GPU は新しい世代になるごとに高速化され続けており、GPU 上の各アクティビティ (カーネルやメモリ コピーなど) が非常に速く完了することがよくあります。従来、各アクティビティは CPU が個別にスケジューリング (起動) する必要があり、関連するオーバーヘッドが蓄積して性能のボトルネックになることがありました。CUDA Graphs 機能は、複数の GPU アクティビティを 1 つの計算グラフとしてスケジュールできるようにすることで、この問題に対処します。
この記事では、生体分子システムのシミュレーション パッケージであり、世界で最も利用されている科学ソフトウェア アプリケーションの 1 つである GROMACS で、CUDA Graphs がどのように最近では活用されているかをご説明します。CUDA Graphs と GROMACS を紹介し、CUDA Graphs を GROMACS に統合 (および共同設計) するための NVIDIA の作業を説明し、性能結果を示し、GROMACS 内で CUDA Graphs を使用する方法を紹介するご予定です。
GROMACS は、NVIDIA と GROMACS の中心的な開発者との複数年にわたるコラボレーションにより、最新の GPU アクセラレーション サーバーを最大限に活用できるように進化しています。詳細は、Creating Faster Molecular Dynamics Simulations with GROMACS 2020 (GROMACS 2020 による高速な分子動力学シミュレーションの作成)、Maximizing GROMACS Throughput with Multiple Simulations per GPU Using MPS and MIG (MPS と MIG を使用して GPU ごとに複数シミュレーションを行い GROMACS スループットを最大化)、Massively Improved Multi-node NVIDIA GPU Scalability with GROMACS (GROMACS によるマルチノード NVIDIA GPU のスケーラビリティの大幅な向上)、Heterogeneous parallelization and acceleration of molecular dynamics simulations in GROMACS (GROMACS における分子動力学シミュレーションのヘテロジニアス並列化と高速化) (およびその参考文献) をご覧下さい。
背景
GROMACS の取り組みにおける最新のステップは、CUDA Graphs を使用して性能をさらに向上させることです。この機能は、新しい 2023 年版のリリースで利用できます。この共同設計の取り組みには、アプリケーションレベルの専門家だけでなく、NVIDIA CUDA ソフトウェア開発チームも参加しています。最先端の CUDA Graphs テクノロジと一体となって GROMACS を改善することは、最終的に他のアプリケーションにも利益をもたらすでしょう。
CUDA Graphs
