
거대 언어 모델(LLM)은 AI 혁신의 최전선에 있지만, 그 방대한 크기 때문에 추론 효율성에 어려움을 주기도 합니다. Llama 3 70B와 Llama 4 Scout 109B 같은 모델은 특히 긴 컨텍스트 윈도우를 포함할 경우 GPU 메모리만으로는 감당하기 어려운 수준의 메모리를 요구합니다.
예를 들어, Llama 3 70B와 Llama 4 Scout 109B 모델을 반정밀도(FP16)로 로드할 경우 각각 약 140GB와 218GB의 메모리가 필요합니다. 여기에 추론 과정에서는 일반적으로 컨텍스트 길이와 배치 크기에 따라 증가하는 키-값(KV) 캐시 같은 추가 데이터 구조도 필요합니다. 예를 들어, 단일 사용자(batch size 1)에 대해 128k 토큰의 컨텍스트 윈도우를 처리하는 KV 캐시는 Llama 3 70B 기준으로 약 40GB의 메모리를 사용하며, 사용자가 늘어나면 이 용량도 선형적으로 증가합니다. 이러한 대형 모델을 GPU 메모리만으로 처리하려 할 경우, 실제 운영 환경에서는 메모리 부족(OOM) 오류가 발생할 수 있습니다.
NVIDIA Grace Blackwell 및 NVIDIA Grace Hopper 아키텍처에서는 CPU와 GPU가 NVIDIA NVLink-C2C로 연결되어 있습니다. 이는 초당 900GB의 대역폭을 제공하는 메모리 일관성(coherency) 기반 인터커넥트로, PCIe Gen 5 대비 7배의 대역폭을 자랑합니다. NVLink-C2C의 메모리 일관성 기능은 CPU와 GPU가 단일 통합 메모리 주소 공간을 공유하도록 해, 별도의 데이터 전송이나 중복 복사 없이 동일한 데이터를 함께 접근하고 처리할 수 있도록 합니다.
이러한 구조는 기존 GPU 메모리 용량을 초과하는 대규모 데이터셋과 모델도 보다 쉽게 접근하고 처리할 수 있게 해줍니다. Grace Hopper 및 Grace Blackwell에 적용된 NVLink-C2C 기반 고대역폭 연결과 통합 메모리 아키텍처는 LLM 파인튜닝, KV 캐시 오프로드, 추론, 과학 연산 등 다양한 워크로드에서 효율성을 높여주며, GPU 메모리가 부족할 경우 CPU 메모리를 활용해 데이터를 빠르게 이동시킬 수 있게 합니다.
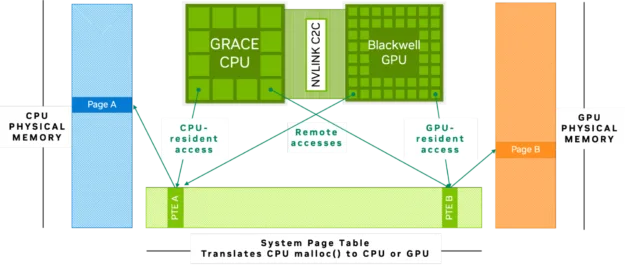
예를 들어, NVIDIA GH200 Grace Hopper Superchip처럼 통합 메모리 아키텍처를 갖춘 플랫폼에 모델을 로드하면, 96GB의 고대역폭 GPU 메모리와 함께 CPU에 연결된 480GB의 LPDDR 메모리를 명시적인 데이터 전송 없이도 활용할 수 있습니다. 이를 통해 사용 가능한 전체 메모리 용량이 대폭 확장되어, 기존에는 GPU 단독으로는 처리할 수 없었던 대규모 모델과 데이터셋도 다룰 수 있게 됩니다.
코드 예제와 설명
이 블로그에서는 Llama 3 70B 모델과 GH200 Superchip을 예시로 사용해, 통합 메모리를 활용하여 대형 모델을 GPU로 스트리밍하는 과정을 보여드리겠습니다. 위에서 설명한 개념들이 실제 코드에서는 어떻게 구현되는지 함께 살펴봅니다.
