
기업 환경에서 데이터는 끊임없이 변화하며, 이는 시간이 지남에 따라 AI 시스템의 정확도를 유지하는 데 상당한 도전 과제로 작용합니다. 비즈니스 프로세스를 최적화하기 위해 조직들이 에이전틱 AI 시스템에 점점 더 의존하면서, 이러한 시스템을 변화하는 비즈니스 요구와 새로운 데이터에 맞게 지속적으로 조정하는 것이 매우 중요해졌습니다.
이번 글에서는 NVIDIA NeMo 마이크로서비스를 활용해 데이터 플라이휠의 반복 사이클을 구축하는 방법을 살펴봅니다. 전체 파이프라인을 구축하기 위한 주요 단계도 간단히 소개합니다.
NeMo 마이크로서비스가 데이터 플라이휠 구축 중 마주하게 되는 다양한 문제를 어떻게 해결하는지에 대해서는, Maximize AI Agent Performance Using NVIDIA NeMo Microservices 문서를 참고해보세요.
에이전트 AI 성능 향상을 위한 핵심, 데이터 플라이휠
데이터 플라이휠은 자가 강화적인 순환 구조입니다. 사용자와의 상호작용을 통해 수집된 데이터는 AI 모델의 성능을 향상시키고, 개선된 모델은 더 정교하고 유용한 결과를 제공하여 더 많은 사용자를 끌어들입니다. 이로 인해 생성되는 추가 데이터는 다시 시스템의 전반적인 품질을 높이며, 이러한 선순환이 반복됩니다. 이는 개인이 업무를 수행하면서 경험을 쌓고 피드백을 반영해 꾸준히 역량을 키우는 방식과 유사합니다.
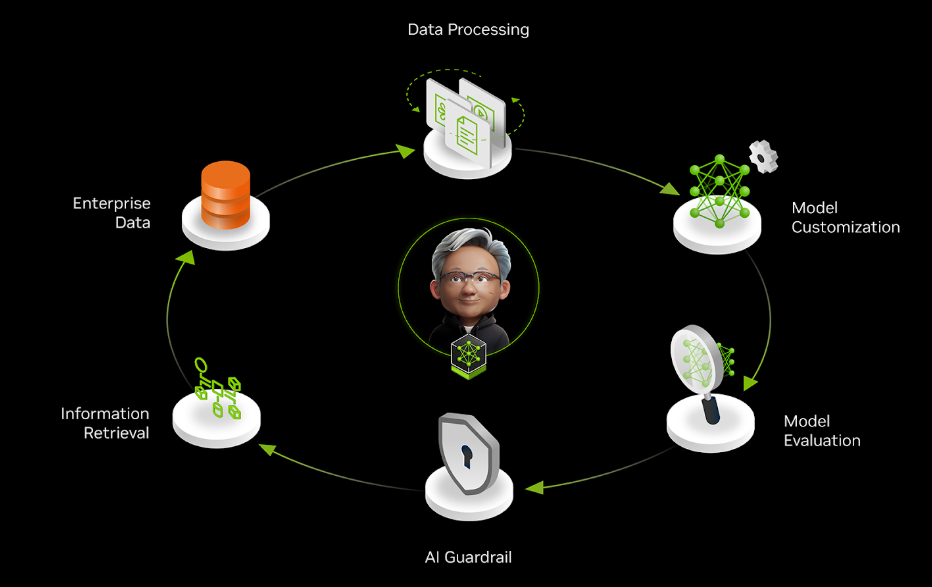
따라서 배포된 애플리케이션이 지속적으로 적응하고 높은 효율을 유지하려면, 에이전트 기반 시스템에 데이터 플라이휠을 도입하는 것이 필수적입니다.