このセクションでは、GROMACS に適した方法で構成された、CUDA Graphs の非常に簡単な概要を説明します。CUDA Graphs の詳細については、「Getting Started with CUDA Graphs (CUDA Graphs の概要) 」の記事をご覧ください。
図 1 は、多数の GPU アクティビティのスケジューリングと実行を示しています。従来のストリーム モデル (左) では、各 GPU アクティビティは CPU API 呼び出しによって個別にスケジューリングされます。CUDA Graphs (右) を使用すると、1 回の API 呼び出しで GPU アクティビティの全セットをスケジューリングできます。
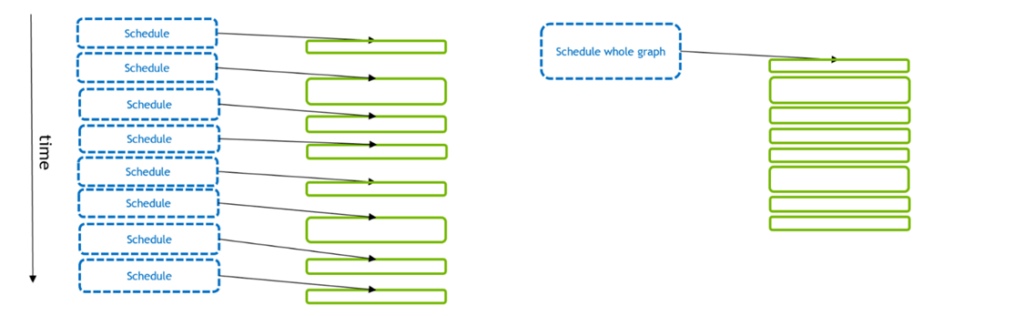
GPU のアクティビティが小さいと、実行よりもスケジューリングに多くの時間がかかることがあります。これは GPU を枯渇させ (カーネル間にギャップを残す)、全体として最適でない実行となります。しかし、複数の GPU アクティビティが 1 つの CUDA Graphs でスケジュールされると、CPU API 時間が短縮され、より最適な GPU 実行が可能になります。さらに、Graphs では、CUDA ドライバーはワークフローに関する追加情報を持っており、それを利用してGraphs 自体の GPU 実行を最適化することができます。
Getting Started with CUDA Graphs (CUDA Graphs の概要) で説明したように、既存のストリームベースのコードをグラフに適合させることは比較的容易です。この機能は、いくつかの CUDA API 呼び出しを介して、ストリーム実行をグラフに「キャプチャ」します。この機能を利用して、既存の GROMACS コードを、ストリームの代わりにグラフを使って実行できるようにしました。
GROMACS
GROMACS は、COVID-19 のようなパンデミックの根底にあるものを含む、重要な生物学的プロセスを理解する上で有力なツールです。GROMACS の各シミュレーションは、ニュートン運動方程式を用いた更新を繰り返しながら多数の粒子からなるシステムを発展させ、そこでは粒子間の力が粒子の動きを決定します。
物理学はかなり単純ですが、実装は (必然的に) 非常に複雑であり、複数のレベルの並列化と高速化によって非常に高い性能を実現します。そのため、各シミュレーションのタイムステップには、非常に複雑な (多くの場合マイクロ秒規模の) タスクのスケジュールが含まれます。
図 2 は、GROMACS が分子動力学の非同期 GPU エンジンに進化した様子を左から右に順に示しています。
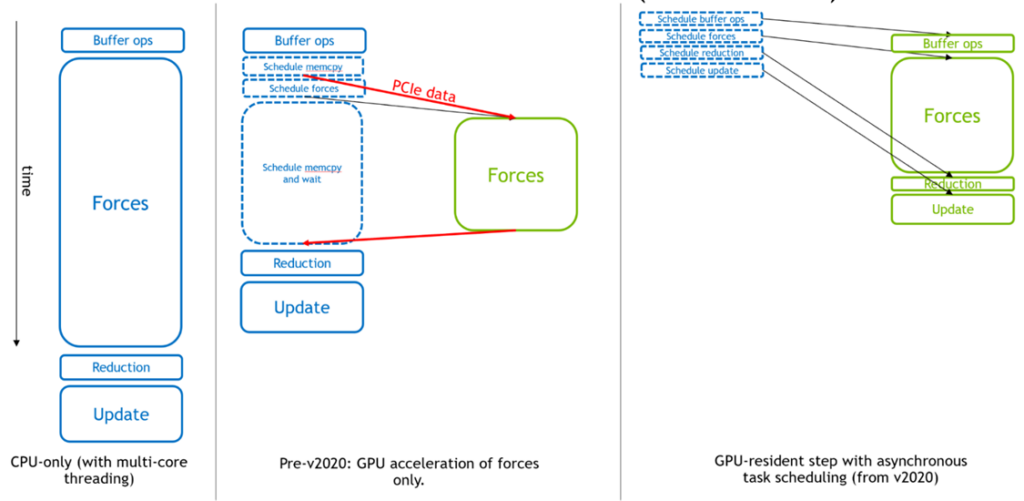
元々、CPU は各シミュレーションのタイムステップ全体に使用されていました。その後、GPU コンピューティングの初期に、重たい力の計算を GPU にオフロードして、効果的に全体を高速化するようになりました。