시작하기
먼저, 환경을 설정하고 Llama 3 70B 모델에 접근할 수 있어야 합니다. 아래의 코드 예제는 NVIDIA Grace Hopper GH200 Superchip 시스템에서 통합 메모리 아키텍처의 이점을 보여주기 위해 설계된 것이며, NVIDIA Grace Blackwell 기반 시스템에서도 동일한 방식으로 사용할 수 있습니다.
설정 과정은 다음과 같습니다:
1. Hugging Face에서 모델 접근 권한 요청하기: Hugging Face의 Llama 3 70B 모델 페이지를 방문해 접근 권한을 요청합니다.
2. Access Token 생성하기: 요청이 승인되면 Hugging Face 계정 설정에서 액세스 토큰을 생성합니다. 이 토큰은 코드에서 모델에 접근할 때 인증에 사용됩니다.
3. 필요한 패키지 설치하기: 모델을 사용하기 전, 필요한 Python 라이브러리를 설치해야 합니다. GH200 머신에서 Jupyter Notebook을 열고 다음 명령어를 실행합니다:
#Install huggingface and cuda packages
!pip install --upgrade huggingface_hub
!pip install transformers
!pip install nvidia-cuda-runtime-cu124. Hugging Face 로그인하기: 패키지 설치가 완료되면, 앞에서 생성한 토큰을 사용해 Hugging Face에 로그인합니다. huggingface_hub 라이브러리를 사용하면 간편하게 로그인할 수 있습니다.
#Login into huggingface using the generated token
from huggingface_hub import login
login("enter your token")Llama 3 70B 모델을 GH200에 로드하면 어떤 일이 발생할까?
Llama 3 70B 모델을 GPU 메모리에 로드하려고 시도하면, 모델의 파라미터(웨이트)가 GPU 메모리(NVIDIA CUDA 메모리)로 적재됩니다. 반정밀도(FP16) 기준으로 이 웨이트는 약 140GB의 GPU 메모리를 요구합니다. GH200은 96GB만 제공하기 때문에 모델 전체를 메모리에 담을 수 없고, 로드 과정은 OOM(Out-Of-Memory) 오류로 실패합니다. 다음 셀에서는 코드 예제로 이 동작을 보여줍니다.
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-70B") #loads the model into the GPU memory위 명령을 실행하면 다음과 같은 오류 메시지가 나타납니다.
Error message:
OutOfMemoryError: CUDA out of memory. Tried to allocate 896.00 MiB. GPU 0 has a total capacity of 95.00 GiB of which 524.06 MiB is free. Including non-PyTorch memory, this process has 86.45 GiB memory in use. Of the allocated memory 85.92 GiB is allocated by PyTorch, and 448.00 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management.오류 메시지에서 GPU 메모리가 최대치에 도달했음을 확인할 수 있습니다. 다음 명령을 실행해 GPU 메모리 상태를 직접 확인할 수도 있습니다.
!nvidia-smi명령을 실행하면 아래 이미지와 유사한 출력이 나타납니다. 출력에 따르면 GPU에서 97.871GB 중 96.746GB의 메모리를 사용 중입니다. 출력 해석 방법은 해당 포럼을 참고하세요.