지속적인 적용의 필요성
실제 운영 환경에서 AI 애플리케이션이 직면하는 핵심 과제 중 하나는 모델 드리프트입니다. 예를 들어, 사용자 질의를 특정 시스템으로 라우팅하는 AI 에이전트를 떠올려보면, 이 에이전트가 처리하는 입력 데이터, 사용하는 도구, 생성하는 출력 결과 모두 시간이 지나면서 지속적으로 변화합니다. 이러한 변화에 유연하게 대응할 수 있는 메커니즘이 없다면, 시스템의 정확도는 점차 떨어질 수밖에 없습니다. 그 주요 원인은 다음과 같습니다:
- 기업 지식 기반 및 문서의 지속적인 업데이트
- 사용자 행동과 질의 패턴의 변화
- 도구의 API와 응답 방식 변경
예를 들어, 고객 문의에 답변하기 위해 거래 내역 SQL(PostgreSQL) 데이터베이스를 조회하는 금융 분야의 거대 언어 모델(LLM) 에이전트를 살펴봅시다. 만약 조직이 새로운 MongoDB 데이터셋을 도입하고, 그 스키마와 응답 포맷까지 변경한다면, 이는 에이전트에게 큰 도전 과제가 됩니다. 재학습이 이뤄지지 않은 상태라면, 에이전트는 여전히 이전 구조에 맞춰 질의를 생성하게 되고, 이는 조회 실패나 잘못된 정보 제공으로 이어질 수 있습니다. 결과적으로 고객 신뢰를 떨어뜨리고, 더 나아가 컴플라이언스 문제까지 야기할 수 있습니다.
효율성에 대한 요구
AI 에이전트가 보다 복잡한 작업을 수행하게 되면서, 정확성과 관련성을 유지하는 일은 더욱 어려워지고 있습니다. 여기에 데이터 사용량이 증가하면서, 이러한 시스템을 운영하는 데 필요한 연산 비용 또한 급격히 늘어나고 있습니다. 특히 에이전트 기반 AI 시스템은 단순 추론 한 번으로 결과를 도출하는 기존 방식과 달리, 추론–계획–실행의 복합적인 단계를 거치므로 훨씬 더 많은 연산 자원을 소모하게 됩니다
예를 들어, 에이전트가 다양한 행동 옵션을 평가하고 여러 지식 소스를 조회하며 결과를 검증해야 하는 경우, 단일 추론 기반 모델에 비해 최대 5~10배 이상의 연산량이 필요할 수 있습니다. 이처럼 복잡성이 증가함에 따라 인프라 비용도 기하급수적으로 증가하게 됩니다.
이러한 문제를 해결하기 위해, 사용자 맞춤형 경량화 기법을 활용해 소형 모델을 대형 모델 수준의 정확도로 최적화하면, 지연 시간과 총소유비용(TCO)을 효과적으로 줄일 수 있습니다. 또한, 강력한 신규 모델들이 지속적으로 등장함에 따라, 사용자 상호작용 데이터를 기반으로 기본 모델과 fine-tuning된 버전을 지속적으로 평가하고 비교함으로써, 성능과 적응력을 꾸준히 유지하는 것이 중요합니다.
데이터 플라이휠을 구동하기 위한 NVIDIA NeMo 마이크로서비스 사용
NVIDIA NeMo 마이크로서비스는 데이터 플라이휠을 구축할 수 있는 엔드 투 엔드 플랫폼을 제공해, 기업이 최신 정보를 바탕으로 AI 에이전트를 지속적으로 최적화할 수 있도록 지원합니다.
