Have you ever wanted to build your own reasoning models such as the open NVIDIA Nemotron, but thought it was too complicated or required massive resources? Think again. With NVIDIA’s powerful tools and datasets, you can train a small, effective reasoning model in about 48 hours, all on a single GPU. Even better, we’ve made all the code available to you to get started right away.
Let’s dive in.
Quick links to dataset and codes
- Hugging Face: Llama Nemotron Post-Training Dataset
- GitHub: Data Curation Code with NVIDIA NeMo Curator
- GitHub: Training and Evalulation Code with NVIDIA NeMo Framework
Prerequisites
- NVIDIA Ampere GPU or newer with at least 80GB memory (with Compute Capability >= 8.0)
- This tutorial has been tested on 1xA100 (80GB), and 1xH100 (80GB)
- 250 GB of disk space (for dataset download, docker images and training checkpoints).
- A valid Hugging Face API token with access to Meta Llama 3.1 8B Instruct
Video walkthrough
Click here to watch the video tutorial on YouTube.
Reasoning models and test-time computation
The advent of reasoning (or thinking) language models is transformative. By leveraging test-time computation scaling laws, more time is spent on generating tokens and internally reasoning about various aspects of the problem before producing the final answer. This makes them exceptionally skilled at tasks demanding deep critical thinking and reasoning, such as math and coding. This advancement signifies a paradigm shift in how language models are trained and used in various settings.
NVIDIA stands at the forefront of this advancement with its introduction of the NVIDIA Nemotron, a family of, of most open and efficient models that think fast and deliver highest accuracy for agentic AI.
Nemotron models are trained with open training data and AI techniques —giving full visibility, enabling better compliance, and ensuring trustworthy AI deployment.
To learn more about Nemotron models, check out this blog post. The principles discussed in this blog also apply to other leading models such as ServiceNow’s Apriel Nemotron 15B, highlighting the broader relevance of reasoning models in enterprise problem domains. To learn more about this model, check out this blog post.
From “reasoning off” to “reasoning on”: controllable reasoning modes
A key innovation of the open Llama Nemotron models is their dynamic reasoning toggle, which allows users to switch between standard chat (“reasoning off”) and advanced reasoning (“reasoning on”) modes during inference via a simple instruction in the system prompt. This flexibility allows for optimized resource utilization: engaging deep reasoning capabilities for complex tasks like scientific analysis or coding, while reverting to a lightweight mode for simpler interactions for reduced latency and computational costs.
Our open post-training dataset for reasoning
To empower the developer community, NVIDIA has open-sourced a substantial portion of the data that was used in the post-training pipeline of the Llama Nemotron models. The Llama Nemotron Post-Training Dataset, containing over 32 million samples across areas such as math, coding, chat, and sciences, provides a foundation for practitioners to train their own reasoning models. This dataset is key to teaching your model how to control its reasoning mode, mirroring Llama Nemotron capabilities.
In this blog post, we’ll explore how you can leverage the Llama Nemotron Post-Training Dataset, NVIDIA NeMo Curator, and NVIDIA NeMo Framework to train your own reasoning language model over a weekend.
The anatomy of the Llama Nemotron Post-Training dataset
The Llama Nemotron Post-Training Dataset is meticulously synthesized to enhance the reasoning capabilities of LLMs. Organized into distinct subsets for supervised fine-tuning (SFT) or reinforcement learning (RL), it encompasses samples from various problem domains. The following is a breakdown of the samples across different domains at the time of this writing.
| Category | Sample Count |
| Math | 22,066,397 |
| Coding | 10,108,883 |
| Science | 708,920 |
| Instruction Following | 56,339 |
| Chat | 39,792 |
| Safety | 31,426 |
| Total Samples | 32,011,757 |
All samples in this dataset are in JSON lines (JSONL) format and contain metadata such as license type, source model, as well as the Llama Nemotron model(s) trained with that sample. Each sample consists of a prompt, along with an expected response with detailed chain-of-thought (CoT) reasoning traces followed by responses (i.e., “reasoning on”), as well as samples with direct responses (i.e., “reasoning off”). More concretely, each sample has the following attributes:
input: the prompt(s) to the model in the multi-turn chat completions message format. It always starts with a message with the roleuser, followed by zero or more turns, and ending with a message with the roleassistant, such as:
[
{"role": "user", "content": "Can you help me understand the Pythagorean theorem?"},
{"role": "assistant", "content": "The Pythagorean theorem states that... Does that make sense?"},
{"role": "user", "content": "Yes, but I have a follow up question..."},
#
# ... (zero or more messages),
#
{"role": "assistant", "content": "Sure, happy to help!"},
]
output: the expected response from the model (ground truth), such as:
The Pythagorean theorem states that in a right triangle, the square of the hypotenuse equals the sum of the squares of the other two sides: a² + b² = c².
