Deep learning (DL) is the state-of-the-art solution for many machine learning problems, such as computer vision or natural language problems and it outperforms alternative methods. Recent trends include applying DL techniques to recommendation engines. Many large companies—such as AirBnB, Facebook, Google, Home Depot, LinkedIn, and Pinterest—share their experience in using DL for recommender systems.
Recently, NVIDIA and the RAPIDS.AI team won three competitions with DL: the ACM RecSys2021 Challenge, SIGIR eCom Data Challenge, and ACM WSDM2021 Booking.com Challenge.
The field of recommender systems is complex. In this post, I focus on the neural network architecture and its components, such as embedding and fully connected layers, recurrent neural network cells (LSTM or GRU), and transformer blocks. I discuss popular network architectures, such as Google’s Wide & Deep and Facebook’s Deep Learning Recommender Model (DLRM).
Benefits of DL recommender systems
There are many different techniques to design a recommender system, such as association rules, content-based or collaborative filtering, matrix factorization, or training a linear or tree-based model to predict the interaction likelihood.
What are the advantages of using neural networks? In general, DL models achieve higher accuracy. First, DL can leverage additional data. Many traditional machine-learning techniques plateau with more data. However, when you increase the capacity of neural networks, the model can improve performance with more data.
Second, neural networks are flexible in their design. For example, you can train a DL model on multiple objectives (multitask learning), such as “will the user add the item to the cart?”, “start the checkout with the item?”, or “purchase the item?” Each goal helps the model to extract information from the data and the goals can support each other.
Other design approaches include adding multimodal data to the recommender model. You can do this by processing product images with a convolutional neural network or product description with an NLP model. Neural networks are used in many domains. You can transfer new developments, such as optimizers or new layers, to recommender systems.
Finally, DL frameworks are highly optimized to process terabytes to petabytes of data for all kinds of domains. Here’s how you can design neural networks for recommender systems.
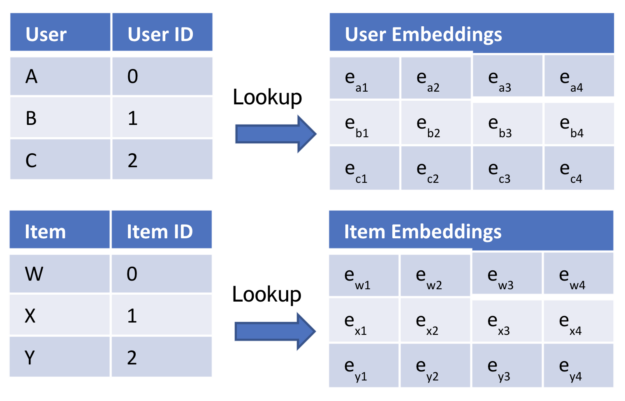
Basic building block: Embedding layers
Embedding layers represent categories with dense vectors. This technique is popular in NLP to embed words with dense representation. Words with similar meaning have a similar embedding vector.
You can apply the same technique to recommender systems. The most trivial recommender system is based on users and items: Which items should you recommend to a user? You have user IDs and item IDs. The words are the users and items, so you use two embedding tables (Figure 1).
Calculate the dot-product between the user embedding and the item embedding to get a final score, the likelihood that a user interacts with an item. You may apply the sigmoid activation function as a last step to transform the output to a probability between 0 and 1.
\(dot product: u \cdot v = \Sigma a_i \cdot b_i\)
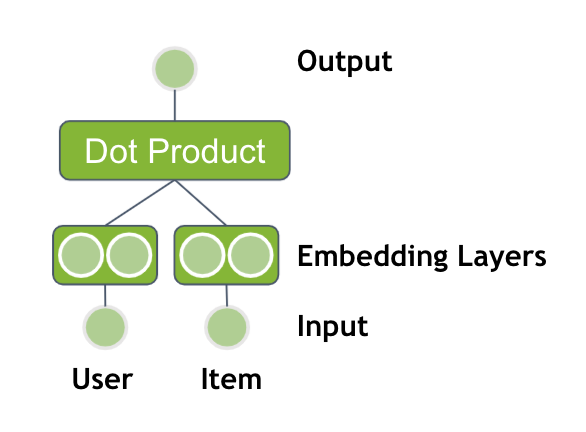
This method is equivalent to matrix factorization or alternating least squares (ALS).
Deeper models with fully connected layers
The performance of neural networks is based on deep architectures with multiple, nonlinear layers. You can extend the previous model by feeding the output of your embedding layers through multiple, fully connected layers with ReLU activations.
A design choice is how to combine the two embedding vectors. Either you can concatenate only the embedding vectors or you can multiply the vectors element-wise with each other, similar to a dot product. The output is followed by multiple hidden layers.
