
Domain-adaptive pretraining (DAPT) of large language models (LLMs) is an important step towards building domain-specific models. These models demonstrate greater capabilities in domain-specific tasks compared to their off-the-shelf open or commercial counterparts.
Recently, NVIDIA published a paper about ChipNeMo, a family of foundation models that are geared toward industrial chip design applications. ChipNeMo models are the result of the continued pretraining of the Llama 2 family of models on a corpus of proprietary, as well as publicly available domain-specific data.
This post walks you through the process of curating a training dataset, using ChipNeMo dataset as an example, from a variety of publicly available sources using NVIDIA NeMo Curator.
NeMo Curator
NeMo Curator is a GPU-accelerated data-curation library that improves generative AI model performance by preparing large-scale, high-quality datasets for pretraining and customization.
NeMo Curator lowers the data processing time by scaling to multi-node multi-GPU (MNMG) and enables the preparation of large pretraining datasets. It offers workflows to download and curate data from various public sources out of the box such as Common Crawl, Wikipedia, and arXiv.
It also provides flexibility for you to customize data curation pipelines to address their unique requirements and create custom datasets.
For more information about the basic building blocks, see the Curating Custom Datasets for LLM Training with NVIDIA NeMo Curator tutorial.
ChipNeMo
A large portion of ChipNeMo’s training corpus consists of data from Wikipedia, open-source GitHub repositories as well as arXiv publications.
Figure 1 shows that the data curation pipeline involves the following high-level steps:
- Acquiring data:
- Download relevant Wikipedia articles and convert them to JSONL files.
- Clone relevant GitHub repositories, determine all relevant source code files, and convert them to JSONL files.
- Download papers from arXiv in PDF format and convert them into JSONL files.
- Using existing tools to unify the Unicode representation and special characters.
- Defining custom filters to remove too short, too long, duplicate, or irrelevant records.
- Redacting all personally identifiable information (PII) from the dataset.
- Organizing the data based on the metadata and writing the results to disk.
- (Optional) Blending and shuffling the data.
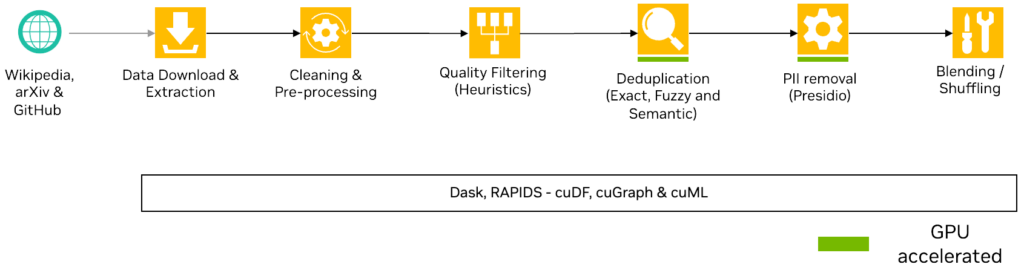
To access the complete code for this tutorial, see the /NVIDIA/NeMo-Curator GitHub repo.
Prerequisites
Before starting, install NeMo Curator by following the instructions in the NeMo Curator GitHub README file.
This tutorial also relies on the Tesseract library to enable PDF parsing functionality, which can be installed by obtaining the binaries, or your operating system’s package manager.
After that, run the following commands from the terminal to verify the installation. Also, install the dependencies needed for following along:
$ sudo apt install tesseract-ocr # For Debian-based Linux distros
$ pip install nemo-curator
$ python -c "import nemo_curator; print(nemo_curator);"
$ pip3 install -r requirements.txt
Data acquisition
We provide a list of Wikipedia articles, GitHub repositories, and arXiv publications used in the ChipNeMo training corpus, and demonstrate how to convert this data into JSONL.
The conversion process varies by data source:
- For Wikipedia articles, parse the web pages to extract the main content.
- For arXiv publications, parse the PDF files into plain text.
- For GitHub repositories, identify relevant source code files and ignore irrelevant data.
As discussed in our previous tutorial, the first step of curating a dataset is to implement the document builders that can download and iterate through the dataset.
To use Dask’s parallelism, plug the document builder implementations into the download_and_extract helper that NeMo Curator provides. This helper uses Dask workers to download and parse data in parallel, speeding up the process significantly when handling many data sources.
Document builder implementation
First, implement the DocumentDownloader class, which takes the dataset’s URL and downloads it using the requests library. For now, focus on the task of downloading and parsing GitHub repositories. You can similarly obtain Wikipedia and arXiv data later.