ついに、非常に高速な最新の GPU をサポートするために、GROMACS バージョン 2020 からは、他のすべてのコンポーネントをオフロードして、「GPU 常駐モード」を有効にすることができるようになりました。このモードでは、シミュレーションの状態が複数のイテレーションで GPU 上に残り、CPU は主に GPU 上で非同期に実行されるアクティビティのスケジューリングを担当します。詳細は、Creating Faster Molecular Dynamics Simulations with GROMACS 2020 (GROMACS 2020 による高速な分子動力学シミュレーションの作成) をご覧ください。
図 2 の右側は、GPU の計算が十分な大きさであれば、実行の「クリティカル パス」を形成し、これらのコンポーネントの性能がシミュレーション全体の性能を決定することを示しています。
ただし、GPU の性能がますます向上する中、前述したように、小規模なケースでは GPU の実行よりも CPU のスケジューリング オーバーヘッドによって制限されることがあります。これは、1 つのGROMACS シミュレーションを実行するために複数の GPU を並列に使用する場合、この傾向が顕著になります。
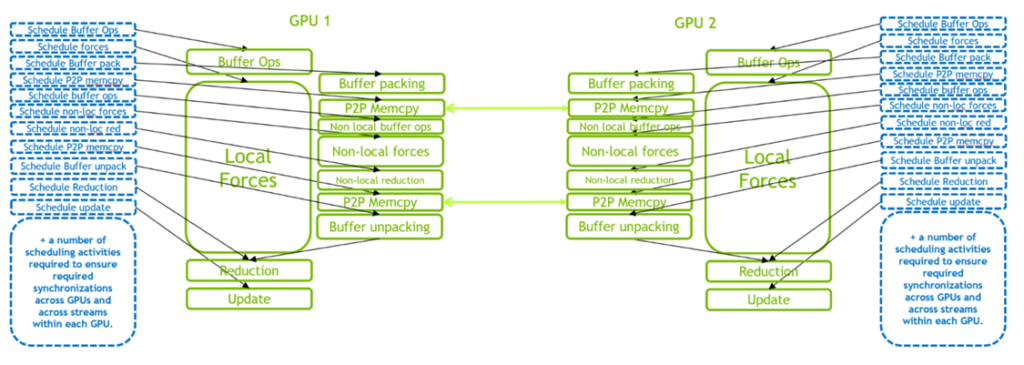
図 3 は、2 基の GPU の場合の GPU 常駐モードを示しています。このシナリオでは、GPU 内と GPU 間の複雑な相互作用により、単一の GPU の場合よりもはるかに高い CPU スケジューリング作業負荷が発生します。さらに多くの GPU を導入した場合、スケジューリング作業負荷はさらに高くなります。
したがって、多くの小さなケースでは、性能のボトルネックは GPU 実行よりも CPU スケジューリングのオーバーヘッドとなります。このため、次のセクションでは、GROMACS に CUDA Graphsを導入し、複数のアクティビティを 1 つのグラフとしてスケジューリングする方法についてご説明します。
GROMACS で CUDA Graphs を実装
このセクションでは、GROMACS に CUDA Graphs を導入する方法についてご説明します。ハイレベルでは、Getting Started with CUDA Graphs (CUDA Graphs の概要) で提供された例と同様のスタイルでグラフ キャプチャとリプレイ機能が使用されます。
GROMACS の実装には、GROMACS がさまざまなステップで実行できるさまざまな種類のタスクや、マルチ GPU タスクとドメイン分割の管理に関連した複雑さがあります。簡単な概要については、以下をお読みください。技術的な詳細については、GitLab の Issue、Implement CUDA Graph Functionality and Perform Associated Refactoring (CUDA Graph 機能の実装と関連リファクタリングの実行)、およびそこにリンクされているマージ リクエストを参照してください。
