
NVIDIA NeMo는 클라우드와 온프레미스를 포함하여 어디서든 규모별 멀티모달 생성형 AI 모델을 개발하기 위한 엔드 투 엔드 플랫폼입니다.
최근 NeMo 팀은 영어, 스페인어, 독일어, 프랑스어의 음성을 구두점 및 대문자까지 모두 전사하는 다국어 모델Canary를 출시했습니다. Canary는 영어와 다른 3가지 지원 언어 간의 양방향 번역도 제공합니다.
이 게시물에서는 Canary 모델과 사용 방법에 대해 자세히 설명합니다.
Canary 개요
Canary는 HuggingFace Open ASR 순위표에서 평균 6.67%의 단어 오류율(WER)로 1위를 기록했습니다. 다른 오픈 소스 모델에 비해 성능이 훨씬 뛰어납니다.
Canary는 공개 데이터와 사내 데이터의 조합으로 훈련되었습니다. 85,000시간 분량의 전사된 음성을 사용하여 음성 인식을 학습합니다. Canary에 번역을 가르치기 위해 NVIDIA NeMo 텍스트 번역 모델을 사용하여 지원되는 모든 언어로 원본 스크립트의 번역을 생성했습니다.
Canary는 훨씬 적은 양의 데이터를 사용함에도 불구하고 전사 및 번역 작업 시 유사한 크기의 모델인 Whisper-large-v3 및 SeamlessM4T-Medium-v1 모델을 능가합니다. 영어, 스페인어, 프랑스어, 독일어의 MCV 16.1 테스트 세트에서 Canary의 WER은 5.77이었습니다(그림 1).
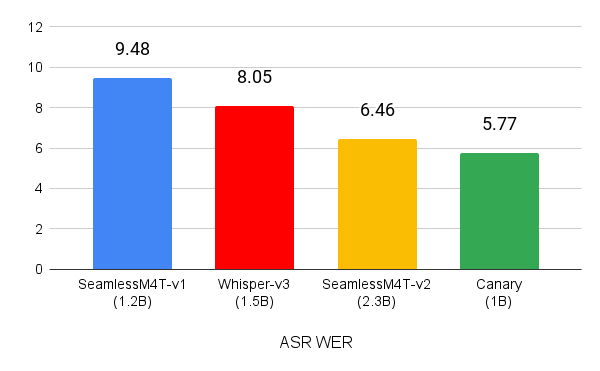
(낮을수록 좋음)
Gradio 데모에서 canary-1b 모델을 사용해 볼 수 있습니다. 로컬에서 Canary에 액세스하고 그 위에 구축하는 방법에 관한 자세한 내용은 NVIDIA/NeMo GitHub 리포지토리를 참조하세요.
Canary 아키텍처
Canary는 NVIDIA 혁신을 기반으로 구축된 인코더-디코더 모델입니다.
인코더는 컴퓨팅 성능을 최대 3배, 메모리를 최대 4배 절감하도록 최적화된 효율적인 Conformer 아키텍처 Fast-Conformer입니다. 인코더는 로그-멜 스펙트로그램 기능의 형태로 오디오를 처리하고, 트랜스포머 디코더는 자동 회귀 방식으로 출력 텍스트 토큰을 생성합니다. Canary가 전사와 번역 중 무엇을 수행할지 제어하는 특수 토큰이 디코더에 명령을 내립니다.
또한 Canary는 연결된 토크나이저를 통합하여 출력 토큰 공간을 명시적으로 제어합니다.
모델 가중치는 연구 친화적인 비상업적 CC BY-NC 4.0 라이선스에 따라 배포되며, 이 모델을 훈련하는 데 사용되는 코드는NeMo의 Apache 2.0 라이선스에 따라 사용 가능합니다.
Canary로 전사하는 방법
Canary를 사용하려면 NeMo를 pip 패키지로 설치해야 합니다. NeMo를 설치하기 전 Cython 및 PyTorch(2.0 이상)를 설치합니다.
pip install nemo_toolkit['asr']NeMo가 설치되면 Canary를 사용하여 오디오 파일을 전사하거나 번역합니다.
# Load Canary model
from nemo.collections.asr.models import EncDecMultiTaskModel
canary_model = EncDecMultiTaskModel.from_pretrained('nvidia/canary-1b')
# Transcribe
transcript = canary_model.transcribe(audio=["path_to_audio_file.wav"])
# By default, Canary assumes that input audio is in English and transcribes it.
# To transcribe in a different language, such as Spanish
transcript = canary_model.transcribe(
audio=["path_to_spanish_audio_file.wav"],
batch_size=1,
task='asr',
source_lang='es', # es: Spanish, fr: French, de: German
target_lang='es', # should be same as "source_lang" for 'asr'
pnc=True )
# To translate using Canary. For example, from English audio to French text
transcript = canary_model.transcribe(
audio=["path_to_english_audio_file.wav"],
batch_size=1,
task='ast',
source_lang='en',
target_lang='fr',
pnc=True )결론
Canary 다국어 모델은 영어, 스페인어, 독일어, 프랑스어에서 뛰어난 음성 인식 및 번역을 수행하며 새로운 표준으로 부상했습니다.
Canary 아키텍처에 관한 자세한 정보는 다음 리소스를 참조하시기 바랍니다.
Gradio 데모내에서 직접canary-1b를 사용해 보거나 NVIDIA/NeMoGitHub 리포지토리를 통해 모델에 로컬로 액세스하세요. Parakeet-CTC도 현재 이용 가능하며 다른 모델도 NVIDIA Riva의 일부로 곧 제공될 예정입니다.
NVIDIA API 카탈로그를 통해 AI 모델을 사용해 보고 NVIDIA NIM을 통해 온프레미스에서 실행하세요. 추가 탐색을 위해 NVIDIA LaunchPad는 프라이빗 호스팅 인프라에 필요한 하드웨어 및 소프트웨어 스택을 제공합니다.
도움 주신 분들
이 게시물에 기여해 주신 모델 작성자분들께 감사드립니다. Krishna Puvvada, Piotr Zelasko, He Huang, (Steve) Oleksii Hrinchuk, Nithin Koluguri, Somshubra Majumdar, Elena Rastorgueva, Kunal Dhawan, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris G
관련 리소스
GTC 세션: 다양한 언어로 파운데이션 거대 언어 모델 커스터마이징하기(NVIDIA NeMo)
GTC 세션: 파라미터 효율적 미세 조정(PEFT)을 사용한 거대 언어 모델 파인 튜닝
GTC 세션: NVIDIA NeMo 및 AWS를 사용한 LLM 트레이닝 최적화
NGC 컨테이너: 도메인별 NeMo ASR 애플리케이션
SDK: NeMo 메가트론
SDK: NeMo