reasoning: whether the sample is for reasoning “on” mode or not.- If the value is “
on”, then the output contains a detailed CoT trace encoded inside<think></think>followed by the output, such as:
- If the value is “
<think>
Hmm so the user is asking about the Pythagorean theorem. If I remember correctly...
</think>
The Pythagorean theorem states that in a right triangle, the square of the hypotenuse equals the sum of the squares of the other two sides: a² + b² = c².
- If the value is “
off”, then the output doesn’t contain any reasoning traces and instead contains a direct response.
system_prompt: the (suggested) system prompt to control the reasoning mode of the system. For Llama Nemotron training, the system prompt is always either “detailed thinking on“ or “detailed thinking off“. Needless to say, this field is tied to the value in the field “reasoning” (and vice versa).category: the sample category, such as math, coding, science, instruction following, chat or safety.license: the license associated with that sample.generator: the generator model used to synthesize the sample, such as DeepSeek-R1, etc.used_in_training: the list of Llama Nemotron models that used this sample for training. For instance, a value of[“Ultra”, “Nano”]indicates that this sample was used for training Llama Nemotron Nano and Ultra, but not Super.version: a version tag associated with each sample. Since new samples are added to this dataset over time, this version tag helps identify when a particular sample was added.
From zero to reasoning in 3 easy steps
Let’s go over a training and data curation recipe that we used to train a small reasoning model. We leverage the Llama Nemotron Post-Training dataset, enabling your model to learn controllable reasoning similar to what we described above.
Training your own reasoning model typically involves data curation, fine-tuning, and evaluation. In this section, we cover a proven recipe that lets you train a model on a single GPU in just 48 hours. Note that our recipe uses supervised fine-tuning (SFT) to instill reasoning capabilities. While reinforcement learning (RL) is also an option, recent work suggests that a multi-pass approach (i.e. SFT followed by RL) yields the best results.
Things to consider
- Dataset composition: The Llama Nemotron Post-Training dataset is large, so you’ll need to curate a focused subset emphasizing reasoning. For real-world use, prioritize samples that align closely with your domain-specific tasks, and consider augmenting with your own domain-specific samples.
- Base model selection: Given the time and computational constraints, teaching small models to reason is challenging, so the base model choice is critical. We recommend starting with models of at least 8B parameters. We used Llama 3.1 8B Instruct, which worked well.
- Fine-tuning technique: Fully fine-tuning all the weights of an 8-billion parameter model requires at least 8 GPUs, aggressive memory optimization techniques, and a lot of time! However, we’ve observed comparable results with parameter efficient fine-tuning (PEFT) using LoRA adapters. In fact, you can fine-tune a LoRA adapter for an 8-billion parameter model on a single NVIDIA H100 GPU in 48 hours.
- Evaluation: Post fine-tuning, evaluate your model using standard benchmarks, and compare its performance to the original base model to assess improvement.
Step 1: Processing data with NVIDIA NeMo Curator
High-quality data is the bedrock of a powerful reasoning model. There are many ways to subset the Llama Nemotron Post-Training dataset, but we recommend starting with the math and chat subsets because they contain strong examples of domain-agnostic reasoning.
To get good results, we recommend a data processing pipeline with at least 500,000 samples and a balanced mix of “reasoning on” and “reasoning off” examples. Here’s a recommended filtering and processing approach:
- Select the appropriate small subset
- Use Llama Nemotron Nano samples: Start with these high-quality, pre-vetted samples used in Llama Nemotron Nano training.
- Select key subsets: Select only the
math_v1.1andchatsubsets for strong, domain agnostic reasoning. - Filter by language: Remove all non-English samples by language identification to ensure dataset consistency.
- Filter samples
- Enforce answer format: Discard math samples that don’t have final answers in the LaTeX
\boxed{}format. - Exclude refusal samples: Exclude samples with thinking mode enabled but empty
<think></think>tags. These are often refusal samples which are necessary for additional safety training, but we can discard them for simplicity. - Restrict sample length: Filter out samples longer than a fixed token limit (e.g. 8k or 16k, after applying the tokenizer’s chat template).