GROMACS は、異なるタイプのシミュレーション ステップを実行することに注意してください: GROMACS は、「規則的な」ステップと、たまに実行される追加のアクティビティ (圧力カップリング、温度カップリング、近隣リスト更新、ドメイン分割など) を含む「不規則な」ステップという異なるタイプのシミュレーション ステップを実行します。NVIDIA は、GROMACS に CUDA Graphs を導入し、ステップごとに独立したグラフを使用することで、今のところ完全に GPU に常駐する規則的なステップのみをサポートしています。
各シミュレーション タイムステップ:
- このステップが CUDA Graphs をサポートできるかどうかを確認。「はい」の場合:
- 適切なグラフが既に存在するかどうかを確認。「はい」の場合:
- そのグラフを実行
- その他の場合: 新しいグラフをキャプチャし、インスタンス化し、保存
- 適切なグラフが既に存在するかどうかを確認。「はい」の場合:
- その他の場合: 従来のストリームを使用してステップを実行
これにより、大半のステップで CUDA Graph を用いた実行が可能になります。近隣リストやドメイン分割のステップごとに (通常 100-400 ステップごと) 新しいグラフ実行ファイルを再キャプチャして作成する必要がありますが、これは最小限のオーバーヘッドになる程度に頻度が低いです。
マルチ GPU では、すべての GPU で単一のグラフを使用します。今のところ、これは スレッド MPI でのみサポートされており、マルチ GPU グラフは、同じプロセス内で異なる GPU 間でストリームを分岐および結合する CUDA の自然な機能 (イベントベースの GPU 側同期を使用) を利用し、自動的に単一のグラフにそうしたワークフローをキャプチャすることによって定義されています。
必要な機能をすべて管理するために、GROMACS に新しいクラスを作成しました。マルチ GPU の場合、イベントベースの分岐と結合操作を追加して、1 つのグラフを複数の GPU で定義して実行できるようにしました。
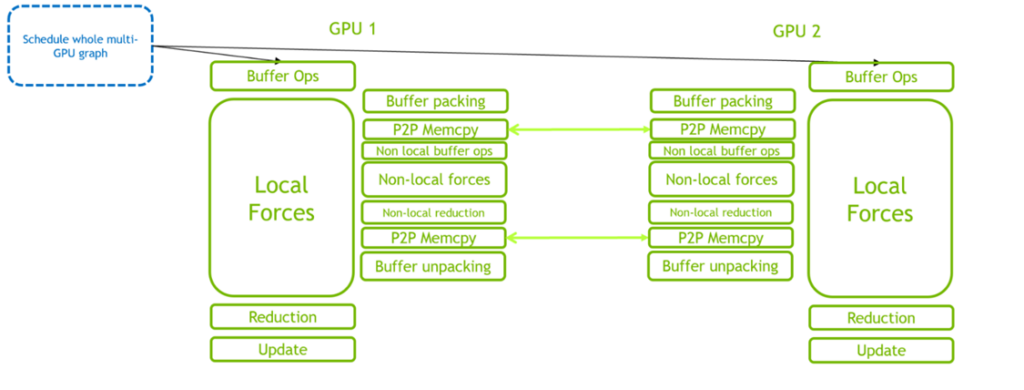
CPU 側のオーバーヘッドを削減する CUDA Graphs の利点は、図 3 と図 4 を比較すれば明らかです。クリティカル パスは、CPU のスケジューリング オーバーヘッドから GPU の計算へとシフトしています。
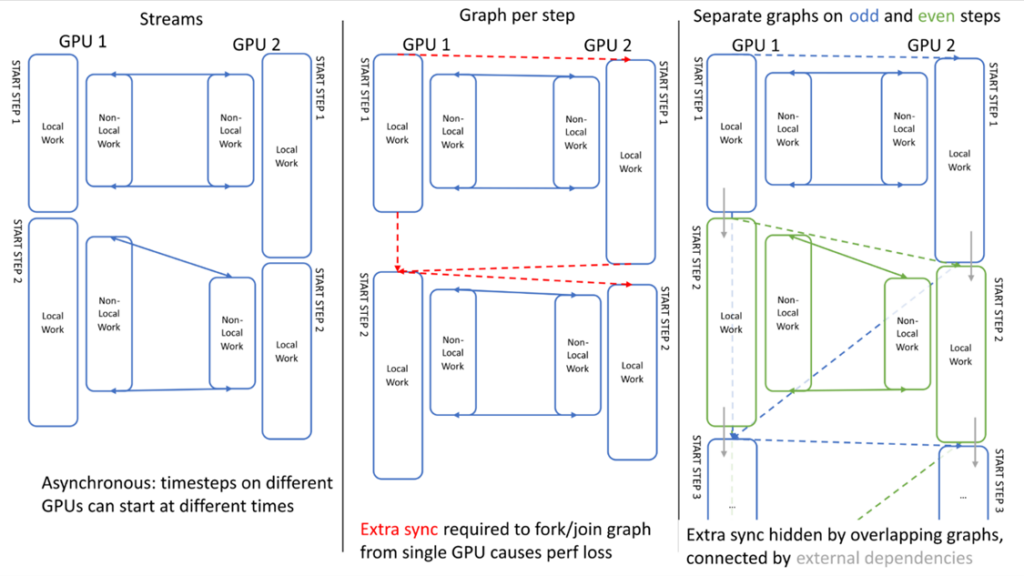
マルチ GPU の性能を最大限に発揮するためには、複数のシミュレーション タイムステップをリンクする際に GPU 間の非同期性を確保することが重要です。図 5 は、2 つのステップにまたがる GPU アクティビティを示しています。従来のストリームを使用した場合、実行は GPU 間で非同期であることがわかります: GPU1 は、GPU2 が最初のステップを終了する前に 2 番目のステップを開始することができます (左)。
