多くの本番稼働レベルの機械学習 (ML: Macine Learning) アプリケーションでは、推論は単一 ML モデル上でフォワード パスを実行することに限定されません。代わりに、ML モデルのパイプラインを実行する必要があることが多いです。例えば、対話型 AI パイプラインは、入力された音声波形をテキストに変換する自動音声認識 (ASR: Automatic Speech Recognition) モジュール、入力を理解して適切な応答を提供する大規模言語モデル (LLM: Large Language Model) モジュール、LLM の出力から音声を生成するテキスト読み上げ (TTS: text-to-speech) モジュールの 3 つから構成されています。
また、テキストから画像へ変換するアプリケーションでは、パイプラインは LLM と拡散モデルで構成され、それぞれ入力テキストのエンコードと、エンコードされたテキストからの画像合成に使用されます。さらに、多くのアプリケーションでは、ML モデルに入力する前に入力データに対して何らかの前処理を行ったり、モデルの出力に対して後処理を行ったりする必要があります。例えば、入力画像はコンピューター ビジョン モデルに送られる前にサイズ変更、トリミング、デコードされる必要があり、テキスト入力は LLM に送られる前にトークン化される必要があります。
近年、ML モデルのパラメーター数は急増しており、非常に大規模なユーザー ニーズへの対応が求められるようになったため、推論パイプラインの最適化がこれまで以上に重要となってきています。NVIDIA TensorRT や FasterTransformer のようなツールは、GPU 上で推論を行う際に、個々のディープラーニング モデルを低レイテンシかつ高スループットになるように最適化します。
しかし、私たちの包括的な目標は、個々の ML モデルに対する推論を高速化することではなく、推論パイプライン全体を高速化することです。例えば、GPU でモデルを提供する場合、CPU で前処理と後処理を行うと、モデル実行ステップが高速でも、パイプライン全体のパフォーマンスが低下します。推論パイプラインの最も効率的なソリューションは、前処理、モデル実行、後処理のすべてのステップを GPU 上で実行することです。この GPU によるエンドツーエンドの推論パイプラインの効率性は、以下の 2 つの重要な要素に起因しています。
- パイプラインのステップ間に、CPU (ホスト) と GPU (デバイス) の間でデータをコピーし直す必要がない。
- GPU の強力な演算能力が推論パイプライン全体に利用されている。
NVIDIA Triton Inference Server は、CPU と GPU の両方でモデルを大規模に展開および実行するためのオープン ソースの推論サービングを提供するソフトウェアです。数ある機能の中でも、NVIDIA Triton はアンサンブル モデルをサポートしており、Directed Acyclic Graph (DAG) の形でモデルのアンサンブルとして推論パイプラインを定義することが可能です。NVIDIA Triton は、パイプライン全体の実行を処理します。アンサンブル モデルは、あるモデルの出力テンソルを他のモデルの入力として供給する方法を定義します。
NVIDIA Triton アンサンブル モデルを使用すると、推論パイプライン全体を GPU または CPU、あるいは両方の組み合わせで実行することができます。これは、前処理や後処理が必要な場合や、パイプラインに複数の ML モデルがあり、あるモデルの出力が他のモデルにフィードされる場合に有効です。パイプラインにループや条件、その他のカスタム ロジックが含まれる場合では、NVIDIA Triton は Business Logic Scripting (BLS) をサポートします。
この記事では、アンサンブル モデルのみに焦点を当てます。異なるフレームワーク バックエンドを使用した複数のモデルでエンドツーエンドの推論パイプラインを作成する手順について説明します。NVIDIA Triton は、複数のフレームワーク バックエンドを使用してモデル パイプラインを構築し、GPU または CPU、またはその両方の組み合わせでそれらを実行する柔軟性を提供します。ここでは、パイプラインを実行する以下の 3 つの方法を検討します。
- パイプライン全体が CPU 上で実行される場合
- 前処理と後処理のステップは CPU で実行され、モデルは GPU で実行される場合
- パイプライン全体が GPU 上で実行される場合
また、NVIDIA Triton Inference Server を使用して推論パイプライン全体を GPU 上で実行する利点も紹介します。ここでは、推論パイプライン全体に NVIDIA Triton を使用し、3 年生から 12 年生までの文学作品の複雑さの割合を予測する CommonLit Readability Kaggle チャレンジに焦点を当てます。なお、このブログ記事の目的には、NVIDIA Triton 22.11 を使用しました。なお、互換性エラーを避けるために、バックエンド間で一致するバージョン (<xx.yy> と表記) を使用することを条件に、それ以降の NVIDIA Triton のリリースも使用することが可能です。
