As the sizes of AI models and datasets continue to increase, relying only on higher-precision BF16 training is no longer sufficient. Key challenges such as training throughput expectations, memory limits, and rising costs are becoming the primary barriers to scaling transformer models.
Using lower-precision training can address these challenges. By reducing the numeric precision used during computation, GPUs can process more operations per cycle, enhancing training efficiency and lowering costs.
This post compares the following three low-precision training formats directly against established BF16 precision training across multi-hundred-billion token pretraining runs and downstream benchmarks:
- 8-bit floating point per-tensor current scaling (FP8-CS)
- Mixed precision training with FP8 (MXFP8)
- NVFP4 precision training using NVIDIA NeMo Megatron Bridge, an open source library that is part of NVIDIA NeMo framework
We present practical, large-scale results showing how low-precision training delivers up to ~1.6x higher throughput, substantial memory savings, and near-identical model quality using production-ready recipes you can adopt today.
What is low-precision training?
Low-precision training uses numerical formats with fewer bits to represent weights and activations during model training. This reduces memory bandwidth and computational demand, enabling GPUs to process more operations per cycle and significantly increase training throughput.
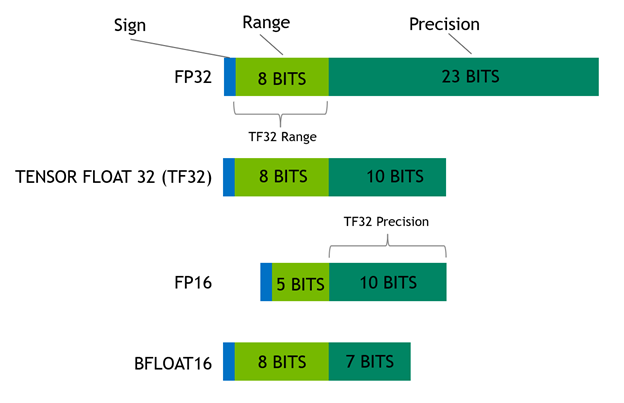
Low-precision formats
FP8-CS applies FP8 to linear layers using scaling factors derived from the statistical properties of each tensor at the current training step. MXFP8 extends the FP8 approach with block-level scaling optimized for the NVIDIA Blackwell architecture, with each block covering 32 tensor elements. NVFP4 further improves memory efficiency and throughput by using the 4-bit format for tensor values with a hierarchical two-level scaling strategy.

Can low-precision training match BF16 accuracy at scale?
To validate the practical impact of low-precision training for real-world large-model pretraining, the team evaluated both the training convergence and downstream task performance across two widely used dense transformer architectures: Llama 3 8B and an NVIDIA internal research 8B model (Research-8B with dense grouped query attention (GQA) architecture that is similar to Llama 3 8B). The models were trained on 1 trillion tokens.
Experimental setup: Isolating the impact of precision
The following large-scale pretraining experiments were run:
- Four numeric precisions: BF16 (baseline), FP8-CS, MXFP8, and NVFP4
- Two model architectures: Llama 3 8B and Research-8B
- Training software and hardware: NeMo Megatron Bridge on NVIDIA B200 GPUs
- Two datasets: Lingua DCLM Dataset and an internal dataset. Llama 3 8B was trained on both datasets and Research-8B was trained on the internal NVIDIA research dataset
Convergence behavior: Training stability across precisions
Figures 2, 3, and 4 show training and validation loss curves for both models and datasets. Low-precision training closely tracks with the BF16 baseline, demonstrating stable and consistent convergence across precisions. In all cases, NVFP4 shows slightly higher loss but downstream accuracies remain unaffected. See Table 1 for more details.



Downstream evaluation: Accuracy is preserved
To assess whether low-precision training impacts real-world performance, we evaluated all pretrained models on standard downstream benchmarks. All evaluations were run in BF16 precision to isolate the impact of training precision.
Table 1 shows the results. Despite minor differences in training and validation loss, all low-precision formats achieve downstream task accuracy comparable to BF16.
| Model | Dataset | Precision | MMLU (↑) | HellaSwag (↑) | WinoGrande (↑) | ARC-C (↑) |
| Llama 3 8B | DCLM | BF16 | 45.98 | 76.44 | 70.17 | 51.28 |
| FP8-CS | 46 | 75.25 | 70.24 | 49.91 | ||
| MXFP8 | 46.56 | 75.46 | 71.27 | 51.11 | ||
| NVFP4 | 45.64 | 75.59 | 69.38 | 51.28 | ||
| Llama 3 8B | Internal dataset | BF16 | 52.73 | 75.71 | 67.88 | 51.37 |
| FP8-CS | 52.46 | 75.65 | 70.17 | 54.52 | ||
| MXFP8 | 53.7 | 75.54 | 69.69 | 51.62 | ||
| NVFP4 | 52.83 | 75.04 | 71.98 | 53.58 | ||
| Research-8B | Internal dataset | BF16 | 53 | 76.98 | 70.4 | 55.89 |
| FP8-CS | 52.62 | 75.81 | 70.8 | 54.44 | ||
| MXFP8 | 52.38 | 76.55 | 69.77 | 53.58 | ||
| NVFP4 | 52.21 | 76.19 | 70.32 | 54.95 |
Key insights
Key insights from these experiments are detailed below.