単一のグラフを使用したスケジューリングの最初の試みで問題が発生しました: グラフを定義するために必要な余分な同期 (単一 GPU 上の始点/終点の分岐/結合) がこの非同期性を失わせ、オーバーヘッドを発生させます (中央)。
この問題は、奇数ステップと偶数ステップで別々のグラフを使用し、これらを「外部」CUDA イベントを使ってリンクさせ、1 つのグラフ内で記録し、別のグラフ内でエンキューし (灰色の矢印)、余分な同期を効果的にオーバーラップすることで克服しています (右)。
図 6 は、典型的な 4 基の GPU 構成の通常のタイムステップから得られる実際のグラフを示したものです。詳細は説明しませんが、このグラフを含めることで、多くのアクティビティと依存関係があること、そして CUDA Graphs がこの複雑さをいかに効果的に処理できるかを視覚的に示すことができます。
CUDA Graphs 技術自体の開発は、マルチスレッドのグラフ キャプチャと連動したグラフ更新のサポートや、グラフ内のストリーム優先度のサポートなど、GROMACS の要件に基づいています。これらの機能強化は、最終的には他のアプリケーションにも利益をもたらすでしょう。
性能結果
GROMACS における CUDA Graphs の利点を実証するために、Water Box ベンチマーク セットを使用しました。このベンチマーク セットは gromacs.org ベンチマーク リポジトリで入手可能です。このベンチマークは、複数の原子数を提供するという利点があり、性能の挙動がシステム サイズによってどのように変化するかを評価することができます。
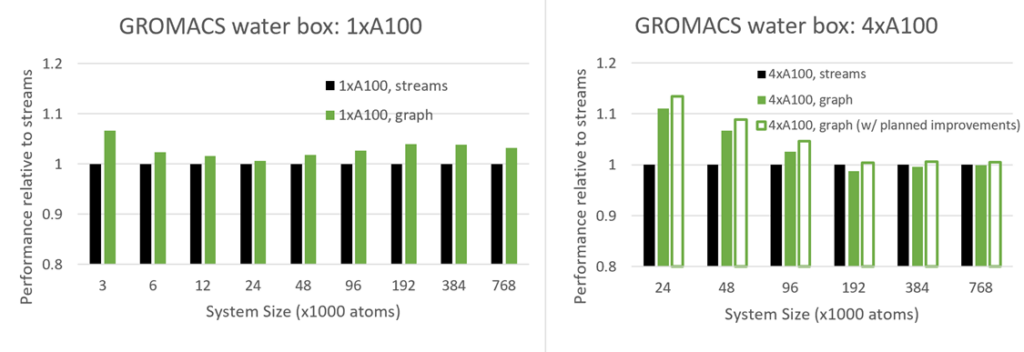
図 7 は、1 基の GPUと 4 基の GPU の両方で、さまざまなシステム サイズについて、新しい CUDA Graphs 機能の性能を従来のストリームと比較しています。
CUDA Graphs は、小規模なケースで最も顕著な CPU の API オーバーヘッドの削減を目的としており、システム サイズが小さいほど効果が高まることが期待されます。実際に複数の GPU のケースと、原子数 24K 以下の単一 GPU のケースでこの挙動が見られます。
興味深いことに、原子数 24K 以上の単一 GPUのケースでは、原子数 100K 付近までシステム サイズに応じて利点が増加し、そこで頭打ちになりました。このように、グラフはあらゆるシステム サイズにおいて、大きな性能優位性を持っていることがわかります。この挙動にはさらなる調査が必要ですが、これは CUDA Graphs の GPU 側の利点によるもので、グラフが使用されているときに CUDA が複数のカーネルにまたがるスレッド ブロックをより効率的にスケジューリングしているためと予想されます。
マルチ GPU の場合、(前述のとおり) 複雑なスケジューリングにより CPU の API オーバヘッドの影響を受けやすいため、グラフの利点はより顕著になります。現在のバージョンでは、原子数 100K 程度までは効果が見られますが (このケースの場合)、それ以上では若干の劣化が見られます。