To efficiently obtain GitHub repositories, download them as .zip archives, rather than cloning them through git commands. This method is faster and conserves disk space as you can work directly with .zip files.
To download the .zip version of the repository, determine the name of the main branch for that repository. In a production pipeline, it is better to query the GitHub API directly and figure out the main branch for each repository. Because APIs are often subject to rate limits and require authentication, we show how to try a few different common branch names to see which works:
import requests
from nemo_curator.download.doc_builder import DocumentDownloader
class GitHubDownloader(DocumentDownloader):
"""
A class for downloading repositories from GitHub.
"""
def __init__(self, github_root_dir: str):
"""
Initializes the DocBuilder object.
Args:
github_root_dir: The root directory for GitHub repositories.
"""
super().__init__()
# The path under which the repositories will be cloned.
self.clone_root_dir = os.path.join(github_root_dir, "repos")
os.makedirs(github_root_dir, exist_ok=True)
os.makedirs(self.clone_root_dir, exist_ok=True)
def download(self, url: str) -> str:
"""
Download a repository as a zip file.
Args:
url (str): The URL of the repository.
Returns:
str: The path to the downloaded zip file, or None if the download failed.
"""
repo_name = os.path.basename(url)
zip_file = os.path.join(self.clone_root_dir, repo_name + ".zip")
if os.path.exists(zip_file):
print(f"Repository '{repo_name}' already exists, skipping download.")
return zip_file
# Try the common branch names first. A better way to do this would be to
# query the GitHub API to get the default branch, but that is subject to rate limits.
success = False
for branch in ["master", "main"]:
zip_url = f"https://github.com/{url}/archive/refs/heads/{branch}.zip"
# Send a GET request to the URL
response = requests.get(zip_url)
# Check if the request was successful
if response.status_code == 200:
# Write the content of the response to a file
with open(zip_file, "wb") as file:
file.write(response.content)
# No need to try other branches
success = True
break
if not success:
print(
f"Failed to clone repository '{repo_name}' from '{url}' (error code {response.status_code})."
)
return None
return zip_file
Parsing and iterating the dataset
Implement the DocumentIterator and DocumentExtractor classes to walk through the data sources and parse all relevant source files. In the iterator implementation, you can add any other relevant metadata or restrict the files that are parsed.
The following implementation opens each repository’s .zip file and walks through all the files, skipping over all hidden files and directories. It determines the relevant files by their extension and determines each file’s encoding using the cchardet library. In addition to the content of each file, this implementation stores some useful metadata and returns it to the caller.
The extractor implementation returns the parsed contents of the file.
import os
from zipfile import ZipFile, ZipInfo
import cchardet as chardet
from nemo_curator.download.doc_builder import DocumentIterator
class GitHubIterator(DocumentIterator):
"""
GitHub document iterator. Will go through the files and parse the supported ones.
"""
# Mapping from file extensions to categories.
# Will also be used to to ignore irrelevant files.
SUPPORTED_EXTENSIONS_TO_CATEGORY = {
".v": "VerilogVHDL",
".vh": "VerilogVHDL",
".vhdl": "VerilogVHDL",
".va": "VerilogAnalog",
".c": "CPP",
".cpp": "CPP",
".h": "CPP",
".hpp": "CPP",
".py": "Python",
".config": "Config",
".mk": "Makefile",
"makefile": "Makefile",
"makeppfile": "Makefile",
".pm": "Perl",
".pl": "Perl",
".tcl": "Tcl",
".spec": "Spec",
".yaml": "Yaml",
".yml": "Yaml",
".sp": "Spice",
".cir": "Spice",
".cmd": "Spice",
".spf": "Spice",
".spice": "Spice",
".txt": "text",
".json": "text",
".xml": "text",
".html": "text",
".pdf": "text",
".md": "text",
"": "text", # No extension
}
def parse_file(self, zip_ref: ZipFile, file_info: ZipInfo):
"""
Parses a file from a zip archive and extracts its metadata and content.
Args:
zip_ref: The zip archive object.
file_info: Information about the file in the zip archive.
Returns:
A tuple containing the metadata and the content of the file. The metadata is a dictionary.
If the file extension or filename is not supported, or if the file cannot be decoded,
None is returned.