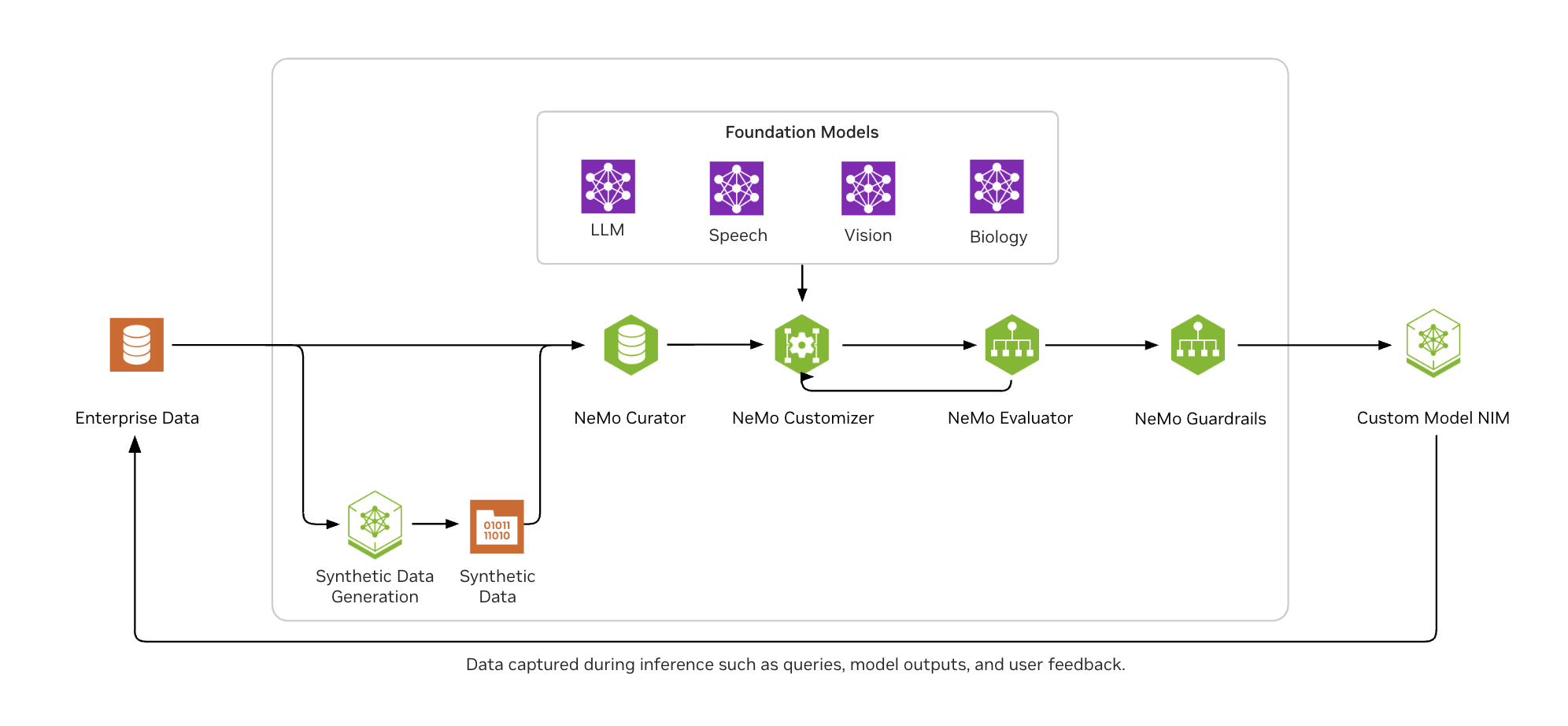
그림 2에서 볼 수 있듯, NVIDIA NeMo는 기업용 AI 개발자가 대규모 데이터를 손쉽게 선별하고, 일반적인 fine-tuning 기법을 활용해 LLM을 효과적으로 커스터마이징할 수 있도록 지원합니다. 또한 산업 표준과 자체 기준에 따라 성능을 지속적으로 평가하고, 신뢰할 수 있으며 적절한 출력을 보장하기 위한 가드레일 설정에도 도움을 줍니다.