モデルの作成
このタスクのために、2 つの別々のモデルを訓練します: PyTorch を使用して訓練された BERT Large と、cuML を使用して訓練されたランダム フォレスト回帰です。これらのモデルを bert-large と cuml と名付けます。どちらのモデルも、前処理された抜粋 (訳注: 文章の一部だけを取り出して処理するの意) を入力として取り込み、スコア (複雑度) を出力します。
最初のモデルとして、340M のパラメーターを持つ学習済みの Hugging Face モデル bert-large-uncased から Transformer ベースの bert-large モデルをファインチューニングします。BERT の最後の隠れ層を単一の出力値にマッピングする線形層を追加することで、タスクのためにモデルをファインチューニングします。
二乗平均平方根損失、荷重減衰付きの Adam optimizer、5-Fold 交差検証を使用して、ファインチューニングします。サンプル入力をモデルに渡し、以下のコマンドでモデルをトレースすることで、モデルを TorchScript ファイル (model.pt という名前) としてシリアライズします:
traced_script_module = torch.jit.trace(bert_pytorch_model,
(example_input_ids, example_attention_mask))
traced_script_module.save("model.pt")2 番目のモデルとして、100 本の木と各木の最大深さ 16 の cuML ランダム フォレスト回帰を使用します。ツリーベース モデルのために次の特徴を生成します: 抜粋あたりの単語数、抜粋あたりの異なる単語の数、句読点の数、抜粋あたりの文の数、文あたりの平均単語数、抜粋あたりのストップワード数、文あたりの平均ストップワード数、コーパス全体で最も高い N 個の単語の頻度分布、コーパス全体で最も低い N 個の単語の頻度分布。
N=100 を使用し、ランダム フォレストが合計 207 個の特徴を取り込むようにします。以下のコマンドで cuML モデルインスタンスを変換し、学習済み cuML モデルを Treelite チェックポイント (checkpoint.tl という名前 ) としてシリアライズします:
cuml_model.convert_to_treelite_model().to_treelite_checkpoint('checkpoint.tl')なお、モデルに関連付けられた Treelite のバージョンは、推論に使用する NVIDIA Triton コンテナー内の Treelite のバージョンと一致する必要があります。
NVIDIA Triton 上での ML モデルの実行
NVIDIA Triton で展開される各モデルには、モデル設定が含まれている必要があります。デフォルトでは、NVIDIA Triton はモデルのメタデータが利用可能な場合、そのメタデータを使用して設定を自動的に作成しようとします。モデルのメタデータが十分でない場合や、推測された設定を上書きするために、モデル設定ファイルを手動で提供できます。詳細は GitHub の triton-inference-server/server を参照してください。
PyTorch 形式の BERT Large を NVIDIA Triton で実行するには、PyTorch (LibTorch) backend を使用します。このバックエンドを指定するには、モデル設定ファイルに以下の行を追加してください:
backend: "pytorch"NVIDIA Triton でツリーベースのランダム フォレスト モデルを実行するには、モデル設定ファイルに以下を追加して FIL (Forest Inference Library) backend を使用します:
backend: "fil"さらに、提供されるモデルが Treelite バイナリ形式であることを指定するために、モデル設定ファイルに以下の行を追加します:
parameters {
key: "model_type"
value: { string_value: "treelite_checkpoint" }
}最後に、各モデル設定ファイルにおいて、GPU と CPU のどちらでモデルを提供するかによって、 instance_group[{kind:KIND_GPU}] か instance_group[{kind:KIND_CPU}] を含めます。
ここまでの結果、モデル リポジトリのディレクトリ構造は以下のようになります:
.