- Enforce answer format: Discard math samples that don’t have final answers in the LaTeX
- Apply a chat template: Format all training samples using a consistent chat-style template (e.g., system/user/assistant roles). This is required for instruction-following models that were trained with chat templates, and helps the model generalize better to downstream chat interfaces.
- Reasoning mode via system prompt: Add control statements to the system prompt to signal whether reasoning should be enabled. Llama Nemotron models use phrases like “
detailed thinking on” or “detailed thinking off” to control this behavior.
- Utilize curriculum learning: Sort samples in the increasing order of difficulty. You can use the completion token count as a measure of sample difficulty. Feel free to experiment with different schemes.
- Split your data into “reasoning on” and “reasoning off” buckets.
- Sort each bucket by increasing completion length (as a proxy for difficulty)
- Interleave samples from each bucket to gradually introduce complexity.
You can use the NVIDIA NeMo Curator, part of the NVIDIA NeMo software suite for managing the AI agent lifecycle, to implement this pipeline efficiently. We’ve released a simple, easy-to-understand pipeline on GitHub to help you get started. It runs locally on modest hardware, even without a GPU. Check out the code here.
The NeMo Curator pipeline demonstrates various facilities available in the framework (such as language identification and distributed processing) to quickly process a subset of Llama Nemotron Post-Training dataset for fine-tuning. You can easily modify this pipeline as you see fit and adapt it to your domain- or business-specific needs.
Here are some commands to get you started, based on our recommendations provided above.
Obtain the dataset from Hugging Face (requires ~130GB of disk space):
$ git lfs install
$ git clone https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset
Obtain the FastText language identification model:
$ wget https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.ftz -P ./
Launch the data curation pipeline with 8 workers:
$ python main.py \
--input-dir "/path/to/Llama-Nemotron-Post-Training-Dataset/SFT" \
--remove-columns "version" "license" "generator" "category" "used_in_training" "system_prompt" "reasoning" \
--filename-filter "chat" "math_v1.1" \
--tokenizer "meta-llama/Llama-3.1-8B-Instruct" \
--lang-id-model-path "/path/to/lid.176.ftz" \
--max-token-count 8192 \
--max-completion-token-count 16384 \
--output-dir "/path/to/curated-data" \
--json-blocksize "100mb" \
--n-workers 8 \
--device "cpu"
Once the above pipeline finishes execution, the curated dataset will be written to the specified output path. The output will be written in the form of multiple JSONL files. This is because the large input dataset is divided into smaller partitions so that each partition can be processed in parallel.
Each JSONL file is in the input/output format. For every record in each file, the input field contains the model inputs, i.e., system prompt and user messages (after undergoing chat template transformation with the specified tokenizer), and the output field contains the expected response from the model, including any special tokens added by the tokenizer’s chat template (e.g., end of turn or end of sentence tokens).
To combine all the different partitions into a single JSONL file, run the following command:
$ find /path/to/curated-data -type f -name "*.jsonl" -size +0c -print0 | xargs -0 cat | awk 'NF' > training.jsonl
This will create a single JSONL file called training.jsonl with around 1.7 million samples. You can directly use this resulting file with NVIDIA NeMo Framework, also part of the NVIDIA NeMo software suite for managing the AI agent lifecycle, training scripts without modification.
Step 2: Training
We experimented with base models ranging from 3B to 8B parameters and LoRA ranks from 16 to 128. The smallest model that consistently produced strong reasoning performance was Llama 3.1 8B Instruct, with LoRA rank 64 as the sweet spot.
A few key factors contributed to successful training:
- High learning rate to accelerate convergence.
- Curriculum learning, using progressively harder samples, significantly improved stability and final performance.
- Batch size of at least 256.
Full training hyperparameters are listed in the table below:
| Hyperparameter | Value |
| LoRA | |
| Rank | 64 |
| Alpha | 128 |
| Learning Rate | 0.0001 |
| Scheduler | Cosine |
| Warmup steps | 5% of total training steps |
| Weight decay | 0.001 |
| Batch Size | 256 (w/ gradient accumulation) |
| Steps to train for | At least 2,000 steps |
We trained the model on a single NVIDIA H100 80GB GPU for around 30 hours. Notably, consistent reasoning behavior emerged after just ~13 hours of training (after stepping through ~100,000 to 130,000 samples).