ただし、グラフを繰り返し再構築することに伴うオーバーヘッドを削減するための改善も計画しており、その予測結果も示しました。この改善には、GROMACS との共同設計で現在改良中の CUDA ドライバーの将来バージョンでのサポートが必要です。一般的には、ユーザーが自身のケースで CUDA Graphs を試し、有益な場合にはその機能を有効にすることをお勧めします (次のセクションを参照)。
GROMACS で CUDA Graphs を使う方法
前述のように、この新しい CUDA Graphs 機能は、GPU 常駐ステップで利用でき、通常、以下の mdrun オプションによってすべての力および更新の計算が GPU にオフロードされるときに起動されます:
-nb gpu -bonded gpu -pme gpu -update gpu複数の GPU を並列に使用するために複数のタスクで実行する場合、GROMACS は外部の MPI ではなく、内部のスレッド MPI ライブラリを使用して構築する必要があります (-DGMX_MPI=OFF); GPU ダイレクト通信は、以下の環境変数で指定します:
export GMX_ENABLE_DIRECT_GPU_COMM=1単一の PME 用 GPU 利用を、 -npme 1 で指定する必要があります。
すると、CUDA Graphs を、以下のようにトリガーすることができます:
export GMX_CUDA_GRAPH=1グラフを使用した方が性能的に有利な場合は、特定のケースで試してみることをお勧めします。この機能はまだ実験的なものであり、テストも限られているため、結果が期待通りであることを確認するために注意が必要です (例えば、グラフを使用した場合と使用しなかった場合の結果の科学的なサブセットを比較するなど)。問題の報告は、是非 GROMACS GitLab サイトにお寄せください。
まとめ
この記事では、CUDA Graphs を GROMACS に統合した方法について説明してきました。これにより、複数の GPU アクティビティを 1 つのコンピューティング グラフで CPU がスケジューリングできるようになり、従来のストリーム プログラミング モデルよりも最適化されました。複数の GPU で並列に実行する場合を含め、その利点も実証しました。この研究は、グラフベースのタスク スケジューリングで GROMACS を近代化し、ますます複雑化する科学的問題を解決するために、ますます複雑になるハードウェアの利用を支援する、私たちの継続的な取り組みの重要な一部です。
まずは、この投稿に記載されている手順に従って、ご自身の GROMACS のケースで CUDA Graphs を有効化してみてください。
より詳細な情報にご興味がある方は、GROMACS フォーラム にご参加ください。
翻訳に関する免責事項
この記事は、「A Guide to CUDA Graphs in GROMACS 2023」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。