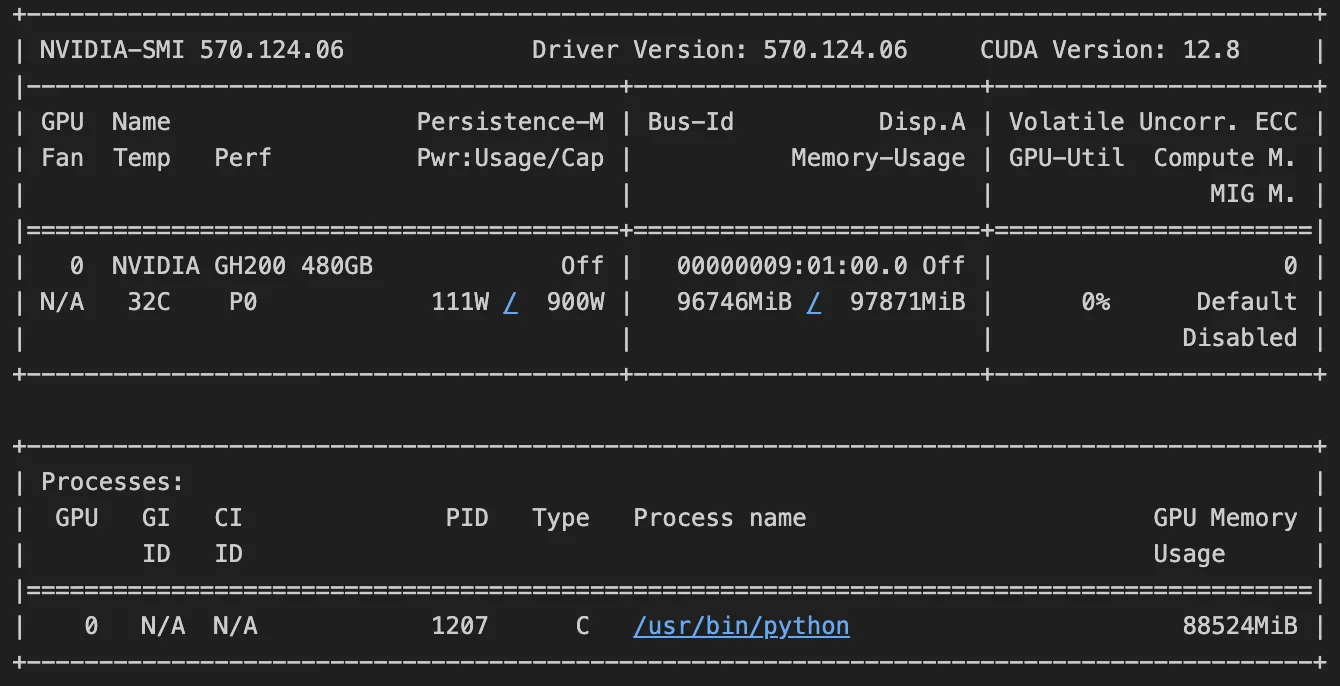
다음 단계를 준비하고 GPU 메모리를 해제하기 위해, 이번 실패 시도에서 남아 있는 변수를 정리하겠습니다. 아래 명령에서 <PID>는 Python 프로세스 ID로, !nvidia-smi 명령으로 확인할 수 있습니다.
!kill -9 <PID>이 OOM 오류는 어떻게 해결할 수 있을까?
해결 방법은 관리형 메모리(managed memory) 할당을 사용하는 것입니다. 이를 통해 GPU는 자체 메모리 외에 CPU 메모리에도 접근할 수 있습니다. GH200 시스템의 통합 메모리 아키텍처는 CPU(최대 480GB)와 GPU(최대 144GB)가 단일 주소 공간을 공유하고 서로의 메모리에 투명하게 접근하도록 합니다. RAPIDS Memory Manager(RMM) 라이브러리를 관리형 메모리를 사용하도록 구성하면, GPU와 CPU에서 모두 접근 가능한 메모리를 할당할 수 있어 수작업 데이터 전송 없이도 물리적 GPU 메모리 한계를 넘어 워크로드를 실행할 수 있습니다.
import rmm
import torch
from rmm.allocators.torch import rmm_torch_allocator
from transformers import pipeline
rmm.reinitialize(managed_memory=True) #enabling access to CPU memory
torch.cuda.memory.change_current_allocator(rmm_torch_allocator)
#instructs PyTorch to use RMM memory manager to use unified memory for all memory allocations
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-70B")
모델 로드 명령을 다시 실행하면, 더 큰 메모리 공간에 접근하게 되므로 OOM 메모리 오류가 발생하지 않습니다.
이제 명령을 사용해 LLM에 프롬프트를 보내고 응답을 받을 수 있습니다.
pipe("Which is the tallest mountain in the world?")결론
모델 규모가 계속 커지면서, 모델 파라미터를 GPU에 적재하는 일은 중요한 과제가 되었습니다. 이 블로그에서는 통합 메모리 아키텍처가 명시적 데이터 전송 없이 CPU와 GPU 메모리에 접근하도록 해 이러한 한계를 극복하고, 최신 하드웨어에서 최첨단 LLM을 훨씬 수월하게 다룰 수 있게 만드는 방법을 살펴봤습니다.
CPU와 GPU 메모리 관리 방법에 대해 더 알아보려면 RAPIDS Memory Manager 문서를 참고하세요.




