CUDA 그래프는 대규모 사용자 작업을 단일 작업으로 실행할 수 있는 작업 그래프로 정의함으로써 작업 실행의 오버헤드를 크게 줄입니다. 워크플로우를 미리 파악하면 CUDA 드라이버에서 다양한 최적화를 적용할 수 있으며, 이는 스트림 모델로는 불가능한 작업입니다.
그러나 성능에는 유연성 희생이라는 대가가 따릅니다. 전체 워크플로우를 미리 파악할 수 없는 경우, 결정을 내리려면 GPU 실행을 중단하고 CPU로 돌아가야 합니다.
CUDA 디바이스 그래프 실행 기능은 런타임에 결정된 데이터를 기반으로 태스크 그래프가 성능 기준에 맞게 실행되도록 함으로써 이러한 문제를 해결합니다. CUDA 디바이스 그래프 실행은 두 가지 서로 다른 실행 모드를 제공합니다. 실행 후 무시와 후속 실행입니다. 이를 통해 다양한 애플리케이션을 활성화하고 다양한 분야에 적용할 수 있습니다.
이 게시물에서는 디바이스 그래프 실행 기능과 두 실행 모드를 사용하는 방법을 소개하겠습니다. 데이터 처리를 위해 파일을 압축 해제하는 디바이스 측 작업 스케줄러의 예시도 보여 드리겠습니다.
디바이스 그래프 초기화
작업 그래프를 실행하려면 아래에 설명된 4단계를 따릅니다.
- 그래프 생성
- 그래프를 실행 가능한 그래프로 구체화
- 실행 가능한 그래프의 작업 설명을 GPU에 업로드
- 실행 가능 그래프 실행
CUDA는 시작 단계를 다른 단계에서 분리하여 워크플로우를 최적화하고 가능한 한 가볍게 그래프를 실행할 수 있습니다. 편의를 위해, CUDA는 업로드 단계가 명시적으로 호출되지 않은 경우 그래프가 실행될 때 업로드 단계와 시작 단계도 결합합니다.
CUDA 커널에서 그래프를 실행하기 위해서는 구체화 단계 동안 디바이스 시작에 앞서 그래프가 초기화되어야 합니다. 또한 디바이스에서 실행되기 위해서는, 수동 업로드 단계를 통해 수동으로 업로드하든, 호스트 실행을 통해 묵시적으로 업로드하든 디바이스 그래프가 디바이스에 업로드되어야 합니다. 디바이스 스케줄러 예시를 설정하기 위해 호스트 측 단계를 수행하는 아래 코드에서는 두 방법을 모두 볼 수 있습니다.
// This is the signature of our scheduler kernel // The internals of this kernel will be outlined later __global__ void schedulerKernel( fileData *files, int numFiles, int *currentFile, void **currentFileData, cudaGraphExec_t zipGraph, cudaGraphExec_t lzwGraph, cudaGraphExec_t deflateGraph); void setupAndLaunchScheduler() { cudaGraph_t zipGraph, lzwGraph, deflateGraph, schedulerGraph; cudaGraphExec_t zipExec, lzwExec, deflateExec, schedulerExec; // Create the source graphs for each possible operation we want to perform // We pass the currentFileData ptr to this setup, as this ptr is how the scheduler will // indicate which file to decompress create_zip_graph(&zipGraph, currentFileData); create_lzw_graph(&lzwGraph, currentFileData); create_deflate_graph(&deflateGraph, currentFileData); // Instantiate the graphs for these operations and explicitly upload cudaGraphInstantiate(&zipExec, zipGraph, cudaGraphInstantiateFlagDeviceLaunch); cudaGraphUpload(zipExec, stream); cudaGraphInstantiate(&lzwExec, lzwGraph, cudaGraphInstantiateFlagDeviceLaunch); cudaGraphUpload(lzwExec, stream); cudaGraphInstantiate(&deflateExec, deflateGraph, cudaGraphInstantiateFlagDeviceLaunch); cudaGraphUpload(deflateExec, stream); // Create and instantiate the scheduler graph cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal); schedulerKernel<<<1, 1, 0, stream>>>(files, numFiles, currentFile, currentFileData, zipExec, lzwExec, deflateExec); cudaStreamEndCapture(stream, &schedulerGraph); cudaGraphInstantiate(&schedulerExec, schedulerGraph, cudaGraphInstantiateFlagDeviceLaunch); // Launch the scheduler graph - this will perform an implicit upload cudaGraphLaunch(schedulerExec, stream); }
디바이스 그래프가 호스트나 디바이스에서 모두 실행될 수 있다는 점에 유의하세요. 즉, 동일한 cudaGraphExec_t 핸들이 디바이스 실행과 호스트 실행 양쪽에 대한 스케줄러로 전달될 수 있다는 것입니다.
