
In the rapidly evolving landscape of AI, the preparation of high-quality datasets for large language models (LLMs) has become a critical challenge. It directly affects a model’s accuracy, performance, and ability to generate reliable and unbiased outputs across diverse tasks and domains.
Thanks to the partnership between NVIDIA and Dataloop, we are addressing this obstacle head-on, revolutionizing how enterprises prepare and manage data for AI applications.
Dataloop is a member of NVIDIA Inception, a program designed to help startups
of all stages accelerate development and business growth.
Transforming data preparation for AI
The integration of NVIDIA NIM microservices with Dataloop’s platform marks a significant leap forward in optimizing data preparation workflows for LLMs. This collaboration enables enterprises to efficiently handle large, unstructured datasets, streamlining preparation for AI-driven processes and LLM training.
Overcoming key challenges
Until now, AI teams faced two primary obstacles in preparing data for LLMs:
- Handling multimodal datasets: The diversity of data types, including video, image, audio, and text, each with unique processing requirements, made it challenging to create a cohesive preparation pipeline.
- Ensuring data quality: Unstructured datasets often lack the consistency and metadata required for AI models to interpret content accurately. This leads to data quality issues that demand extensive manual intervention and data preparation techniques, such as deduplication and quality filtering, for proper labeling and organization.
To overcome these challenges, Dataloop uses NVIDIA NIM advanced inferencing capabilities, ensuring the high-quality transformation of unstructured datasets into human data, capturing complex behaviors essential for AI applications.
While NIM microservices accelerate inferencing at the GPU level, Dataloop focuses on streamlining and automating the deployment process of NVIDIA models. This results in 128x faster deployment compared to traditional containerized methods.
You no longer have to deal with large downloads or cloud configurations. Just drag, drop, and run NIM models. With real-time debugging through Visual Studio Code, NIM microservices are seamlessly production-ready, removing manual setup complexities and empowering efficient AI scaling.

Dataloop is the framework that makes it happen
At the heart of this solution lies a structured framework that seamlessly combines Dataloop’s platform with NVIDIA NIM inferencing power. This integration enables enterprises to process large, unstructured, multimodal datasets with unprecedented ease.
By automating complex tasks like data preparation and structuring, Dataloop removes the need for deep infrastructure expertise, enabling organizations to scale AI models effortlessly. The framework orchestrates pipelines across multiple LLMs, ensuring that data is processed in parallel and ready for deployment with speed and accuracy, making AI adoption faster and more efficient than ever before.
What is NVIDIA NIM?
NVIDIA NIM microservices are a set of intuitive microservices designed to speed up generative AI deployment on any cloud or data center. Supporting a wide range of AI models, including NVIDIA AI foundation, community, and custom models, NIM ensures seamless, scalable AI inferencing, on-premises or in the cloud, while using industry-standard APIs.

NIM microservices provide interactive APIs that enable you to run inference on AI models more seamlessly. They’re packaged as container images on a per model/model family basis (Figure 2). NIM provides the containers to self-host GPU-accelerated microservices for pretrained and customized AI models across clouds, data centers, and workstations.
NIM uses NVIDIA TensorRT-LLM and NVIDIA TensorRT to deliver low response latency and high throughput. At runtime, NIM microservices select the optimal inference engine for each combination of foundation model, GPU, and system. NIM containers also provide standard observability data feeds and built-in support for autoscaling with Kubernetes on NVIDIA GPUs. For more information about NIM features and architecture, see the NVIDIA NIM documentation.
How does Dataloop make it work?
Enterprises generate and collect vast amounts of diverse data—video, image, text, and audio—over time. That data can provide significant business value and operational utility when used for LLM training. To unlock that value, the data needs to be prepared and enriched appropriately, processes that are often resource-intensive.
By integrating NVIDIA NIM with Dataloop, enterprises can streamline the enrichment process, ensuring that data is ready for AI applications with enhanced speed and efficiency.