├── bert-large
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
└── cuml
├── 1
│ └── checkpoint.tl
└── config.pbtxt前処理と後処理
前処理と後処理は、NVIDIA Triton Server の外部で実行することも、NVIDIA Triton のモデルのアンサンブルの一部として組み込むことも可能です。この例では、前処理と後処理は Python で実行される操作で構成されています。アンサンブルの一部としてこれらの操作を実行するには、Python backend を使用します。
NVIDIA Triton のサーバー コンテナーに同梱されているデフォルトの Python バージョンで Python モデルを実行できる場合は、以下のセクションを飛ばして、「推論パイプラインの比較」セクションに進むことができます。そうでない場合は、以下に説明するカスタム Python バックエンド スタブやカスタム実行環境を作成する必要があります。
カスタム Python バックエンド スタブ
Python バックエンドは、スタブ プロセスを使用して model.py ファイルを NVIDIA Triton C++ コアに接続します。Python バックエンドは、現在の Python 環境 (仮想環境または Conda 環境) またはグローバル Python 環境にインストールされているライブラリを使用できます。
これは、バックエンド スタブのコンパイルに使用される Python のバージョンが、依存関係のインストールに使用されるバージョンと同じであることを前提としていることに注意してください。執筆時に使用した NVIDIA Triton コンテナーのデフォルトの Python のバージョンは 3.8 です。前処理と後処理を実行する必要がある Python のバージョンが NVIDIA Triton コンテナー内のものと一致しない場合、カスタム Python バックエンド スタブをコンパイルする必要があります。
カスタム Python バックエンド スタブを作成するには、NVIDIA Triton コンテナー内に conda、cmake、rapidjson、および libarchive をインストールします。次に、Conda の仮想環境を作成し (ドキュメントを参照)、以下のコマンドを使用して有効にします:
conda create -n custom_env python=<python-version>
conda init bash
bash
conda activate custom_env<python-version> を 3.9 のような目的のバージョンに置き換えてください。次に、Python バックエンド リポジトリをクローンし、以下のコードを使用して Python バックエンド スタブをコンパイルしてください:
git clone https://github.com/triton-inference-server/python_backend -b r<xx.yy>
cd python_backend
mkdir build && cd build
cmake -DTRITON_ENABLE_GPU=ON -DCMAKE_INSTALL_PREFIX:PATH=`pwd`/install ..
make triton-python-backend-stubなお、<xx.yy> は NVIDIA Triton コンテナーのバージョンに置き換える必要があります。上記のコマンドを実行すると、triton-python-backend-stub という名前のスタブ ファイルが作成されます。この Python バックエンド スタブを使用して、一致するバージョンの Python でインストールされているライブラリをロードできるようになりました。
カスタム実行環境
Python モデルごとに異なる Python 環境を使用する場合は、カスタム実行環境を作成する必要があります。Python モデル用のカスタム実行環境を作成するには、まず、すでに有効化されている Conda 環境に必要な依存関係をインストールする必要があります。次に、conda-pack を実行して、カスタム実行環境を tar ファイルとしてパッケージ化します。これにより、custom_env.tar.gz という名前のファイルが作成されます。
この記事の執筆時点では、NVIDIA Triton は実行環境のキャプチャを目的とした conda-pack のみをサポートしています。なお、NVIDIA Triton の Docker コンテナー内で作業する場合、コンテナーに含まれるパッケージも conda-pack で作成した実行環境内に取り込まれます。
Python バックエンド スタブ、カスタム実行環境の利用について
Python バックエンド スタブとカスタム実行環境を作成したら、出来上がった 2 つのファイルをコンテナーからモデル リポジトリがあるローカル システムにコピーします。ローカル システムでは、スタブ ファイルを、スタブを使用する必要がある各 Python モデル (つまり、前処理モデルと後処理モデル) のモデル ディレクトリにコピーします。これらのモデルの場合、ディレクトリ構造は以下のようになります:
model_repository
├── postprocess
│ ├── 1
│ │ └── model.py
│ ├── config.pbtxt
│ └── triton_python_backend_stub
└── preprocess
├── 1
│ └── model.py
├── config.pbtxt
└── triton_python_backend_stub前処理モデルと後処理モデルでは、カスタム実行環境の tar ファイルへのパスも設定ファイルに記述する必要があります。例えば、前処理モデルの設定ファイルには、以下のコードを記述します:
name: "preprocess"
backend: "python"
...