"""
zip_path = zip_ref.filename
input_fp = file_info.filename
full_path = os.path.join(zip_path, input_fp)
# Extract the file name and extension in lower case.
filename = os.path.basename(input_fp)
filename_no_ext, ext = os.path.splitext(filename)
filename_no_ext = filename_no_ext.lower()
ext = ext.lower()
# If neither the file extension nor the filename is supported, return None
if ext not in GitHubIterator.SUPPORTED_EXTENSIONS_TO_CATEGORY:
if filename_no_ext not in GitHubIterator.SUPPORTED_EXTENSIONS_TO_CATEGORY:
return None
# The filename is there, but the extension is not. The category is determined by the filename.
category = GitHubIterator.SUPPORTED_EXTENSIONS_TO_CATEGORY[filename_no_ext]
else:
category = GitHubIterator.SUPPORTED_EXTENSIONS_TO_CATEGORY[ext]
# Open the file and read its content. Determine the encoding using cchardet. Skip over binary files.
with zip_ref.open(file_info, "r") as file:
content = file.read()
# Determine the encoding of the file
encoding = chardet.detect(content)["encoding"]
if not encoding:
return None
try:
content = content.decode(encoding)
except UnicodeDecodeError:
# If the file cannot be decoded, return None
return None
# Extract the metadata
line_count = content.count("\n") + 1
size_in_bytes = file_info.file_size
if category == "text":
file_type = "text"
else:
file_type = "code"
metadata = {
# Use the file path as the unique ID
"id": full_path,
"file_extension": ext,
"file_type": file_type,
"category": category,
"line_count": line_count,
"size_in_bytes": size_in_bytes,
"path": full_path,
}
return metadata, content
def iterate(self, file_path: str):
"""
Iterates over the files in a zip archive and yields the parsed content of each file.
Args:
file_path: The path to the zip archive.
Yields:
Parsed content of each file in the zip archive.
"""
if not file_path:
return
with ZipFile(file_path, "r") as zip_ref:
for file_info in zip_ref.infolist():
filename = file_info.filename
# Skip directories and hidden files
if file_info.is_dir() or any(
part.startswith(".") for part in filename.split(os.sep)
):
continue
parsed = self.parse_file(zip_ref, file_info)
if parsed:
yield parsed
class GitHubExtractor(DocumentExtractor):
def extract(self, content: str):
# Just return the content.
return {}, content
Downloading the dataset
Plug the implemented components above into NeMo Curator helpers to obtain the data from all available sources.
The following code example demonstrates this process for the GitHub repositories. The download_and_extract function takes a list of dataset sources and forwards them to the downloader. It then runs the iterator and extractor implementations on every downloaded source to obtain the parsed data.
The output_format dictionary serves to inform the underlying Dask modules about the type of each extracted field, which avoids the runtime penalty of type inference.
from nemo_curator.download.doc_builder import download_and_extract
downloader = GitHubDownloader(output_dir)
iterator = GitHubIterator()
extractor = GitHubExtractor()
output_format = {
"text": str,
"id": str,
"file_extension": str,
"category": str,
"line_count": int,
"size_in_bytes": int,
"path": str,
}
dataset = download_and_extract(
urls=urls,
output_paths=[
os.path.join(output_jsonl_dir, os.path.basename(url)) for url in urls
],
downloader=downloader,
iterator=iterator,
extractor=extractor,
output_format=output_format,
keep_raw_download=True,
)
The download_and_extract function expects an output path for every dataset source. This path is used to store the parsed dataset in the JSONL format, which obviates the need for downloading and extracting sources multiple times.
Upon completion, this function returns a DocumentDataset instance.
Loading the dataset using the document builders
In NeMo Curator, datasets are represented as objects of type DocumentDataset. This class provides helpers to load the datasets from disk in various formats. Having created the dataset in the JSONL format, you can use the following code to load it and start working with it:
from nemo_curator.datasets import DocumentDataset
# define `code_files` to be the path to the JSONL file created above.
dataset_code = DocumentDataset.read_json(code_files, add_filename=True)
# define `text_files` to be the path to the JSONL file created from text sources.
dataset_text = DocumentDataset.read_json(text_files, add_filename=True)
Considering that this data comes from different sources, it might be easier to store two separate dataset instances, one for data from text sources (for example, Wikipedia or arXiv papers), and another for data from code sources (such as GitHub repositories). This enables you to define source-specific processing pipelines, such as applying PII redaction on text sources, and license text removal for code sources.
You now have everything needed to define a custom dataset curation pipeline and prepare your data.
Unicode formatting and text unification
It is often a good practice to fix all Unicode issues in your datasets as text scraped from online sources may contain inconsistencies or Unicode issues.
To modify documents, NeMo Curator provides a DocumentModifier interface along with the Modify helper, which defines how the given text from each document should be modified. For more information about implementing your own custom document modifiers, see the Text cleaning and unification section in the Curating Custom Datasets for LLM Parameter-Efficient Fine-Tuning with NVIDIA NeMo Curator tutorial.
