
NVIDIA의 목표는 우리 시대의 다빈치와 아인슈타인 같은 천재들의 연구를 가속화하고 그로 하여금 사회의 주요 과제를 해결하도록 지원하는 것입니다. 인공 지능(AI), 고성능 컴퓨팅(HPC), 데이터 분석의 복잡성이 기하급수적으로 증가함에 따라 과학자들이 어려운 과제를 해결하려면 10년 내에 백만 배의 속도 향상을 이끌어낼 수 있는 최첨단 컴퓨팅 플랫폼이 필요합니다.
이러한 요구 사항에 부합하는 NVIDIA Hopper 아키텍처 기반의 핵심 GPU 서버 구성 요소, NVIDIA HGX H100을 소개합니다. 이 최첨단 고성능 플랫폼은 지연 시간이 짧고 안전하며, 네트워킹에서 새로운 컴퓨팅 단위인 데이터센터 규모 컴퓨팅에 이르는 전체 기능 스택을 통합합니다.
이 게시물에서는 당사 가속 컴퓨팅 데이터센터 플랫폼이 NVIDIA HGX H100을 통해 한 단계 더 도약하는 방법에 관해 다루겠습니다.
HGX H100 8-GPU
HGX H100 8-GPU는 새로운 Hopper 세대 GPU 서버의 핵심 구성 요소로H100 Tensor 코어 GPU 8대와 3세대 NVSwitch 4개를 호스팅합니다. H100 GPU마다 여러 개의 4세대 NVLink 포트가 있으며 4개의 NVSwitch에 모두 연결됩니다. 각 NVSwitch는 H100 Tensor 코어 GPU 8대를 모두 완벽하게 연결하는 완전 비차단 스위치입니다.
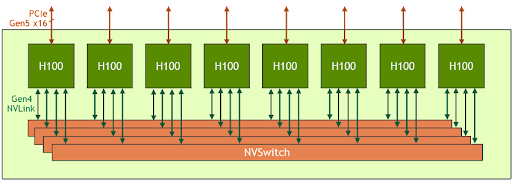
이처럼 NVSwitch 완전 연결 토폴로지를 구성하여 모든 H100 GPU는 다른 H100 GPU와 동시에 소통할 수 있습니다.특히 이 통신은 초당 900기가바이트(GB/s)의 NVLink 양방향 속도로 실행되며, 이는 현재 PCIe Gen4 x16 버스의 대역폭보다 14배 이상 빠른 속도입니다.
또한 3세대 NVSwitch는 멀티캐스트 및 NVIDIA SHARP 네트워크 내 감소를 사용하여 집합 연산을 위한 새로운 하드웨어 가속화도 제공합니다. 더 빨라진 NVLink 속도와 결합하면 모두 감소(all-reduce)와 같은 일반적인 AI 집합 연산에 대한 효과적인 대역폭은 HGX A100과 비교하여 최대 3배 증가합니다. 집합체의 NVSwitch 가속화로 GPU의 부하도 크게 줄어듭니다.
| HGX A100 8-GPU | HGX H100 8-GPU | Improvement Ratio | |
| FP8 | – | 32,000 TFLOPS | 6X (vs A100 FP16) |
| FP16 | 4,992 TFLOPS | 16,000 TFLOPS | 3X |
| FP64 | 156 TFLOPS | 480 TFLOPS | 3X |
| In-Network Compute | 0 | 3.6 TFLOPS | Infinite |
| Interface to host CPU | 8x PCIe Gen4 x16 | 8x PCIe Gen5 x16 | 2X |
| Bisection Bandwidth | 2.4 TB/s | 3.6 TB/s | 1.5X |
*참고: FP 성능에 희소성이 포함됨
NVLink-네트워크 지원이 포함된 HGX H100 8-GPU
정확한 대화형 AI와 같은 작업을 위해 최근 떠오르고 있는 엑사스케일 HPC 및 조 단위 매개 변수의 AI 모델은 슈퍼컴퓨터에서도 트레이닝하는 데 몇 개월이 걸립니다. 이를 비즈니스 속도로 단축하고 몇 시간 이내에 교육을 완료하려면 서버 클러스터의 모든 GPU 간에 빠르고 원활하게 통신해야 합니다.
이러한 대규모 사용 사례를 해결하기 위해 새로운 NVLink 및 NVSwitch는 HGX H100 8-GPU가 새로운 NVLink 네트워크를 통해 NVLink 영역을 훨씬 더 크게 확장 및 지원할 수 있도록 설계되었습니다. HGX H100 8-GPU의 또 다른 버전은 이 새로운 NVLink-네트워크 지원을 특징으로 합니다.
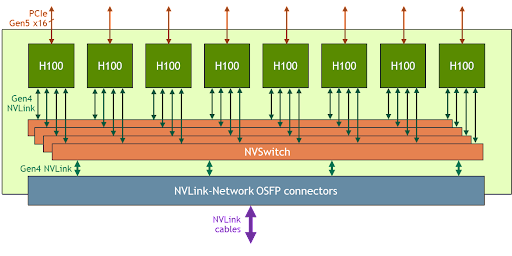
NVLink-네트워크 지원이 포함된 HGX H100 8-GPU로 구축된 시스템 노드는 Octal Small Form Factor Pluggable(OSFP) LinkX 케이블 및 새로운 외부 NVLink 스위치를 통해 다른 시스템에 완전히 연결될 수 있습니다. 이 연결을 통해 최대 256개의 GPU NVLink 도메인에 연결할 수 있습니다. 그림 3은 클러스터 토폴로지입니다.