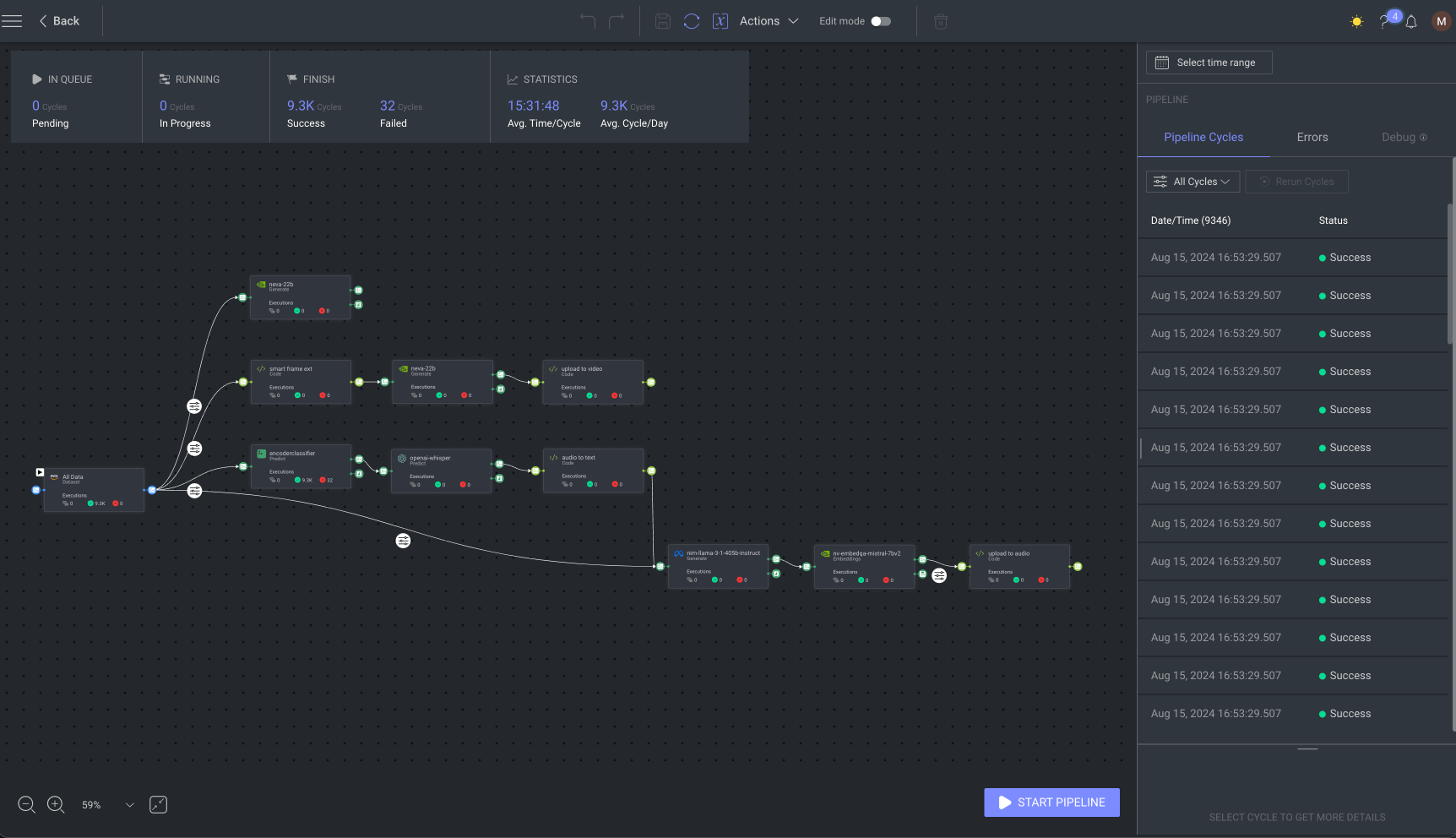
Dataloop easily connects to different data sources and accurately processes millions of files. Combined with NIM microservices, the Dataloop platform accelerates AI workflows, reduces development costs, and enables enterprises to scale AI initiatives without the need for deep technical expertise or complex infrastructure.
Before diving deeper into the pipeline mechanics, here’s an example that describes the two key phases that handle everything from ingestion to transformation:
- Data ingestion and synchronization
- Data structuring and transformation
Phase 1: Data ingestion and synchronization
The workflow kicks off by seamlessly integrating large datasets stored in any major cloud platform, such as AWS, Google Cloud, Azure, and so on. Dataloop orchestrates the data flow, enabling real-time labeling and analysis of every new file.
This dynamic synchronization ensures the datasets are always current, accessible, and prepared for preprocessing and AI model training, while the pipeline dynamically scales to handle data size and complexity.