Here, it is sufficient to apply the NeMo Curator UnicodeReformatter modifier to your dataset.
Also, modify all the quotation marks in your dataset and ensure that there are no angled quotation variants. You can do this by implementing the DocumentModifier interface with the required logic.
Considering that each record has multiple fields, apply the operation only to the relevant field in the dataset (in this case, “text” ). Chain these operations together using the Sequential class:
Sequential([
Modify(QuotationUnifier(), text_field="text"),
Modify(UnicodeReformatter(), text_field="text"),
])
Dataset filtering
When all text in the dataset is unified, apply some filters to your dataset to ensure the documents meet certain criteria. For instance, they should all have reasonable lengths and be free of too many URLs or other repeated text.
NeMo Curator provides many such filters. You can also create your own custom filters by implementing the DocumentFilter interface. For more information, see the Designing custom dataset filters section in the Curating Custom Datasets for LLM Parameter-Efficient Fine-Tuning with NVIDIA NeMo Curator tutorial.
The following code example shows the chaining of various filters suitable for textual data.
def filter_text(dataset: DocumentDataset) -> DocumentDataset:
"""
Filters the given dataset based on various criteria.
Refer to the full list of all filters here:
https://github.com/NVIDIA/NeMo-Curator/blob/main/config/heuristic_filter_en.yaml
https://github.com/NVIDIA/NeMo-Curator/blob/main/tutorials/peft-curation/main.py
Args:
dataset (DocumentDataset): The dataset to be filtered.
Returns:
DocumentDataset: The filtered dataset.
"""
filters = Sequential(
[
# If a document contains a number of words not
# within a specified range then discard
ScoreFilter(
WordCountFilter(min_words=50, max_words=100000),
text_field="text",
score_field="word_count",
score_type=int,
),
# If the document shrinks by > x% in terms of number of characters after
# removing the top n-grams then discard. Source: Gopher (Rae et al., 2021)
ScoreFilter(
RepeatingTopNGramsFilter(n=2, max_repeating_ngram_ratio=0.2),
text_field="text",
score_type=float,
),
ScoreFilter(
RepeatingTopNGramsFilter(n=3, max_repeating_ngram_ratio=0.18),
text_field="text",
score_type=float,
),
ScoreFilter(
RepeatingTopNGramsFilter(n=4, max_repeating_ngram_ratio=0.16),
text_field="text",
score_type=float,
),
ScoreFilter(
RepeatedParagraphsFilter(max_repeated_paragraphs_ratio=0.7),
text_field="text",
score_type=float,
),
# If more than 20% of the document is comprised of URLs then discard
ScoreFilter(
UrlsFilter(max_url_to_text_ratio=0.2),
text_field="text",
score_type=float,
),
]
)
filtered_dataset = filters(dataset)
return filtered_dataset
PII redaction
Next, define a processing step to redact all PII from the records. Depending on the source of the data (text or code), ensure that the operation is applied to the appropriate dataset and the data field. Also, define the action to take when PII is detected.
The following code example defines two functions for PII redaction, for text sources and code sources, respectively.
def redact_pii(dataset: DocumentDataset) -> DocumentDataset:
redactor = Modify(
PiiModifier(
supported_entities=[
"PERSON",
"EMAIL_ADDRESS",
],
anonymize_action="replace",
device="gpu",
),
text_field="extracted_comment",
)
return redactor(dataset)
def redact_code(dataset: DocumentDataset) -> DocumentDataset:
# functions to extract comment lines from each row in a dataframe
def func(row):
return row["text"][row["text"].find("/*") : row["text"].find("*/") + 2]
def func2(row):
comment = row["text"][row["text"].find("/*") : row["text"].find("*/") + 2]
return row["text"].replace(comment, str(row["extracted_comment"]))
dataset.df["extracted_comment"] = dataset.df.apply(func, axis=1, meta=(None, str))
redacted_dataset = redact_pii(dataset)
redacted_dataset.df["text"] = redacted_dataset.df.apply(
func2, axis=1, meta=(None, str)
)
redacted_dataset.df = redacted_dataset.df.drop(["extracted_comment"], axis=1)
return redacted_dataset
Deduplication
The obtained data might contain a lot of duplicate records. This is especially true for code files scraped from GitHub.
Define a processing step where documents that contain identical information are detected and removed. This is often referred to as exact deduplication and is appropriate for many data curation pipelines.
def dedupe(dataset: DocumentDataset) -> DocumentDataset:
"""
Remove exact duplicates from the given DocumentDataset.