If you have a GPU with lower than 80GB memory, you can reduce the (on device) batch size and increase the gradient accumulation steps to maintain a larger effective batch size while still being able to train with lower memory capacity.
We’ve prepared a Jupyter notebook for you on GitHub that sets up the aforementioned training pipeline with appropriate hyperparameters using NVIDIA NeMo Framework. This notebook walks you through various settings that are available to you for fine-tuning your own model. Moreover, this notebook provides an option for you to perform full model fine-tuning instead of PEFT, should you choose to do so.
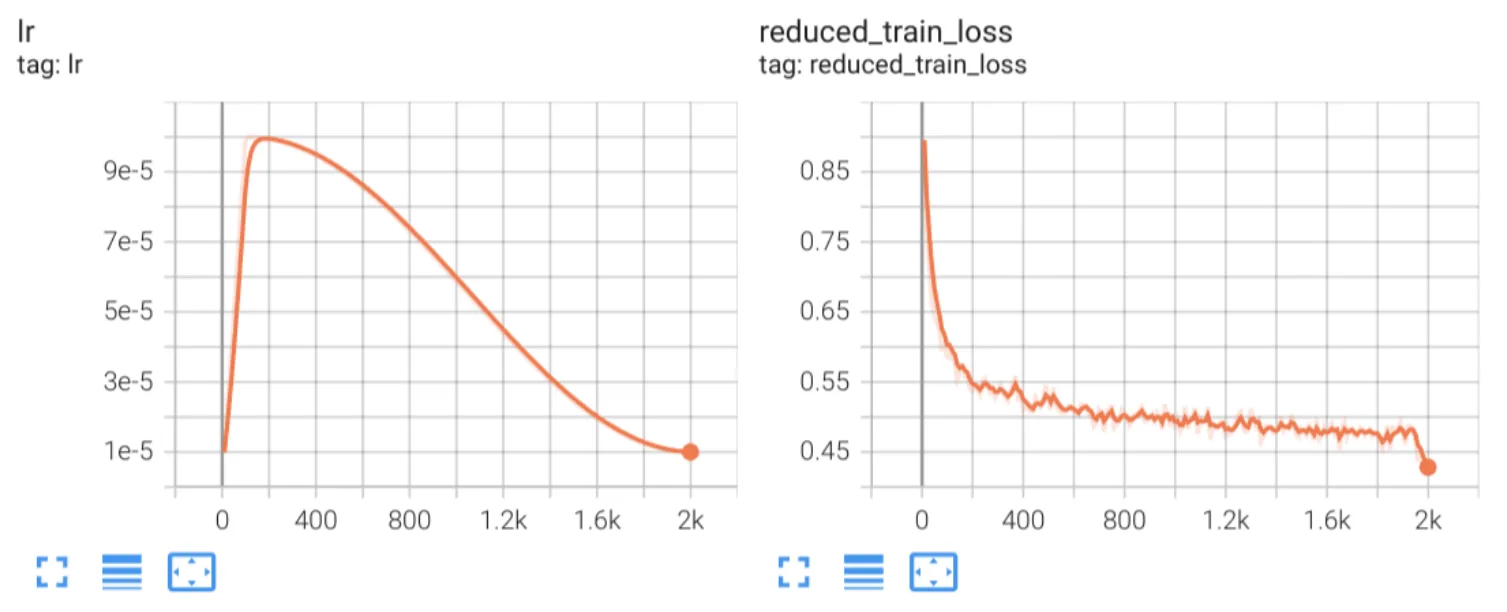
For your reference, here are the loss plots from our own experiments to fine-tune a LoRA adapter of rank 64, using the first 500,000 training samples from the filtering and data curation pipeline, with a batch size of 256 and 2,000 training steps.
You might be wondering about the sudden loss drop at the end. This is expected. Recall that our curated dataset is arranged in the increasing order of sample difficulty for curriculum learning. With 500,000 training samples, a batch size of 256 and 2,000 steps, that’s just slightly over 1 epoch of training. Towards the end of that epoch, when the model sees the first few (easier samples) again, it can easily predict the correct tokens for them so the loss value ends up being much lower.
Step 3: Evaluation
After training, it’s essential to evaluate the model to confirm that reasoning capabilities have been learned. We recommend:
- Benchmarking against the base model: Run side-by-side comparisons on reasoning-heavy tasks to assess improvement.