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "path/to/custom_env.tar.gz"}
}この手順を実行するためには、NVIDIA Triton Inference Server コンテナーがアクセスできるパスに custom_env.tar.gz を保存します。
前処理および後処理用 model.py のファイル構成
各 Python モデルは、ドキュメントに記載されているように、特定の構造に従う必要があります。model.py ファイル内に以下の 3 つの関数を定義してください:
1. initialize (任意、モデルのロード時に実行される): 推論前に必要なコンポーネントをロードし、各クライアント リクエストのオーバーヘッドを削減するために使用します。具体的には前処理のために、BERTベースのモデルの抜粋をトークン化するために使用される cuDF tokenizer をロードします。 また、ツリーベースのモデルへの入力の一部として、ランダム フォレスト特徴生成に使用されるストップワードのリストもロードします。
2. execute (必須、推論が要求されたときに実行される): 推論リクエストを受け入れ、入力を修正し、推論レスポンスを返します。preprocess は推論の入口であるため、GPU 上で推論を行う場合は、入力を GPU に移す必要があります。
cudf.Series のインスタンスを作成して抜粋入力テンソルを GPU に移動し、initialize でロードされた cuDF tokenizer を利用して GPU 上で抜粋のバッチ全体をトークン化します。
同様に、文字列操作を使ってツリーベースの特徴を生成し、GPU 上で動作する CuPy 配列を使って特徴を正規化します。GPU 上でテンソルを出力するには、toDlpack と from_dlpack (ドキュメント参照) を使って、テンソルを推論レスポンスにまとめます。
最後に、テンソルを GPU 上に保持し、アンサンブルのステップ間で CPU にコピーすることを避けるため、各モデルの設定ファイルに以下を追加します:
parameters: {
key: "FORCE_CPU_ONLY_INPUT_TENSORS"
value: {
string_value:"no"
}
}postprocess 用の入力スコアはすでに GPU 上にあるので、CuPy 配列で再度スコアをアンサンブルし、最終的なパイプライン スコアを出力すればよいだけです。後処理を CPU で行う場合は、前処理段階で ML モデルの出力を CPU に移します。
3. finalize (任意、モデルをアンロードする際に実行): NVIDIA Triton Server からモデルをアンロードする前に、必要なクリーンアップを完了させることができます。
推論パイプラインの比較
ここでは、さまざまな推論パイプラインを紹介し、レイテンシとスループットの観点から比較します。
CPU で前処理および後処理、GPU で ML モデルの推論を行う
このセットアップでは、NVIDIA Triton を使用して ML モデルの推論を行い、前処理と後処理はクライアントが存在するローカルマシンの CPU を使用して実行します (図 1)。前処理モデルでは、与えられたテキスト抜粋のバッチに対して、BERT トークナイザーを使用して抜粋をトークン化し、cuML モデル用のツリーベースの特徴を生成します。
そして、前処理モデルの出力を推論リクエストとしてNVIDIA Triton に送ります。すると NVIDIA Triton は、GPU 上の ML モデルに対して推論を行い、レスポンスを返します。このレスポンスを CPU 上でローカルに後処理して、出力スコアを生成します。