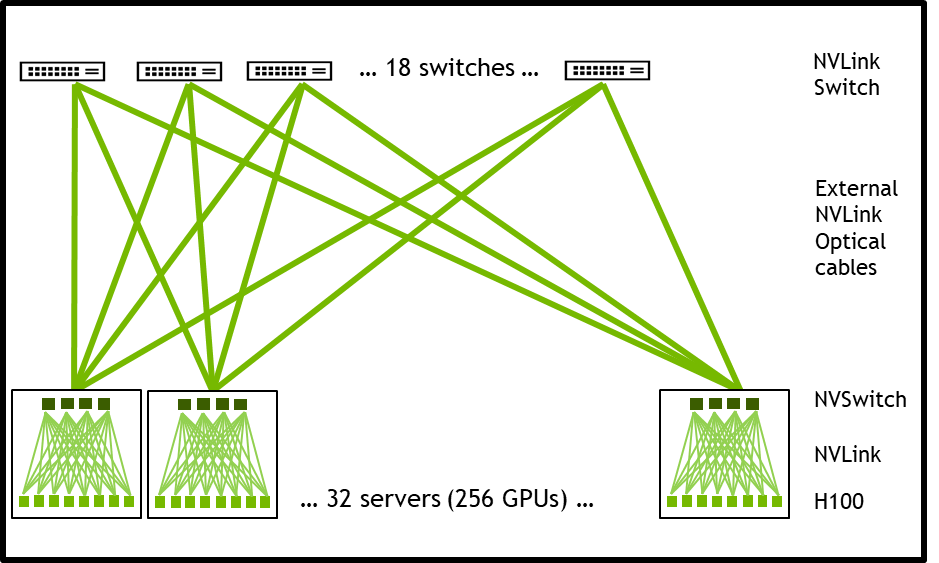
| 256 A100 GPU Pod | 256 H100 GPU Pod | Improvement Ratio | |
| NVLINK Domain | 8 GPU | 256 GPU | 32X |
| FP8 | – | 1,024 PFLOPS | 6X (vs A100 FP16) |
| FP16 | 160 PFLOPS | 512 PFLOPS | 3X |
| FP64 | 5 PFLOPS | 15 PFLOPS | 3X |
| In-Network Compute | 0 | 192 TFLOPS | Infinite |
| Bisection Bandwidth | 6.4 TB/s | 70 TB/s | 11X |
*참고: FP 성능에 희소성이 포함됨
타겟 사용 사례 및 성능에서의 이점
HGX H100 컴퓨팅 및 네트워킹 기능이 대폭 증가함에 따라 AI 및 HPC 애플리케이션 성능이 크게 향상되었습니다.
오늘날의 메인스트림 AI 및 HPC 모델은 단일 노드의 종합적 GPU 메모리 내에 완전히 상주할 수 있습니다. 예를 들어 BERT-Large, Mask R-CNN 및 HGX H100은 가장 성능 효율적인 트레이닝 솔루션입니다.
더욱 발전되고 규모가 큰 AI 및 HPC 모델의 경우, 그에 맞춰 집계 GPU 메모리의 노드가 여러 개 필요합니다. 예를 들어, 테라바이트 단위의 임베디드 테이블이 있는 DLRM(deep learning recommendation model), 대규모 MoE(mixture-of-experts) 자연어 처리 모델 및 NVLink 네트워크가 포함된 HGX H100은 핵심 통신 병목 현상을 가속화하며 이러한 워크로드 수준에 맞는 최고의 솔루션입니다.
NVIDIA H100 GPU 아키텍처 백서의 그림 4는 NVLink-네트워크를 통해 지원되는 추가적인 성능 향상을 나타냅니다.
