회의, 통화, 복잡한 공간, 음성 지원 앱 등 어디에서나 기술이 직면하는 핵심 질문은 “누가 언제 말했는가?”라고 할 수 있는데요. 수십 년 동안, 실시간 전사에서 ‘누가 언제 말했는가’라는 질문에 정확히 답하는 것은 특수 장비나 오프라인 배치 처리 없이는 거의 불가능했습니다.
NVIDIA Streaming Sortformer는 이러한 문제를 해결하는 오픈소스 프로덕션급 화자 분리(diarization) 모델입니다. 실제 많은 사람들이 이야기하는 환경에서 지연 시간을 최소화하도록 설계되었으며, NVIDIA NeMo 및 NVIDIA Riva와 쉽게 통합됩니다. 이를 활용하면 전사 파이프라인, 실시간 보이스봇 운영, 엔터프라이즈 회의 분석 등 다양한 워크플로우에 바로 적용할 수 있습니다.
주요 기능
NVIDIA Streaming Sortformer는 다음과 같은 핵심 기능을 제공해 다양한 실시간 애플리케이션에서 강력하고 유용하게 활용될 수 있습니다.
- 프레임 단위 화자 분리 태깅 (예: spk_0, spk_1)
- 발화별 정밀 타임스탬프 제공
- 2~4명 이상의 화자를 저지연으로 안정적으로 추적
- GPU 기반 고효율 추론, NeMo 및 Riva 워크플로우에 즉시 활용 가능
- 영어 최적화 모델이지만, 중국어 회의 데이터와 4인 화자 CALLHOME 비영어 데이터셋에서도 낮은 DER을 기록해 다국어 환경에서도 강력한 성능 입증
벤치마크 결과
Streaming Sortformer는 DER(Diarization Error Rate, 화자 분리 오류율) 평가에서 뛰어난 성능을 보였습니다.

주요 활용 사례
Streaming Sortformer는 다양한 실시간 다화자 시나리오에서 실용적인 솔루션을 제공합니다.
- 회의 및 생산성: 실시간 화자 태그가 포함된 전사와 회의 요약
- 컨택 센터: 상담원/고객 발화를 분리해 QA·컴플라이언스 용도 활용
- 보이스봇 및 AI 비서: 자연스러운 대화 흐름, 올바른 턴테이킹, 화자 식별
- 미디어 및 방송: 자동 화자 라벨링을 통한 편집 및 모니터링 지원
- 엔터프라이즈 및 규제 준수: 규제 대응을 위한 화자 기반 로그 생성
아래 데모에서 직접 확인해 보실 수 있습니다.
아키텍처 및 내부 동작
Streaming Sortformer는 오디오 녹음에서 화자가 처음 등장한 시점을 기준으로 화자를 고유하게 정렬하는 화자 분리 모델입니다. 내부적으로는 인코더(encoder)처럼 동작하는데, 먼저 컨볼루션 기반 전처리(pre-encode) 모듈이 원시 오디오를 처리하고 압축합니다. 이후 일련의 Conformer 블록과 Transformer 블록을 거치면서 대화 맥락을 분석하고 화자를 구분·정렬합니다.