NeMo 마이크로서비스를 활용해 에이전트의 툴 호출 기능을 강화하는 샘플 코드
NeMo 마이크로서비스 기반의 엔드 투 엔드 파이프라인을 설명하기 위해, 에이전트에서의 툴 호출 기능을 예로 들어보겠습니다. 툴 호출은 LLM이 외부 시스템과 상호작용하고, 프로그램을 실행하며, 학습 데이터에는 포함되지 않은 실시간 정보에 접근할 수 있도록 합니다.

효율적인 툴 호출을 위해서는, LLM이 사용 가능한 여러 도구 중에서 적절한 도구를 선택하고, 자연어 질의에서 필요한 파라미터를 정확히 추출하며, 필요에 따라 여러 동작을 순차적으로 연결하거나 동시에 여러 도구를 호출할 수 있어야 합니다. 툴의 수와 복잡도가 증가할수록, 정확성과 효율성을 유지하기 위한 커스터마이징의 중요성도 커집니다.
예를 들어, Llama 3.2 1B Instruct 모델을 약 60,000개의 툴 호출 예제를 포함한 xLAM 데이터셋으로 fine-tuning하면, Llama 3.1 70B Instruct 모델에 근접한 툴 호출 정확도를 달성할 수 있습니다. 이로써 모델 크기를 약 70배 줄이면서도 성능을 유지할 수 있습니다.
다음은 전체 작업 흐름을 간략히 설명한 단계입니다. 자세한 튜토리얼은 Jupyter 노트북에서 확인할 수 있습니다.
1단계: NVIDIA NeMo 마이크로서비스 배포
NeMo 마이크로서비스 플랫폼은 Helm 차트 형태로 제공되며, 사용자가 선택한 쿠버네티스 기반 시스템에 배포할 수 있습니다. 시작하려면, 단일 노드 NVIDIA GPU 클러스터(예: NVIDIA A100 80GB 또는 H100 80GB GPU 최소 2개 탑재)에서 minikube를 사용할 수 있습니다.
2단계: 데이터 준비
xLAM 데이터셋은 NeMo Customizer(학습용)와 NeMo Evaluator(테스트용)에서 사용할 수 있도록 변환됩니다. 각 데이터 샘플은 JSON 형식으로 구성되며, 사용자 질의, 사용 가능한 툴 목록(설명과 파라미터 포함), 정답 응답(선택된 툴 및 파라미터)으로 이루어져 있습니다. 또한, 학습, 검증, 테스트용 데이터로 분할됩니다.
NeMo Customizer에서 사용하는 데이터 포맷은 다음과 같습니다. messages에는 사용자 질의와 어시스턴트의 정답 응답이 포함되고, tools에는 선택 가능한 툴 목록이 포함됩니다.
{
"messages": [
{
"role": "user",
"content": "Where can I find live giveaways for beta access?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_beta",
"type": "function",
"function": {
"name": "live_giveaways_by_type",
"arguments": {"type": "beta"}
}
},
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "live_giveaways_by_type",
"description": "Retrieve live giveaways from the GamerPower API based on the specified type.",
"parameters": {
"type": "object",
"properties": {
"type": {
"type": "string",
"description": "The type of giveaways to retrieve (e.g., game, loot, beta).",
"default": "game"
}
},
"required": []
}
}
}
]
}NeMo Evaluator는 위에서 설명한 포맷과 거의 동일한 형식을 따르며, 약간의 차이만 있습니다. 자세한 내용은 Jupyter 노트북에서 확인할 수 있습니다.
3단계: 엔터티 관리
NVIDIA NeMo Entity Store 마이크로서비스는 네임스페이스, 프로젝트, 데이터셋, 모델과 같은 조직 내 엔터티를 계층적으로 관리할 수 있도록 지원합니다. 이를 통해 효율적인 리소스 관리와 사용자 간 리소스 충돌 방지, 원활한 협업이 가능해집니다. 반면, NVIDIA NeMo Datastore 마이크로서비스는 이들 엔터티와 연관된 실제 파일들을 관리하며, 업로드, 다운로드, 버전 관리 등의 작업을 지원합니다.