- Low precision training matches BF16 convergence: FP8, MXFP8, NVFP4 achieve pretraining and validation losses very close to BF16, showing minimal degradation.
- Downstream accuracy is preserved: Across all models and benchmarks, low-precision training delivers downstream task accuracy comparable to BF16, demonstrating that reduced precision maintains model effectiveness.
- MXFP8 performs slightly better than standard FP8: This is likely due to its finer-grained scaling mechanism, which better captures local dynamic range within tensors.
- NVFP4 with proper calibration delivers competitive results despite aggressive compression: The following recipe is the empirical sweet spot: AdamW ϵ=1e-8, LR=6e-4 → 6e-6, GBS=768.
- Selective BF16 layers are essential for NVFP4: Ablation studies show that fully NVFP4 models diverge. Stable training requires keeping some layers in BF16, particularly near the end of the network, to mitigate NVFP4 quantization error. In these experiments, maintaining the final four transformer layers in BF16 proved sufficient.
Advantages of FP8, MXFP8, and NVFP4 training
Low-precision formats deliver clear gains in both training throughput and memory efficiency, enabling faster end-to-end training and better scalability on NVIDIA Blackwell GPUs.
| Precision | Micro-batch size | Throughput (TFLOP/s/GPU) | Speedup versus BF16 |
| BF16 | 2 | 1165 | – |
| FP8-CS (F1L1) | 2 | 1547 | 1.33x |
| MXFP8 | 2 | 1540 | 1.32x |
| NVFP4 (F0L4) | 4 | 1850 | 1.59x |
GBS=128, Seq. Length=8192. Note that FxLy denotes the first ‘x’ layers and last ‘y’ transformer block layers are kept in BF16 precision
Faster end-to-end training
Using 8-bit or 4-bit numeric formats drastically reduces computational overhead by enabling GPUs to process more operations per clock cycle. Gains in throughput can be up to 1.59x over BF16 baseline (Table 2). These gains translate directly into faster time-to-train for large-scale models.
GPU memory savings and better scalability
Using lower bit-width formats reduces the memory footprint of weights and activations, allowing larger models or batch sizes on the same hardware. NVFP4 efficiency enables the micro-batch size to double (from 2 to 4) during pretraining, directly improving throughput and scalability.
Table 3 provides a detailed breakdown of memory usage across training components. Lower-precision formats significantly reduce parameter and activation storage while preserving FP32 optimizer state, enabling higher throughput and larger batch sizes without compromising training stability.
| Optimizer | ||||||
| Precision | Parameter | Gradients | Momentum | Variance | Master parameter | Others |
| FP16 | FP16 | FP32 | FP32 | FP32 | FP32 | |
| BF16 | BF16 | BF16 | ||||
| FP8 (tensor scaling) | FP8x2 | BF16 | Scaling factor per weight tensor | |||
| MXFP8 | FP8x2 | BF16 | (Scaling factor per 32 elements) x 2 | |||
| NVFP4 | FP4 | BF16 | 16×16 2D block scales replicated for each 1×16 block | |||
Low-precision training with NeMo Megatron Bridge
NeMo Megatron Bridge is an open PyTorch-native library within the NVIDIA NeMo framework. It bi-directionally connects Hugging Face and Megatron Core model checkpoints. It provides optimized training and multi-node parallelisms required to pretrain, SFT, and LoRA-tune generative AI models at maximum throughput.
Adopting low-precision training using the NeMo Megatron Bridge library is straightforward. You can use ready-to-use low-precision recipes for various models to experiment with different precision formats by changing a single configuration flag. An example for Llama 3 8B is shown below:
from megatron.bridge.recipes.llama import llama3_8b_low_precision_pretrain_config as low_precision_pretrain_config
from megatron.bridge.training.gpt_step import forward_step
precision = "bf16_with_fp8_current_scaling_mixed" # should be one of ["bf16_with_mxfp8_mixed", "bf16_with_fp8_current_scaling_mixed", "bf16_with_nvfp4_mixed"]
cfg = low_precision_pretrain_config(
mixed_precision_recipe = precision,
train_iters = 100,
lr_warmup_iters = 10,
lr_decay_iters = 90,
mock = True, # use mock dataset
)
pretrain(config=cfg, forward_step_func=forward_step)
You can easily switch between precision formats to evaluate performance, memory savings, and convergence behavior—without modifying model code or optimizer logic.
Train faster and scale efficiently
Low-precision training formats like FP8 with current scaling, MXFP8, and NVFP4 offer exciting new avenues for faster, more efficient deep learning training compared to the widely adopted BF16. Their advantages in speed and memory savings open doors for training larger, more complex models. Empirical evidence from Llama 3 8B and internal research models confirms that training with low precision matches BF16 performance on both pretraining metrics and downstream tasks.
Get started with low-precision training
As model sizes continue to scale, low-precision training will be foundational to building the next generation of models. With native NVIDIA Blackwell GPU support and production-ready low-precision recipes in NeMo Megatron Bridge, you can try these techniques today.
To get started quickly, try the Megatron Bridge Training Tutorial notebook. It walks through using these low-precision recipes end to end and demonstrates how they can significantly accelerate training workloads.