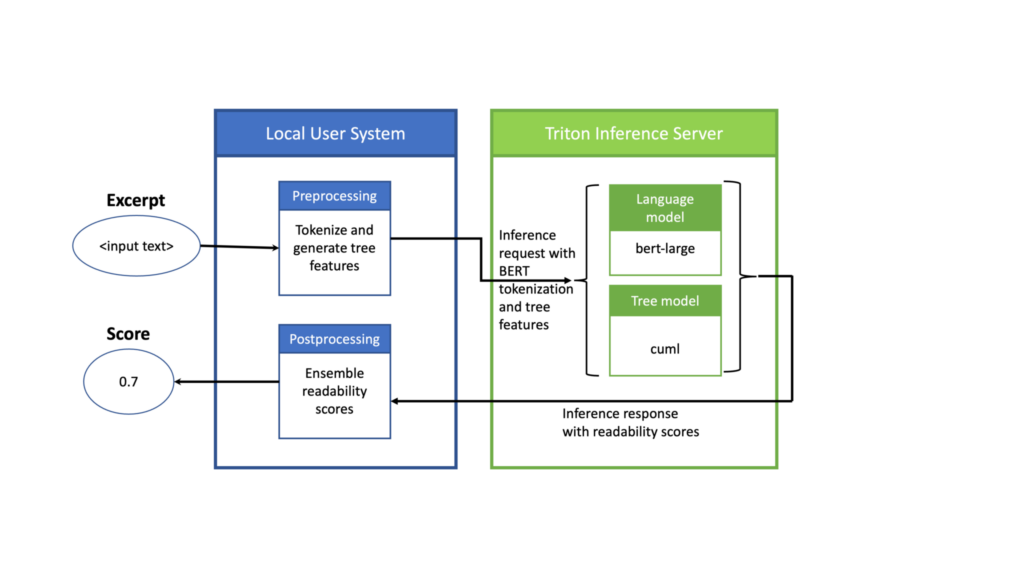
GPU 上の NVIDIA Triton でパイプライン全体を実行する
この設定では、NVIDIA Triton を使用して GPU 上で推論パイプライン全体を実行します。この例では、NVIDIA Triton 内のパイプラインとデータの流れを、図 2 で示しています。
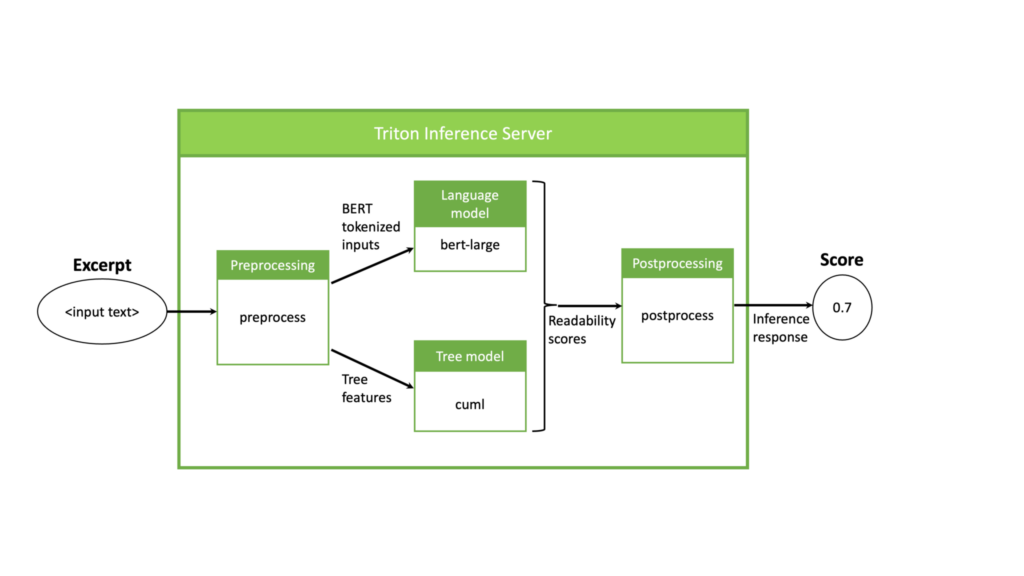
パイプラインは、まず前処理モデルから始まり、テキストの抜粋を入力として受け取り、BERT 用に抜粋をトークン化し、ランダム フォレスト モデル用の特徴を抽出します。次に、前処理モデルの出力に対して 2 つの ML モデルを同時に実行し、それぞれが入力テキストの複雑度を示すスコアを生成します。最後に、得られたスコアは後処理のステップで結合されます。
NVIDIA Triton に上記の実行パイプラインを実行させるために、ensemble_all というアンサンブル モデルを作成します。このモデルは、モデルを保存せず、設定ファイルのみで構成されていることを除けば、他のモデルと同じモデル ディレクトリ構造を持っています。アンサンブル モデルのディレクトリは以下の通りです:
├── ensemble_all
│ ├── 1
│ └── config.pbtxt構成ファイルでは、まず以下のスクリプトを使用してアンサンブル モデル名とバックエンドを指定します:
name: "ensemble_all"
backend: "ensemble"次に、アンサンブルのエンドポイント、すなわちアンサンブル モデルの入力と出力を定義します:
input [
{
name: "excerpt"
data_type: TYPE_STRING
dims: [ -1 ]
},
{
name: "BERT_WEIGHT"
data_type: TYPE_FP32
dims: [ -1 ]
}
]
output {
name: "SCORE"
data_type: TYPE_FP32
dims: [ 1 ]
}パイプラインの入力は可変長であるため、dimension パラメーターには -1 を使用します。出力は 1 つの浮動小数点数です。
異なるモデルを介するパイプラインとデータの流れを作成するには、ensemble_scheduling セクションを含めます。最初のモデルは preprocess と呼ばれ、抜粋を入力として取り込み、BERT トークン識別子とアテンション マスク、およびツリー特徴を出力します。スケジューリングの最初のステップは、モデル設定の以下の部分に示されています:
ensemble_scheduling {
step [
{
model_name: "preprocess"
model_version: 1
input_map {
key: "INPUT0"
value: "excerpt"
}
output_map {
key: "BERT_IDS"
value: "bert_input_ids",
}
output_map {
key: "BERT_AM"
value: "bert_attention_masks",
}
output_map {
key: "TREE_FEATS"
value: "tree_feats",
}
},step セクションの各要素は、使用するモデルと、そのモデルの入力と出力をアンサンブル スケジューラーが認識するテンソル名にマッピングする方法を指定します。そして、これらのテンソル名は、個々の入力と出力を識別するために使用されます。