이 단계에서는 앞서 준비한 데이터셋을 Hugging Face Hub 인터페이스(HfApi)와 연동된 NeMo Datastore에 업로드하고, REST API를 통해 Entity Store와 Datastore 양쪽에 등록합니다. 이후 NeMo Customizer와 Evaluator는 이 경로를 참고해 입력 데이터를 가져옵니다.
4단계: LoRA fine-tuning
Llama 3.2 1B Instruct 모델에 대해 LoRA 방식으로 fine-tuning을 진행할 때는 NeMo Customizer를 사용합니다. 커스터마이징 작업 시작 및 작업 상태 모니터링 또한 NeMo Customizer 엔드포인트로의 REST API 호출을 통해 이뤄집니다. 학습 파라미터는 일반적인 딥러닝 학습 작업처럼 자유롭게 설정할 수 있으며, NeMo Customizer는 Weights & Biases와도 자연스럽게 통합되어 학습 과정을 실시간으로 모니터링할 수 있습니다.
headers = {"wandb-api-key": WANDB_API_KEY} if WANDB_API_KEY else None
training_params = {
"name": "llama-3.2-1b-xlam-ft",
"output_model": f"{NAMESPACE}/llama-3.1-8b-xlam-run1",
"config": BASE_MODEL,
"dataset": {"name": DATASET_NAME, "namespace" : NAMESPACE},
"hyperparameters": {
"training_type": "sft",
"finetuning_type": "lora",
"epochs": 2,
"batch_size": 16,
"learning_rate": 0.0001,
"lora": {
"adapter_dim": 32,
"adapter_dropout": 0.1
}
}
}
# Trigger the job.
resp = requests.post(f"{NEMO_URL}/v1/customization/jobs", json=training_params, headers=headers)
customization = resp.json()
# Used to track status
JOB_ID = customization["id"]
# This will be the name of the model that will be used to send inference queries to
CUSTOMIZED_MODEL = customization["output_model"]
5단계: 추론(Inference)
모델 학습이 완료되면, 해당 모델의 LoRA 어댑터는 NeMo Entity Store에 저장되며, NVIDIA NIM에서 이를 자동으로 불러옵니다. 이후 NIM 엔드포인트에 프롬프트를 전송하면, 학습된 모델을 이용해 즉시 추론 테스트를 수행할 수 있습니다.
inference_client = OpenAI(
base_url = f"{NIM_URL}/v1",
api_key = "None"
)
completion = inference_client.chat.completions.create(
model = CUSTOMIZED_MODEL,
messages = test_sample["messages"],
tools = test_sample["tools"],
tool_choice = 'auto',
temperature = 0.1,
top_p = 0.7,
max_tokens = 512,
stream = False
)
print(completion.choices[0].message.tool_calls)
이렇게 하면 도구의 이름과 매개변수 채우기가 포함된 출력이 생성됩니다:
[ChatCompletionMessageToolCall(id='chatcmpl-tool-bd3e4ee65e0641b7ae2285a9f82c7aae',
function=Function(arguments='{"type": "beta"}', name=’live_giveaways_by_type’), type='function')]
At
이 시점에서 모델은 툴 호출 정확도를 정량적으로 평가할 준비가 된 상태입니다.
6단계: 평가(Evaluation)
fine-tuning된 모델은 NeMo Evaluator를 사용해 평가되며, 기준(base) 모델과의 정확도를 비교해 툴 호출 성능의 향상을 측정합니다.function_name_accuracy와 function_name_and_args_accuracy 같은 지표는 툴 호출 능력의 향상 정도를 보여주며, 각각 함수 이름 및 인자까지 포함한 문자열 일치 정확도를 의미합니다.