파이어와 포겟 런치(Fire and forget launch)
스케줄러 커널은 수신하는 데이터에 따라 작업을 배포합니다. 작업 배포에 권장되는 실행 방법은 파이어와 포겟 런치(Fire and forget launch)입니다.
실행 후 포겟(Forget)를 통해 그래프가 실행되면 즉시 배포됩니다. 실행 후 포겟 모드(Forget mode)를 통해 실행된 그래프와 후속 그래프는 독립적으로 실행됩니다. 작업이 즉시 실행되므로, 스케줄러 배포 작업에 대해서는 실행 후 무시가 권장됩니다. 최대한 빠르게 실행되기 때문입니다. CUDA는 그래프 실행 후 무시를 수행하기 위해 디바이스 측에서 명명된 새로운 스트림을 도입합니다. 간단한 디스패처 예시를 아래에서 확인하세요.
enum compressionType { zip = 1, lzw = 2, deflate = 3 }; struct fileData { compressionType comprType; void *data; }; __global__ void schedulerKernel( fileData *files, int numFiles int *currentFile, void **currentFileData, cudaGraphExec_t zipGraph, cudaGraphExec_t lzwGraph, cudaGraphExec_t deflateGraph) { // Set the data ptr to the current file so the dispatched graph // is operating on the correct file data *currentFileData = files[currentFile].data; switch (files[currentFile].comprType) { case zip: cudaGraphLaunch(zipGraph, cudaStreamGraphFireAndForget); break; case lzw: cudaGraphLaunch(lzwGraph, cudaStreamGraphFireAndForget); break; case deflate: cudaGraphLaunch(deflateGraph, cudaStreamGraphFireAndForget); break; default: break; } }
그래프 실행은 중첩되고 반복될 수 있기 때문에, 실행 후 무시의 경우 추가적인 디바이스 그래프가 배포될 수 있다는 점에 유의하세요. 이 예시에는 표시되지 않았지만, 파일 데이터를 압축 해제하는 그래프의 경우, 데이터 압축이 완전히 풀리면 해당 데이터에 대해 추가적인 처리(이미지 처리 등)를 할 수 있도록 더 많은 그래프를 배포할 수 있습니다. 디바이스 그래프 흐름은 그래프와 마찬가지로 계층 구조입니다.
후속 실행
CUDA 작업은 GPU에 대해 비동기적으로 실행됩니다. 즉, 실행 스레드가 결과나 출력을 소모하기 전에 작업이 완료되기를 명시적으로 기다려야 한다는 뜻입니다. 이 작업은 일반적으로 cudaDeviceSynchronize 또는 cudaStreamSynchronize 등의 동기화 작업을 사용하여 CPU 스레드에서 수행됩니다.
GPU 실행 스레드에서는 cudaDeviceSynchronize와 같은 기존 방법을 통해 실행되는 디바이스 그래프에서 동기화할 수 없습니다. 작업 순서 지정이 필요한 상황이라면 대신 후속 실행을 사용해야 합니다.
후속 실행을 위해 그래프가 제출되면 바로 실행되지 않고 실행 그래프가 완료되면 실행됩니다. CUDA는 상위 그래프의 일부로 동적 생성된 모든 작업을 캡슐화하므로, 후속 실행은 생성된 모든 실행 후 무시 작업이 완료되어야만 실행됩니다.