Args:
dataset (DocumentDataset): The dataset containing documents.
Returns:
DocumentDataset: The deduplicated dataset.
"""
deduplicator = ExactDuplicates(id_field="id", text_field="text", hash_method="md5")
# Find the duplicates
duplicates = deduplicator(dataset)
docs_to_remove = duplicates.df.map_partitions(
lambda x: x[x._hashes.duplicated(keep="first")]
)
# Remove the duplicates using their IDs.
duplicate_ids = list(docs_to_remove.compute().id)
dataset_df = dataset.df
deduped = dataset_df[~dataset_df.id.isin(duplicate_ids)]
return DocumentDataset(deduped)
This function calculates a hash signature for every document in the dataset and marks the ones that share the same signature for removal.
Putting the curation pipeline together
Now that each step of the curation pipeline has been implemented, it’s time to integrate everything and sequentially apply each operation to the dataset.
Use the Sequential class to chain curation operations together.
# Define data curation steps for text and pdf files
curation_steps_text = Sequential(
[
clean_and_unify,
ScoreFilter(
TextLineCountFilter(), text_field="file_type_count", score_type=bool
),
filter_text,
dedupe,
]
)
# Define data curation steps for code files
curation_steps_code = Sequential(
[
clean_and_unify,
ScoreFilter(
CodeLineCountFilter(), text_field="file_type_count", score_type=bool
),
filter_code,
dedupe,
redact_code,
]
)
dataset_text = curation_steps_text(dataset_text).persist()
dataset_code = curation_steps_text(dataset_code).persist()
dataset_text.to_json(out_path, write_to_filename=True)
dataset_code.to_json(out_path, write_to_filename=True)
# Split the dataset by file category and save curated files (optional - to create blended datasets)
separated_data_text = separate_by_metadata(
dataset_text.df, out_path, "category"
).compute()
separated_data_code = separate_by_metadata(
dataset_code.df, out_path, "category"
).compute()
On the backend, NeMo Curator uses Dask to work with the dataset in a distributed manner. As Dask operations are lazy-evaluated, computations only begin when a function (like .persist in this case) is called to trigger them.
Save the datasets to disk and instruct the framework to write each record with an appropriate filename by providing write_to_filename=True.
Lastly, if you plan to perform optional dataset shuffling and blending, split the dataset by categories.
Dataset blending and shuffling (optional)
The last step of the pipeline is to blend the datasets from different sources together and shuffle them. Offline blending and shuffling enhance a base LLM’s generalization by integrating diverse data and preventing overfitting through randomized data exposure.
For this, define the blending function as shown in the following code example and provide each data source, the blending ratios, and the target size, which defines the final size of your dataset:
def blend_and_shuffle(
args: Any, dataset_paths: list, dataset_weights: list, target_size: int
) -> None:
"""
Blend and shuffle curated data based on file paths for continued pre-training
Args:
args (Any): Command-line arguments.
dataset_paths (list): List containing directory paths where the different JSONL files are stored.
dataset_weights (list): List setting weights for each directory path
target_size (int): Target number of data samples after blending
"""
root_path = os.path.join(DATA_DIR, "curated")
output_path = root_path + "/data_blended"
if os.path.isdir(output_path):
shutil.rmtree(output_path)
os.makedirs(output_path)
# Blend the datasets
datasets = [DocumentDataset.read_json(path) for path in dataset_paths]
blended_dataset = nc.blend_datasets(target_size, datasets, dataset_weights)
shuffle = nc.Shuffle(seed=42)
blended_dataset = shuffle(blended_dataset)
# Save the blend
blended_dataset.to_json(output_path)
# Function call
root_path = os.path.join(DATA_DIR, "curated")
dataset_paths = [
root_path + "/CPP",
root_path + "/VerilogVHDL",
root_path + "/text",
root_path + "/Python",
]
dataset_weights = [1.0, 4.0, 4.0, 1.0]
blend_and_shuffle(dataset_paths, dataset_weights, target_size=20)
After the call, the curated dataset is saved under output_path.
Next steps
Now that you’ve learned how to use NeMo Curator for processing data for DAPT, it’s time to experiment. Obtain the complete source code for this tutorial, adapt the code to curate data tailored to your domain, and develop powerful domain-specific LLMs.
You can also request early access to the NVIDIA NeMo Curator microservice, which provides the easiest path for enterprises to get started with data curation from anywhere and offers streamlined performance and scalability to shorten the time to market.
To apply, visit NeMo Curator Microservice Early Access.
