관리가 훨씬 더 효율적입니다.
- 요청된 IB 전송 사용: 요청되지 않은 RDAM 트랜잭션은 요청된 RDMA 트랜잭션이 발생할 때까지 원격 노드에 큐에 대기하여 원격 노드에서 일괄 완료를 트리거할 수 있습니다.
- 이벤트 기반 CQ 관리: CQ 관리를 위한 바쁜 대기를 피하면 CPU 주기를 확보할 수 있습니다.
다음과 같은 주요 최적화를 통해 메모리 시스템 효율성이 향상됩니다:
- 프론트엔드 노드에서 스테이징 없이 RDMA 전송: 입력 텐서를 전송할 때 RDMA에 등록된 메모리에 입력 텐서를 채워 호스트 메모리 복사본을 피합니다.
- 가속기 노드에서 멤피스(memcpys)를 집계(CUDA): 연속된 메모리에 텐서를 최대한 많이 모아서 GPU 메모리 복사 및 PCIe 전송의 효율성을 개선합니다.
각 공급업체의 QP 구현에는 지원되는 최대 완료 대기열 항목(CQE) 수와 지원되는 최대 QP 항목 크기가 자세히 나와 있습니다. 최대 처리량을 달성할 수 있는 충분한 트랜잭션을 즉각적으로 유지하면서 지연 시간을 감당할 수 있도록 NIC당 QP의 수를 확장하는 것이 중요합니다.
또한 폴링(polling)에 의한 CQ에서 단시간에 매우 많은 수의 트랜잭션을 처리하는 경우 호스트 CPU에 상당한 스트레스를 줄 수 있습니다. 이 경우 알림 횟수 감소와 함께 이벤트 기반 CQ 관리가 큰 도움이 됩니다. 가능한 한 인접한 공간에, 그리고 가능하면 RDMA에 등록된 메모리 공간에 데이터를 집계하여 메모리 액세스 효율성을 극대화합니다. 이는 최대 성능을 달성하는 데 매우 중요합니다.
요약
NVIDIA 플랫폼은 MLPerf 추론 부문에서의 지속적인 성능 리더십을 바탕으로 첫 번째 네트워크 부문 출품작에서 탁월한 성능을 제공했습니다: 데이터센터 폐쇄 부문. 이러한 결과는 다양한 NVIDIA 플랫폼 기능을 사용하여 달성되었습니다:
NVIDIA A100 텐서 코어 GPU
NVIDIA DGX A100
NVIDIA ConnectX-6 InfiniBand 네트워킹
NVIDIA TensorRT
GPUDirect RDMA
이 결과는 업계 표준의 동료 검토 벤치마크를 통해 실제 데이터센터 배포에서 NVIDIA AI 플랫폼의 성능과 범용성을 더욱 입증합니다.