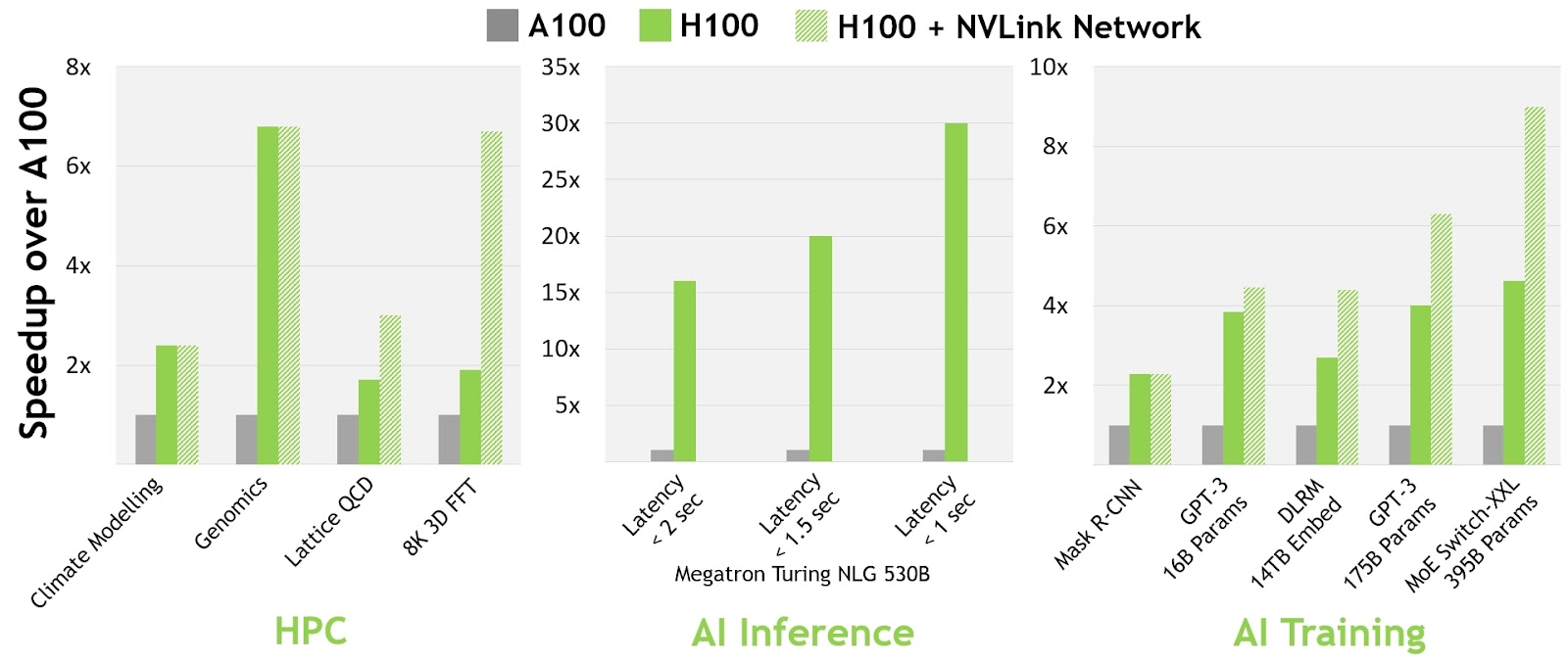
모든 성능 수치는 현재의 기대에 의거한 예비 수치이며 실제 배송 제품에서는 다를 수 있습니다. A100 클러스터: HDR IB 네트워크. H100 클러스터: 표시된 경우 NVLink-네트워크가 포함된 NDR IB 네트워크.
# GPU: 기후 모델링 1K, LQCD 1K, 유전체학 8, 3D-FFT 256, MT-NLG 32(배치 크기: A100의 경우 4, 1초에 H100의 경우 60, A100의 경우 8개, 1.5초 및 2초에 H100의 경우 64), MRCNN 8(배치 32), GPT-3 16B 512(배치 256), DLRM 128(배치 64K), GPT-3 16K(배치 512), MoE 8K(배치 512, GPU당 하나의 전문가)
HGX H100 4-GPU
HGX 제품군에는 8-GPU 버전 외에 4-GPU 버전도 있으며, 이는 4세대 NVLink와 직접 연결됩니다.
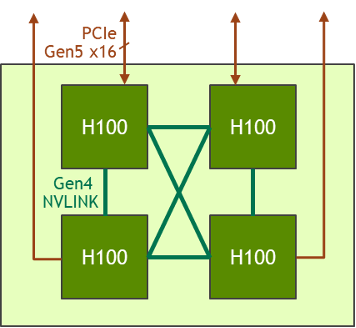
H100-H100 P2P(point-to-point) 피어 NVLink 대역폭은 양방향 300GB/s이며, 현재의 PCIe Gen4 x16 bus보다 약 5배 더 빠릅니다.
HGX H100 4-GPU 폼 팩터는 고밀도 HPC 배포에 최적화되어 있습니다.
• 랙당 GPU 밀도를 최대화하기 위해 HGX H100 4-GPU 여러 대를 1U 고성능 액체 냉각 시스템에 패킹할 수 있습니다.
• HGX H100 4-GPU를 포함한 완전한 PCIe 스위치리스 아키텍처는 CPU에 직접 연결되어 시스템 재료 비용을 낮추고 절전 효과를 얻을 수 있습니다.
• 좀 더 CPU 집약적인 워크로드의 경우 HGX H100 4-GPU를 두 개의 CPU 소켓에 연결하여 시스템 구성의 균형이 맞도록 CPU 대 GPU 비율을 늘릴 수 있습니다.
AI 및 HPC용 가속 서버 플랫폼
NVIDIA는 올해 말 HGX H100 기반 서버 플랫폼을 시장에 출시하고자 당사의 에코시스템과 긴밀히 협력하고 있습니다. 귀사가 이 강력한 컴퓨팅 도구를 활용하여 세계에서 가장 앞선 혁신 기업으로 자리 잡고 목표를 달성할 수 있기를 바랍니다.