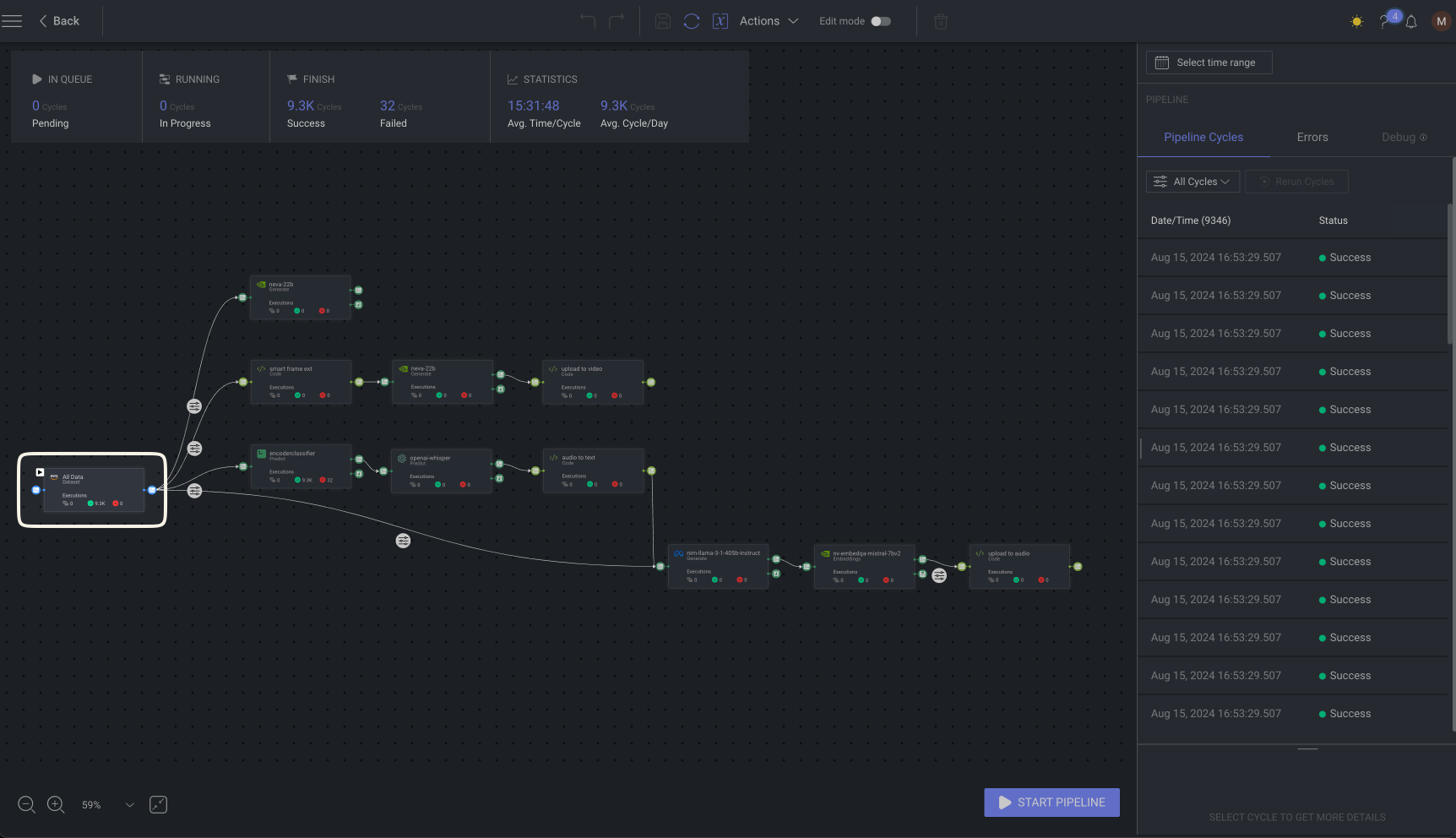
Phase 2: Data structuring and transformation
After ingestion, the next phase involves structuring and transforming the data to make it suitable for LLMs. NVIDIA plays a crucial role in every branch of this stage.
By using advanced NIM models such as NeVA, the pipeline benefits from increased throughput and reduced latency, significantly speeding up the data structuring process. These optimizations allow enterprises to process more data in parallel, reducing time to market for AI projects handling multimodal datasets.
At this stage, Dataloop orchestrates foundational AI models to manage tasks like sorting, tagging, and summarizing content across various data types, ensuring efficient and scalable data preparation.