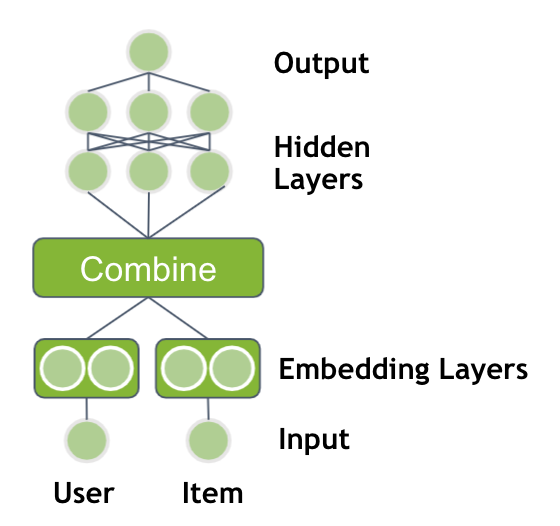
Adding metadata information to the neural network
So far, you’ve used only the user ID and product ID as an input, but you often have more information available. Additional user information could be gender, age, city (address), time since last visit, or credit card used for payment. An item usually has a brand, price, categories, or quantity sold in the last 7 days. This side information can help the model to generalize better. Modify the neural network to use the additional features as input.
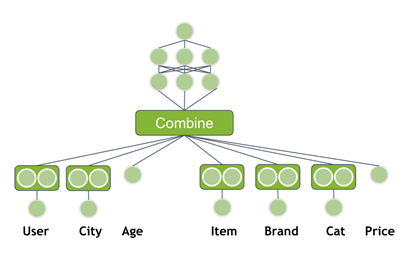
Popular architectures
Embedding layers and fully connected layers are the main components to understand some of the latest published neural network architectures. In this post, I cover Google’s Wide and Deep from 2016 and Facebook’s DLRM from 2019.
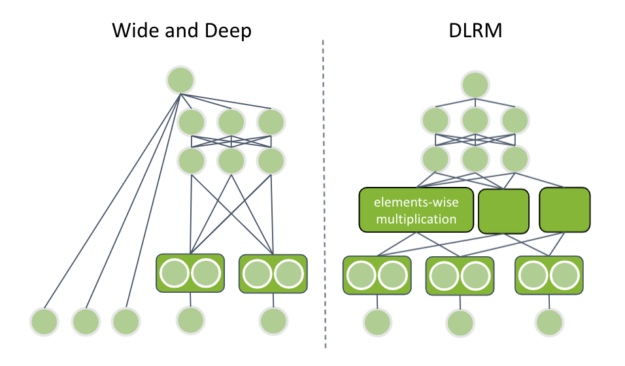
Google’s Wide and Deep
Google’s Wide and Deep contains two components:
- A wide tower to memorize common feature combinations
- A deep tower to generalize rare or unobserved feature combinations
The innovation is that both components are trained simultaneously, which is possible as neural networks are flexible. The deep tower feeds categorical features through embedding layers and concatenates the output with numerical input features. The concatenated vector is fed through multiple fully connected layers.
Does that sound familiar to you? Yes, that is your previous neural network design. The new component is the wide tower, which is just a linear combination of the input features, with a similar linear/logistic regression. The output of each tower is summed for the final prediction value.
Facebook’s DLRM
Facebook’s DLRM has a similar structure to the neural network architecture with metadata but has some specific differences. The dataset can contain multiple categorical features. DLRM requires that all categorical inputs are fed through an embedding layer with the same dimensionality. Later, I discuss why this is important.
Next, the continuous inputs are concatenated and fed through multiple, fully connected layers, called bottom multilayer perceptron (MLP). The final layer of the bottom MLP has the same dimensionality as the embedding layer vectors.
DLRM uses a new combination layer. It applies element-wise multiplication between all pairs of embedding vectors and bottom MLP output. That is the reason each vector has the same dimensionality. The resulting vectors are concatenated and fed through another set of fully connected layers (top MLP).