후속 실행이 실행 후 무시 작업보다 이전에, 또는 이후에 실시되었는지와는 무관합니다. 후속 실행은 대기열에 지정된 순서대로 실행됩니다. 특수한 사례는 자체 재실행인데, 현재 실행 중인 디바이스 그래프가 후속 실행을 통해 재실행되는 경우를 말합니다. 한 번에 하나의 자체 재실행만 보류 상태로 허용됩니다.
후속 실행 모드를 사용하면 이전 디스패처를 업그레이드해 완전 스케줄러 커널로 만들 수 있습니다. 이 경우 스케줄러는 반복적으로 자체 재실행되며 실행 흐름에 효과적으로 루프를 생성합니다.
__global__ void schedulerKernel( fileData *files, int numFiles, int *currentFile, void **currentFileData, cudaGraphExec_t zipGraph, cudaGraphExec_t lzwGraph, cudaGraphExec_t deflateGraph) { // Set the data ptr to the current file so the dispatched graph // is operating on the correct file data *currentFileData = files[currentFile].data; switch (files[currentFile].comprType) { case zip: cudaGraphLaunch(zipGraph, cudaStreamGraphFireAndForget); break; case lzw: cudaGraphLaunch(lzwGraph, cudaStreamGraphFireAndForget); break; case deflate: cudaGraphLaunch(deflateGraph, cudaStreamGraphFireAndForget); break; default: break; } // If we have not finished iterating over all the files, relaunch if (*currentFile < numFiles) { // Query the current graph handle so we can relaunch it cudaGraphExec_t currentGraph = cudaGetCurrentGraphExec(); cudaGraphLaunch(currentGraph, cudaStreamGraphTailLaunch); *currentFile++; } }
재실행 작업이 cudaGetCurrentGraphExec을 사용하여 현재 실행 중인 그래프에 대한 핸들을 검색하는 것에 주목하세요. 실행 가능 그래프 핸들 없이도 자체 재실행이 가능합니다.
자체 재실행을 위해 후속 실행 모드를 사용하면 추가적인 효과가 있습니다. 다음 스케줄러 커널 재실행이 시작되기 전, 배포된 실행 후 무시 작업과 동기화(또는 대기)하는 것이죠. 디바이스 그래프는 한 번에 하나의 실행(및 하나의 자체 재실행)만 보류 상태로 둘 수 있습니다. 방금 배포된 그래프를 재실행하려면 이전 실행이 완료되었는지 먼저 확인해야 합니다. 이는 자체 재실행 작업을 수행함으로써 가능하고, 이후 다음 반복에 필요한 그래프를 배포할 수 있습니다.
디바이스와 호스트 실행 성능 비교
이 예제를 호스트 실행 그래프에 비교하면 어떨까요? 그림 1은 다양한 토폴로지에서 실행 후 무시, 후속 실행, 호스트 실행의 지연 시간을 비교한 결과입니다.