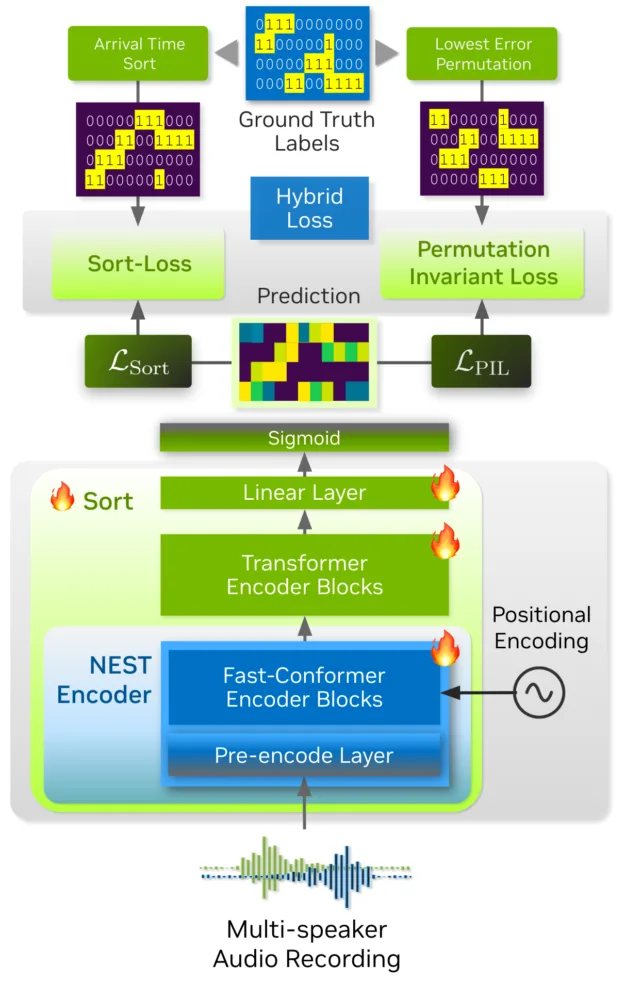
Streaming Sortformer는 실시간 오디오를 작은 겹치는 청크 단위로 분할해 처리합니다. 이 과정에서 도착 순서 화자 캐시(Arrival-Order Speaker Cache, AOSC) 라는 메모리 버퍼를 활용해, 오디오 스트림에서 지금까지 감지된 모든 화자를 추적합니다. 이를 통해 모델은 현재 청크에서 탐지된 화자를 이전 청크의 화자와 비교할 수 있으며, 같은 사람이 스트림 전체에서 일관되게 동일한 라벨로 식별되도록 보장합니다. 결과적으로 AOSC 버퍼는 실시간 다화자 추적을 정확하고 실용적으로 구현할 수 있게 해 줍니다.




책임 있는 AI, 한계점, 그리고 다음 단계
다음은 Streaming Sortformer를 사용할 때 고려해야 할 한계와 모범 사례입니다:
- 화자 수 제한: 최대 4명의 화자를 처리하도록 설계되었습니다. 4명 이상일 경우 성능이 저하되며, 현재는 4개 이상의 출력을 생성할 수 없습니다.
- 언어 최적화: 영어에 최적화되어 있으나, 중국어(만다린) 등 다른 언어에도 적용할 수 있습니다.
- 도메인/언어별 성능 향상: 특정 도메인이나 언어에서 최고의 성능을 내기 위해서는 fine-tuning을 권장합니다.
- 현실 환경 테스트: 겹치는 발화(overlap)에는 견고함을 보였으나, 매우 빠른 턴테이킹이나 심한 동시 발화 상황에서는 정확도가 떨어질 수 있습니다.
- 로드맵에는 다음과 같은 계획이 포함됩니다:
- 더 많은 화자를 처리할 수 있도록 확장
- 다양한 언어와 까다로운 음향 환경에서 성능 향상
- Riva 및 NeMo 기반 에이전틱/보이스봇 파이프라인과의 완전한 통합
맺음말
Streaming Sortformer는 연구용을 넘어, 실제 보이스 지원 멀티 화자 애플리케이션에서도 활용 가능한 오픈소스 실시간 화자 분리 솔루션입니다.
지금 바로 시작해보세요.
- Hugging Face에서 Streaming Sortformer를 다운로드, 배포 또는 테스트해 보세요. 지원 매트릭스도 함께 확인할 수 있습니다.
- NVIDIA Riva NIM을 활용해 ASR(음성 인식), TTS(음성 합성), 번역 기능을 NVIDIA AI Enterprise 지원과 함께 체험해 보세요.
- 질문이나 문제 해결이 필요하다면 NeMo GitHub, Riva Tutorials, 혹은 Riva 개발자 포럼을 방문하세요.
- 기술적 세부 내용과 Streaming Sortformer의 배경 연구가 궁금하다면, arXiv에 공개된 Offline Sortformer 최신 연구를 확인해 보세요.