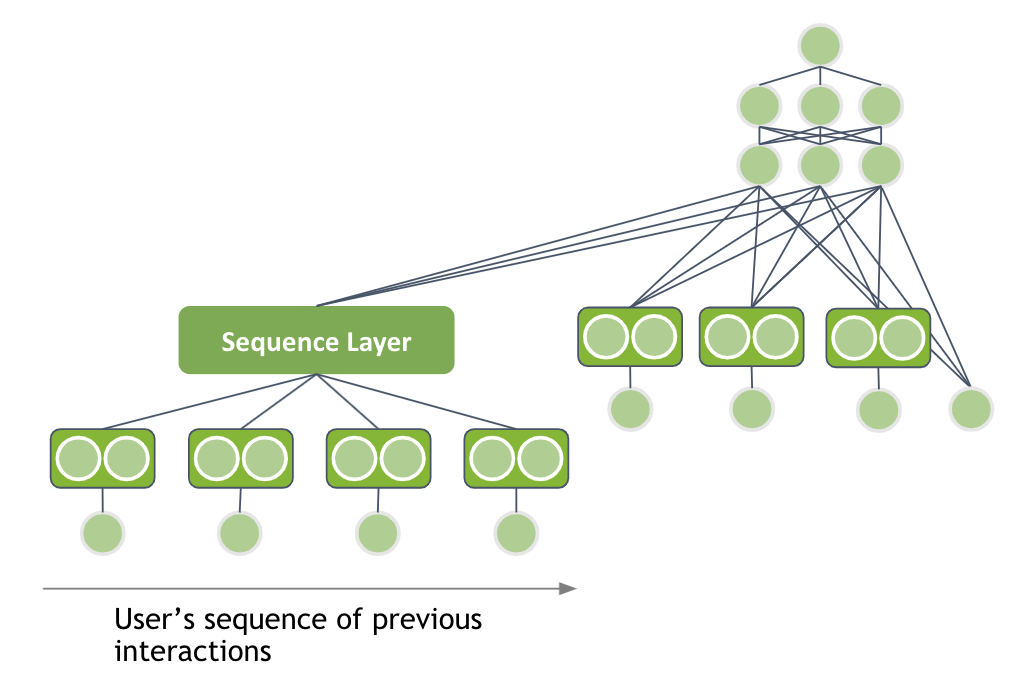
Session-based recommender systems
When I analyzed different DL-based architectures for recommender systems, I assumed that the input has a tabular data structure and ignored the nature of user interactions. However, a user has multiple interactions in one session when they visit the website. For example, they visit a shop and view multiple product pages. Can you use the sequence of user interactions as an input to extract patterns?
In one session, the user views multiple pairs of jeans in a row and you should recommend another pair of jeans. In another session, the same user views multiple pairs of shoes in a row and you should recommend another pair of shoes. That is the intuition behind session-based recommender systems.
Thankfully, you can apply some techniques from NLP to the recommender system domain. The user’s interactions have a sequential structure.
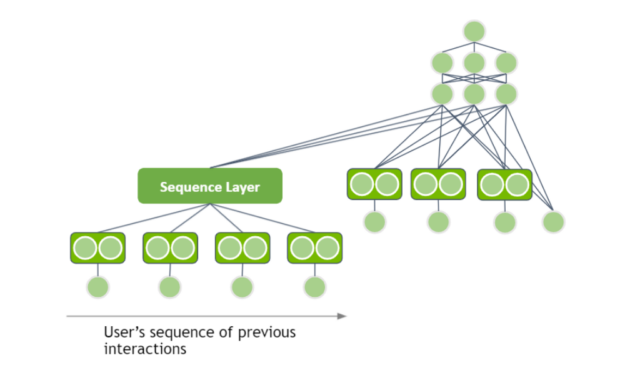
The sequence can be processed by using either a recurrent neural network (RNN) or transformer-based architecture as the Sequence Layer. You represent the item IDs with embedding vectors and feed the output through your sequence layer. The hidden representation of the sequence layer can be added as an input to your deep learning architecture.
Other options
As I focused this post on the theory of applying DL to recommender systems, I didn’t cover many other challenges. I briefly describe them here to provide a starting point:
- Embedding tables can exceed CPU or GPU memory. As an online service can have millions of users, the embedding table can reach up to multiple terabytes. NVIDIA provides the HugeCTR framework to scale embedding tables beyond CPU or GPU memory.
- Maximize GPU utilization during training. DL-based recommender systems have a shallow network architecture with only a few, fully connected layers. The data loader is sometimes the bottleneck in training pipelines. To counteract this, NVIDIA developed a highly optimized GPU data loader for TensorFlow and PyTorch.
- Generating recommendations requires you to score user-item pairs. The worst-case scenario is to predict, for all available products, the probability and select the top ones. In practice, that isn’t feasible and candidates are generated with a low-overhead model, such as approximate nearest neighbors.
Summary
This post introduced you to DL-based recommender systems. I started with basic matrix factorization based on two inputs and went over the latest session-based architecture using transformer layers.
You can process the sequence by using either a recurrent neural network (RNN) or transformer-based architecture as the sequence layer. Represent the item IDs with embedding vectors and feed the output through the sequence layer. Add the hidden representation of the sequence layer as an input to your DL architecture.
Interested in learning more about recommender systems? NVIDIA Merlin is an open-source framework to accelerate recommender systems end-to-end on the GPU. NVIDIA continuously develop more resources to train and deploy DL-based recommender systems easily. Here are some resources to help:
- Examples in the NVIDIA/NVTabular GitHub repo
- Deep Learning Recommender Summit on July 29, where NVIDIA and guest speakers will talk about their experience in deploying recommender systems and overcoming challenges