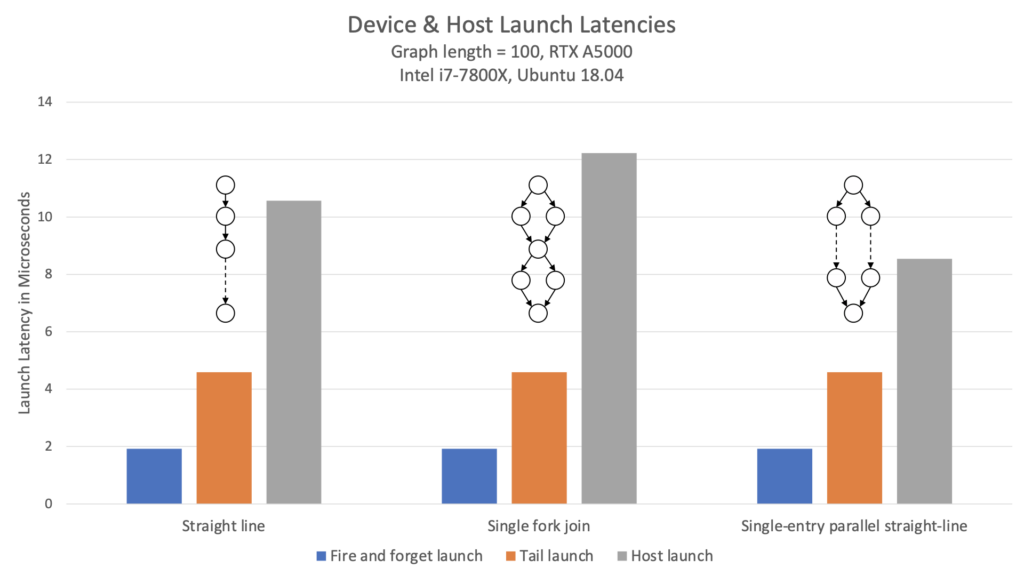
이 차트는 디바이스 측 실행 지연 시간이 호스트 실행의 지연 시간 대비 2배 더 낮을 뿐만 아니라, 그래프 구조의 영향을 받지 않음을 보여줍니다. 각 토폴로지에 대해 지연 시간은 동일합니다.
또한, 그림 2에서 볼 수 있듯이 디바이스 실행의 경우 그래프 폭 확장성도 더 뛰어납니다.
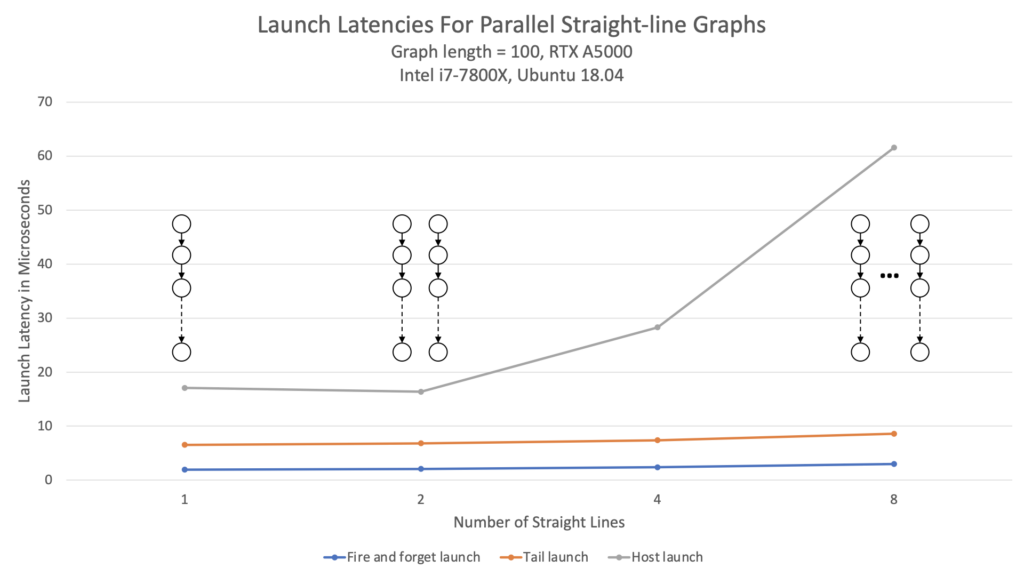
호스트 실행과 비교하면 디바이스 실행 지연 시간은 그래프에 얼마나 많은 병렬 처리가 있는지와는 관계 없이 거의 일정하게 유지됩니다.
결론
CUDA 디바이스 그래프 실행은 CUDA 커널 내에서 동적 제어 흐름을 실현하는 높은 성능의 방법을 제공합니다. 이 게시물에서 해당 기능 사용 시작 방법을 보여 드리기는 했지만, 전체 사용 방법에 비하면 일부일 뿐입니다.
추가 설명은 프로그래밍 가이드의 디바이스 그래프 실행 섹션을 참조하세요. 디바이스 그래프 실행을 직접 해보려면 CUDA Toolkit 12.0을 다운로드하세요.