例えば、step の最初の要素は、preprocess モデルのバージョン 1 を使用することを指定し、その入力 "INPUT0" の内容は "excerpt" テンソルによって提供され、その出力 "BERT_IDS" の内容は後で使用するために "bert_input_ids" テンソルにマッピングされます。同様の推論が、preprocess の他の 2 つの出力にも適用されます。
パイプライン全体を指定するために、設定ファイルにステップを追加し続け、preprocess の出力を bert-large と cuml の入力に渡します:
{
model_name: "bert-large"
model_version: 1
input_map {
key: "INPUT__0"
value: "bert_input_ids"
}
input_map {
key: "INPUT__1"
value: "bert_attention_masks"
}
output_map {
key: "OUTPUT__0"
value: "bert_large_score"
}
},最後に、設定ファイルに以下の行を追加することで、これらのスコアのそれぞれを後処理モデルに渡し、以下のようにスコアの平均を計算し、単一の出力スコアを提供するようにします:
{
model_name: "postprocess"
model_version: 1
input_map {
key: "BERT_WEIGHT_INPUT"
value: "BERT_WEIGHT"
}
input_map {
key: "BERT_LARGE_SCORE"
value: "bert_large_score"
}
input_map {
key: "CUML_SCORE"
value: "cuml_score"
}
output_map {
key: "OUTPUT0"
value: "SCORE"
}
}
}
]アンサンブル モデルの設定ファイル内でパイプライン全体をスケジューリングするというシンプルさは、エンドツーエンド推論に NVIDIA Triton を使用することの柔軟性を示しています。別のモデルを追加したり、別のデータ処理ステップを追加したりするには、アンサンブル モデルの設定ファイルを編集して、対応するモデル ディレクトリを更新します。
なお、アンサンブル設定ファイルで定義した max_batch_size は、各モデルで定義した max_batch_size 以下でなければなりません。アンサンブル モデルを含む、モデル ディレクトリ全体を以下に示します:
├── bert-large
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
├── cuml
│ ├── 1
│ │ └── checkpoint.tl
│ └── config.pbtxt
├── ensemble_all
│ ├── 1
│ │ └── empty
│ └── config.pbtxt
├── postprocess
│ ├── 1
│ │ ├── model.py
│ └── config.pbtxt
└── preprocess
├── 1
│ ├── model.py
└── config.pbtxtNVIDIA Triton にすべてのモデルを GPU で実行するように指示するには、各モデルの設定ファイルに以下の行を記述します (アンサンブル モデルの設定ファイルは除く):
instance_group[{kind:KIND_GPU}]CPU 上の NVIDIA Triton でパイプライン全体を実行し、CPU 上で NVIDIA Triton にパイプライン全体を実行させるには、GPU でパイプラインを実行するために説明したすべてのステップを繰り返します。各設定ファイルの instance_group[{kind:KIND_GPU}] を以下の行に置き換えてください:
instance_group[{kind:KIND_CPU}]結果
GCP a2-highgpu-1g VM を用いて、以下の 3 つの推論パイプラインのレイテンシとスループットを比較しました:
- 2.20GHz Intel Xeon CPU での NVIDIA Triton によって実行されるフル パイプライン
- 2.20 GHz Intel Xeon CPU 上でローカル実行される前後処理と、NVIDIA A100 40GB GPU 上の NVIDIA Triton によって実行される ML モデル
- NVIDIA A100 40GB GPU 上の NVIDIA Triton によって実行されるフル パイプライン
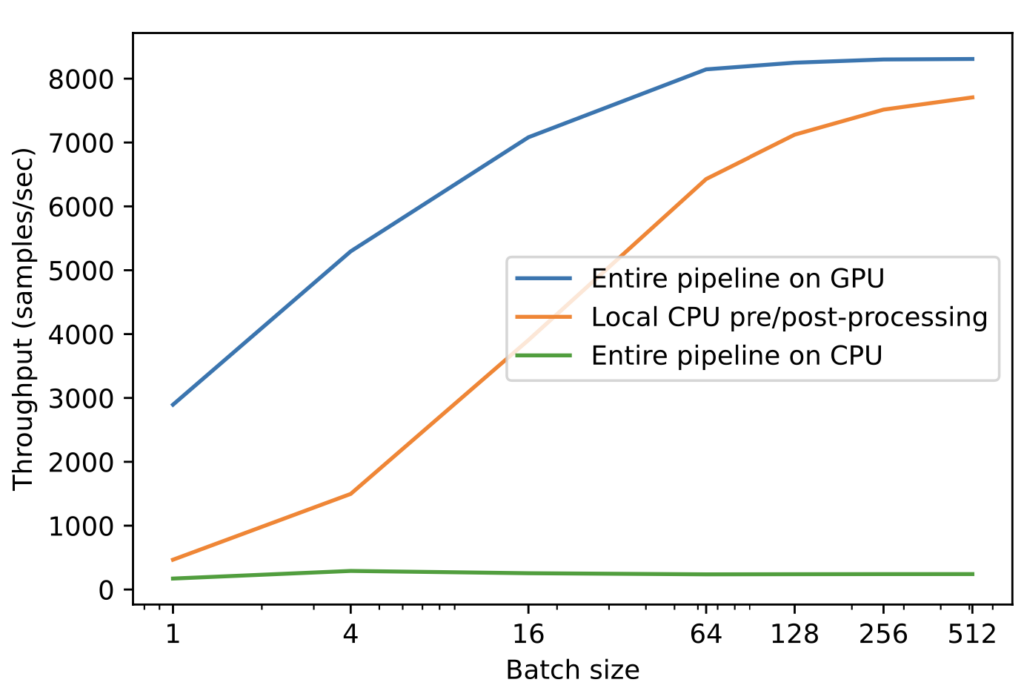
NVIDIA Triton を用いてパイプライン全体を GPU で実行することの利点は、表 1 の結果から明らかです。 バッチ サイズとテンソル サイズが大きいほど、スループットの向上がより顕著になります。 NVIDIA A100 40GB モデル実行パイプラインは、2.20GHz の Intel Xeon CPU 上のフル パイプラインよりはるかに効率的です。前処理と後処理を CPU から GPU に移すと、さらに改善されます。
| Full pipeline on CPU | Pre/postprocess on CPU; ML models on GPU | Full pipeline on GPU | |
| Latency (ms) | 523 | 192 | 31 |
| Throughput (samples/second) for batch size 512 | 242 | 7707 | 8308 |
図 3 に示すように、非常に控えめなバッチ サイズでは CPU がボトルネックとなり、パイプライン全体を GPU 上で実行することでスループットが劇的に向上します。
まとめ
この記事は、Kaggle の課題を解決するために、NVIDIA Triton Inference Server を使用して、前処理と後処理、Transformer ベースの言語モデル、およびツリーベースモデルからなる推論パイプラインを実行する方法について説明しています。NVIDIA Triton は、同一パイプラインのモデルや前処理/後処理ロジックに複数のフレームワーク/バックエンドを使用できる柔軟性を備えています。これらのパイプラインは、CPU や GPU で実行することができます。
モデル実行と同時に前処理と後処理フェーズに GPU を活用することで、前処理と後処理ステップを CPU で実行し、モデル実行を GPU で行う場合と比較して、エンドツーエンド レイテンシを 6 倍短縮できることを示しました。また、NVIDIA Triton を使用することで、複数の ML モデルに対して同時に推論を実行することができ、ある配置タイプ (全 CPU) から別の配置タイプ (全 GPU) に移行するには、設定ファイルに 1 行の変更を加えるだけでよいことも示しています。
ご質問やご意見がありましたら、ご連絡ください。推論パイプラインが他のタスクで NVIDIA Tritonを活用することを楽しみにしています。ソフトウェアのダウンロードと詳細については、NVIDIA Triton Inference Server のページをご覧ください。
翻訳に関する免責事項
この記事は、「Serving ML Model Pipelines on NVIDIA Triton Inference Server with Ensemble Models」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。