- Standard and domain-specific benchmarks:
- Evaluate on datasets like MMLU, GPQA Diamond, GPQA Main, or OpenBookQA to get a sense of the model’s overall capabilities.
- Evaluate on domain-specific data, to get clear insight into the model’s behavior in production.
- Manual inspection: Sample outputs for both “reasoning on” and “reasoning off” modes to verify controllability and consistency. Just ensure that the chat templates and the system prompts are set up correctly.
Let’s dive deeper into the above three recommendations and see how our trained model performs.
We’ve prepared a set of scripts to benchmark your trained model against the base model on GPQA Diamond, GPQA Main, and MMLU datasets. Check out these scripts here, which can be expanded to incorporate other benchmarking datasets. These scripts demonstrate dataset download and preparation, model deployment, and running the relevant benchmarks.
The first step of the evaluation is to prepare the dataset for model evaluation. We download the MMLU, GPQA Diamond, and GPQA main datasets from Hugging Face and preprocess the data to rearrange it as question, choices, and the correct answer as one of the multiple-choice options (“A”, “B”, “C”, “D”).
Next, we will deploy and evaluate our trained adapter as well as the base. In this step we will start a server and deploy the model using Triton Inference Server, which provides OpenAI APIs endpoints. The /v1/chat/completions/ endpoint allows for multi-turn conversational interactions with the model. This endpoint accepts a structured list of messages with different roles (system, user, assistant) to maintain context and generate chat-like responses. Under the hood, a chat template is applied to turn the conversation into a single input string.
In order to deploy the trained model using “detailed thinking on”, we can use the following chat template:
chat_payload = {
"messages": [{"role": "system", "content": "detailed thinking on"}, {"role": "user", "content": prompt}],
"model": model_name,
"max_tokens": 20000,
}
Similarly for “detailed thinking off” mode, you can use the following chat template:
chat_payload = {
"messages": [{"role": "system", "content": "detailed thinking off"}, {"role": "user", "content": prompt}],
"model": model_name,
"max_tokens": 20000,
}
The max_tokens takes into consideration tokens needed for the input, system prompt, and the response form model.
Lastly, we compare the ground truth responses and model responses generated in the previous step by performing extraction of the final answer to calculate the accuracy.
Based on the above described process, we observed the following evaluation results when we compared the base model versus the trained adapter:
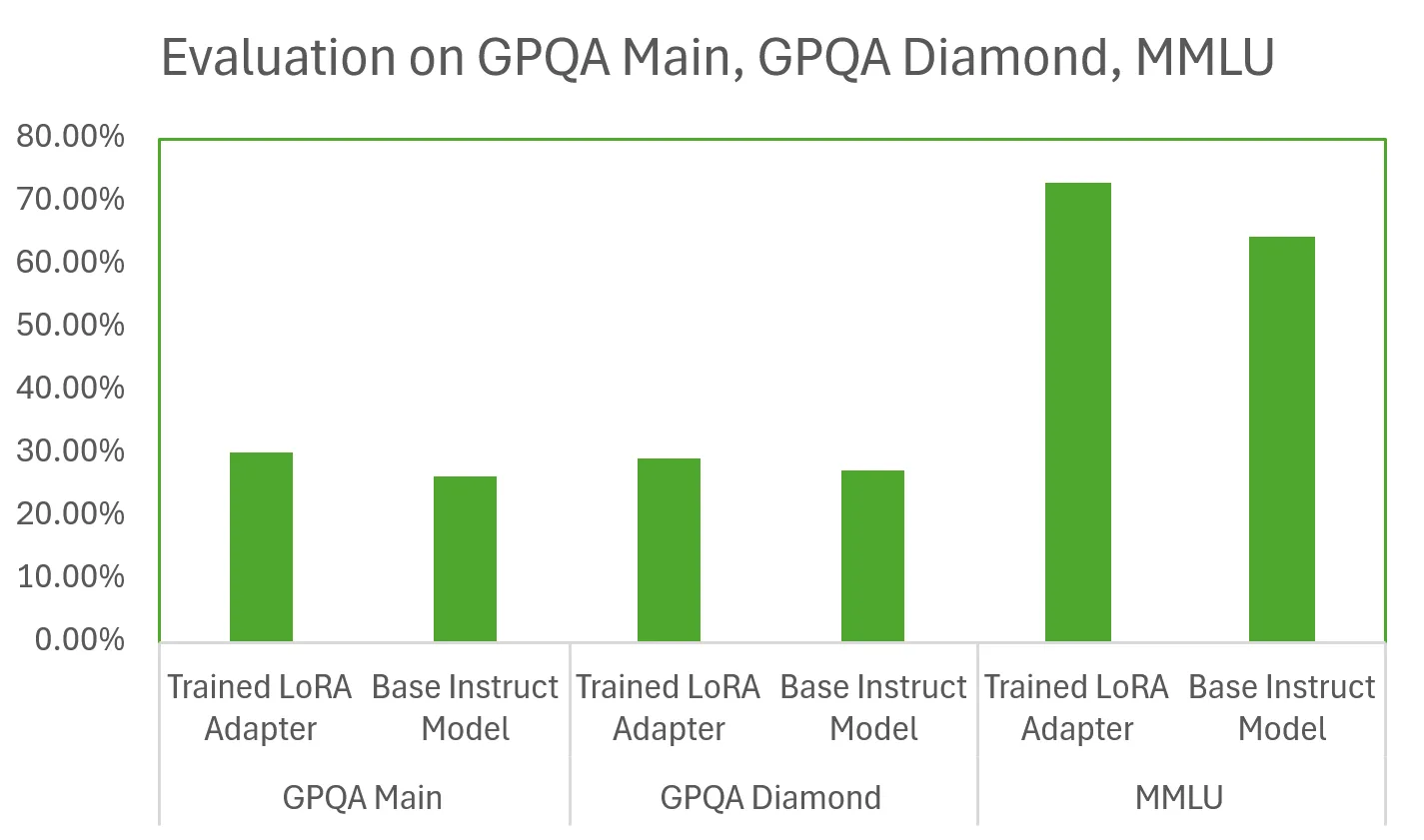