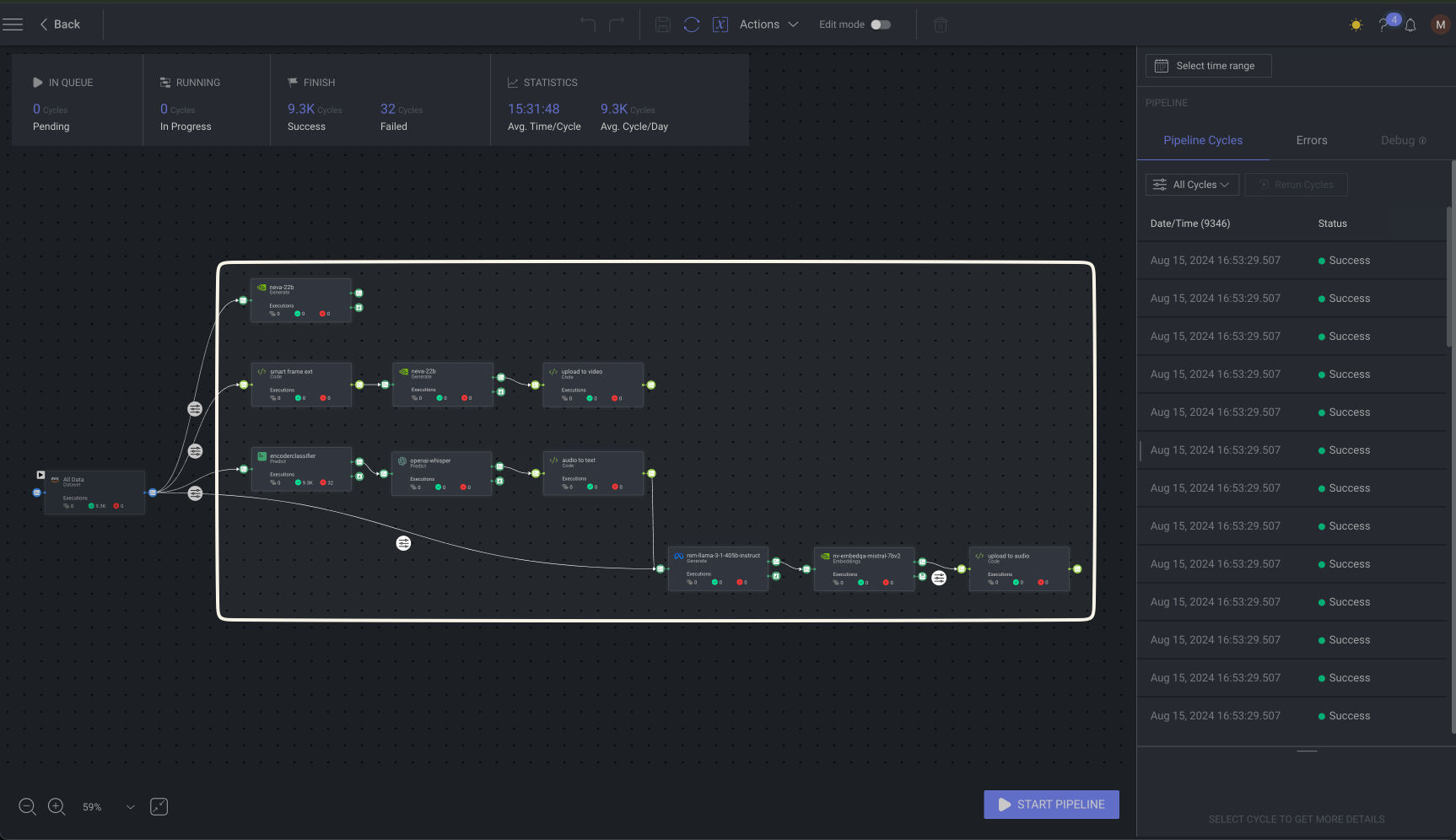
The ease of NIM integration
NVIDIA solutions, including NIM microservices, are available through the NVIDIA Marketplace Hub in the Dataloop platform, simplifying and accelerating integration for developers. These pretrained, cutting-edge models are instantly available and ready for deployment in both new and existing data pipelines.
With intuitive plug-and-play functionality, you can bypass complex setup steps and start using NIM microservices for AI projects immediately.
Deeper dive into structuring workflows
To fully grasp the transformative power of Dataloop’s integration with NVIDIA NIM, it’s essential to look at how the platform tackles the structuring and enrichment of various data types. Each workflow is designed to address the unique characteristics and challenges of different data formats, ensuring streamlined, efficient, and accurate data preparation.
Here’s how Dataloop’s data-enrichment pipeline optimizes processing for different data formats:
- Images
- Videos
- Audio
- Text
Image workflow
When an image reaches the pipeline, it’s immediately processed by the NVIDIA NEVA-22B NIM microservice. This model identifies and automatically annotates the image with remarkable precision, detecting the specific objects, scenes, or elements that are relevant to a unique project.