평가는 일반적으로 다음과 같은 단계로 구성됩니다:
1. 평가 구성 생성: NeMo Evaluator에 어떤 데이터셋을 사용할지, 테스트 샘플 수, 적용할 평가 지표 등 원하는 평가 방식에 대한 세부 정보를 지정합니다. 이 구성 파일을 기반으로 평가가 자동으로 실행됩니다.
simple_tool_calling_eval_config = {
"type": "custom",
"tasks": {
"custom-tool-calling": {
"type": "chat-completion",
"dataset": {
"files_url": f"hf://datasets/{NAMESPACE}/{DATASET_NAME}/testing/xlam-test.jsonl",
"limit": 50
},
"params": {
"template": {
"messages": "{{ item.messages | tojson}}",
"tools": "{{ item.tools | tojson }}",
"tool_choice": "auto"
}
},
"metrics": {
"tool-calling-accuracy": {
"type": "tool-calling",
"params": {"tool_calls_ground_truth": "{{ item.tool_calls | tojson }}"}
}
}
}
}
}
2. 평가 작업 트리거하기: 여기에는 평가할 사용자 지정 모델(NIM)과 함께 평가 구성을 지정하는 것이 포함됩니다.
res = requests.post(
f"{NEMO_URL}/v1/evaluation/jobs",
json={
"config": simple_tool_calling_eval_config,
"target": {"type": "model", "model": CUSTOM_MODEL_NAME}
}
)
base_eval_job_id = res.json()["id"]
3. 평가 지표 검토: 평가 작업이 완료되면 메트릭을 검토하는 것도 REST 호출입니다.
res = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{base_eval_job_id}/results")
ft_function_name_accuracy_score = res.json()["tasks"]["custom-tool-calling"]["metrics"]["tool-calling-accuracy"]["scores"]["function_name_accuracy"]["value"]
ft_function_name_and_args_accuracy = res.json()["tasks"]["custom-tool-calling"]["metrics"]["tool-calling-accuracy"]["scores"]["function_name_and_args_accuracy"]["value"]
제공된 데모 노트북을 따라 진행하면, 기준 모델인 meta/llama-3.2-1B-instruct에 비해 툴 호출 성능이 크게 향상되는 것을 확인할 수 있습니다. 예상되는 성능 향상은 대략 다음과 같습니다:
function_name_accuracy: 12% → 92%function_name_and_args_accuracy: 8% → 72%
이는 무려 70배 더 큰 모델인 meta/llama-3.1-70B-instruct가 해당 작업에서 보여주는 정확도에 근접한 수준으로, 소형 모델로도 고성능을 낼 수 있음을 보여줍니다.
7단계: 가드레일 설정 (Guardrailing)
파이프라인의 마지막 단계는, 사용자 정의 모델의 NIM에 가드레일을 적용하는 것입니다. 이 예시에서는 nvidia/llama-3_1-nemoguard-8b-content-safety 모델을 사용해 콘텐츠 안전성을 확보합니다. 이 모델은 인간과 LLM 간의 상호작용 내용을 모니터링하며, 사용자 프롬프트와 LLM 응답이 안전한지 여부를 분류합니다. 콘텐츠가 안전하지 않은 경우에는 위반한 카테고리 목록을 포함한 응답도 함께 반환합니다.
이 과정은 평가 단계와 유사하게 다음 절차로 구성됩니다:
1. 가드레일 구성 생성 및 등록: 감지해야 할 위험 카테고리 목록과, 모델이 응답 시 따라야 할 포맷을 정의해 구성 파일을 만들고, 이를 시스템에 등록합니다.