These results show that our trained LoRA adapter outperforms the base instruct model on various benchmarks, sometimes by as much as 10 points. These results are significant because our model was only trained for 48 hours on a relatively small number of training samples using a single GPU. LLM scaling laws predict that by increasing the number of training samples and the allotted training time, we could train even stronger reasoning models.
If you prefer using a microservice instead of a framework to streamline your evaluation, check out the NVIDIA NeMo Evaluator microservice, part of the NVIDIA NeMo software suite for managing the AI agent lifecycle. NeMo Evaluator simplifies the end-to-end evaluation of generative AI applications and provides LLM-as-a-judge capabilities, along with a comprehensive suite of benchmarks and metrics for a wide range of custom tasks and domains, including reasoning, coding, and instruction-following.
Conclusion and next steps
In this blog, we described a simple and computationally efficient recipe for training reasoning models with small amounts of training data curated based on the Llama Nemotron Post-Training Dataset. We discussed a strategy based on LoRA adapter training and highlighted the key considerations and hyperparameters for successfully teaching a small language model to reason in 48 hours. Through evaluations, we demonstrated that our trained LoRA adapter significantly outperforms the base instruct model on GPQA and MMLU datasets.
Since our model was only trained on math and chat data, its reasoning abilities will be generic. By introducing domain-specific data, you can train models that are proficient in the problem domain that is relevant to your application or business needs.
To train your own reasoning models or replicate this tutorial, click the following links:
- Hugging Face: Llama Nemotron Post-Training Dataset
- GitHub: Data Curation Code with NVIDIA NeMo Curator
- GitHub: Training and Evalulation Code with NVIDIA NeMo Framework
From here, you can scale this weekend recipe to any model of your choice. Visit GitHub for our Nemotron cookbook recipes and tutorials.
Learn more about NVIDIA Nemotron
Stay up-to-date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, Discord, and YouTube.
- Visit our Nemotron developer page for all the essentials you need to get started with the most open, smartest-per-compute reasoning model.
- Explore new open Nemotron models and datasets on Hugging Face and NIM microservices and Blueprints on build.nvidia.com.
- Share your ideas and vote on features to help shape the future of Nemotron.
- Tune into upcoming Nemotron livestreams and connect with the NVIDIA Developer community through the Nemotron developer forum and the Nemotron channel on Discord.
- Browse video tutorials and livestreams to get the most out of NVIDIA Nemotron.
Acknowledgement
We would like to acknowledge Christian Munley for his valuable assistance in this work.