data = {
"name": "toolcalling",
"namespace": "default",
"data": {
"models": [
{
"type": "content_safety",
"engine": "nim",
"model": "nvidia/llama-3.1-nemoguard-8b-content-safety"
}
],
"rails": {
"input": {
"flows": [
"content safety check input $model=content_safety"
]
},
"dialog": {
"single_call": {
"enabled": False
}
}
},
"prompts": [
{
"task": "content_safety_check_input $model=content_safety",
"messages": [
{
"type": "system",
"content": "Task: Check if there is unsafe content in the user or agent messages in the below conversation in accordance with our
safety policy with the below categories. Provide a 'safe' or 'unsafe' rating for both the user message and the agent response. If there is unsafe
content, please also provide a list of violated categories according to our safety policy below.\n\n<BEGIN UNSAFE CONTENT
CATEGORIES>\nS1: Violence.\nS2: Sexual.\nS3: Criminal Planning/Confessions.\nS4: Guns and Illegal Weapons.\nS5: Controlled/Regulated
Substances.\nS6: Suicide and Self Harm.\nS7: Sexual (minor).\nS8: Hate/Identity Hate.\nS9: PII/Privacy.\nS10: Harassment.\nS11: Threat.\nS12:
Profanity.\nS13: Needs Caution.\nS14: Other.\nS15: Manipulation.\nS16: Fraud/Deception.\nS17: Malware.\nS18: High Risk Gov Decision
Making.\nS19: Political/Misinformation/Conspiracy.\nS20: Copyright/Trademark/Plagiarism.\nS21: Unauthorized Advice.\nS22: Illegal
Activity.\nS23: Immoral/Unethical.\nS24: Deleting Logs.\n<END UNSAFE CONTENT CATEGORIES>\n\n<BEGIN CONVERSATION>\nuser:
{{user_query}}\n<END CONVERSATION>\n\nProvide your safety assessment for the above conversation in the below output JSON
format:\n{\"User Safety\": safe or unsafe rating for the user message, \"Response Safety\": safe or unsafe rating for the agent response.
Omit if no agent response present. \"Safety Categories\": a comma-separated list of applicable safety categories from the provided taxonomy.
Omit if all safe.}\n\nDo not include anything other than the output JSON in your response.\nOutput JSON:"
},
{
"type": "user",
"content": "{{ user_input }}"
}
],
"output_parser": "nemoguard_parse_prompt_safety",
"max_tokens": 50
}
]
},
}
# Register the guardrails configuration
response = requests.post(GUARDRAILS_URL, json=data)
2. LLM NIM 추론 호출 전에 사용자 입력에 가드레일 추가하기
payload = {
"model": BASE_MODEL,
"messages": [
{
"role": "user",
"content": user_message
}
],
"guardrails": {
"config_id": "toolcalling"
},
"temperature": 0.2,
"top_p": 1
}
# Check for unsafe user message in guardrails
response = requests.post(f"{NEMO_URL}/v1/guardrail/checks", json=payload)
status = response.json()
if status == “success”:
# SAFE
… (Proceed with your LLM inference call as in step 5)
else:
# UNSAFE
print(f"Not a safe input, the guardrails have resulted in status as {status}. Tool-calling shall not happen")
시작하기
이 글에서 소개한 단계들을 따라 하면, NeMo 마이크로서비스를 활용해 모델 커스터마이징, 추론, 평가, 그리고 가드레일 적용까지 포함된 엔드 투 엔드 파이프라인을 구축할 수 있습니다. 이 파이프라인을 자동화하여 주기적으로 또는 모델 드리프트가 감지될 때마다 새로운 데이터를 처리하도록 구성하면, 데이터 플라이휠이 형성됩니다. 이 자기 강화 루프는 시스템이 지속적으로 학습하고 적응하며 발전할 수 있도록 하여, 장기적인 성능 향상을 이끌어냅니다.
현재 NVIDIA NeMo 마이크로서비스는 일반 다운로드가 가능하며, 예시에 사용된 튜토리얼 노트북과 관련 영상도 함께 제공됩니다. 이를 활용해 직접 실습을 시작해보세요.
NeMo 마이크로서비스에 대해 더 자세히 알고 싶다면 공식 문서를 참고하시고, 실제 운영 환경에서 사용하려면 NVIDIA AI Enterprise 90일 무료 라이선스를 신청해보세요.