As each file flows through, Dataloop automatically indexes the annotations, making them available in the platform’s data management section for easy reference and further refinement.
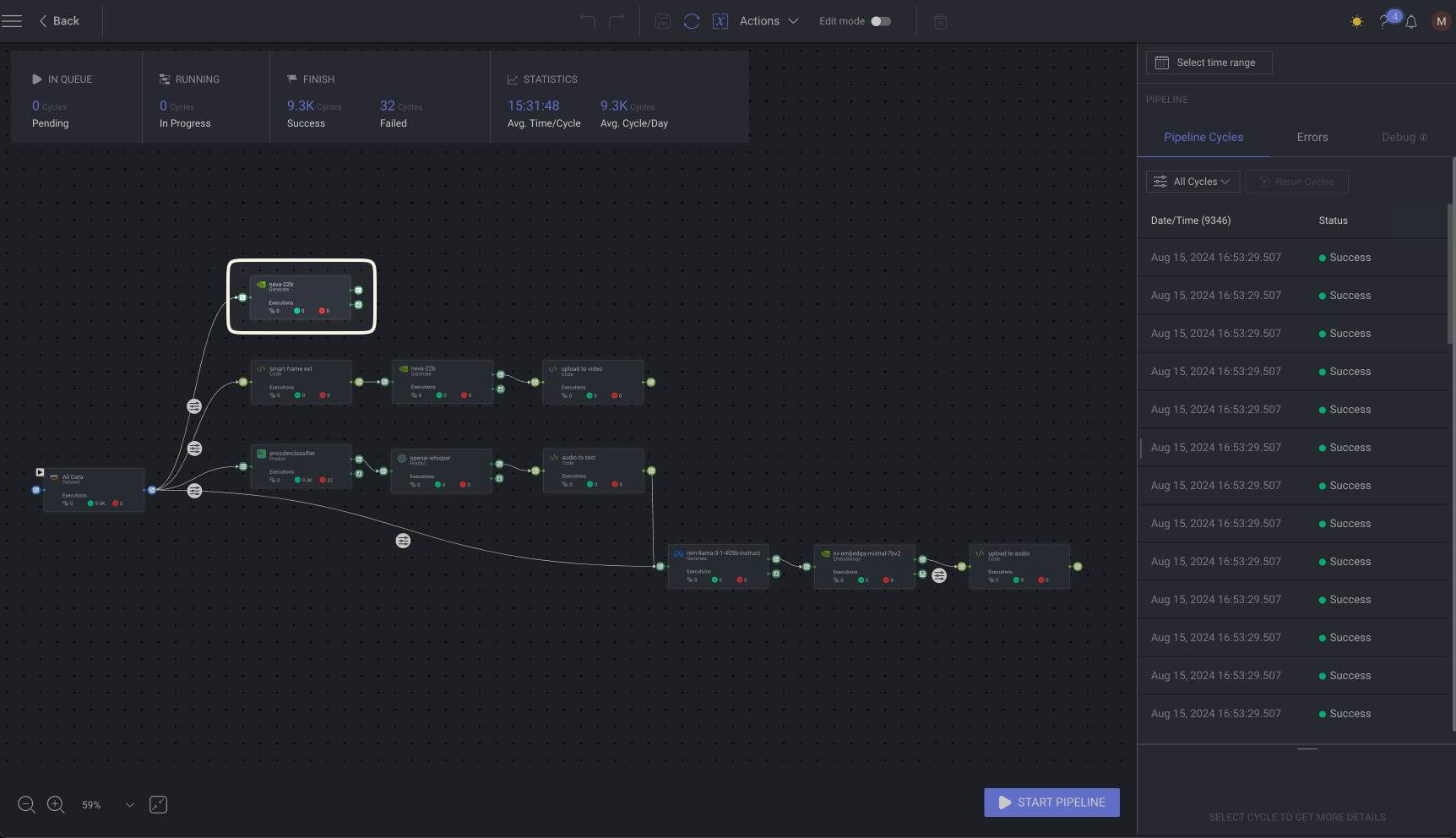
Video workflow
Video files enter the pipeline through the Smart Frame Extraction node, which selects keyframes by detecting motion changes between frames. Instead of processing every frame, Dataloop uses a zero-shot video sub-sampling technique to pinpoint and extract only the most unique frames. This cuts down on processing time and resources.
These selected keyframes are then analyzed by NEVA-22B, where the same high-accuracy annotations applied to images are now used for video frames. The results are clean, actionable insights ready to enrich the dataset. After being annotated, the processed frames are indexed to the original video file, ensuring that everything remains synced in Dataloop.
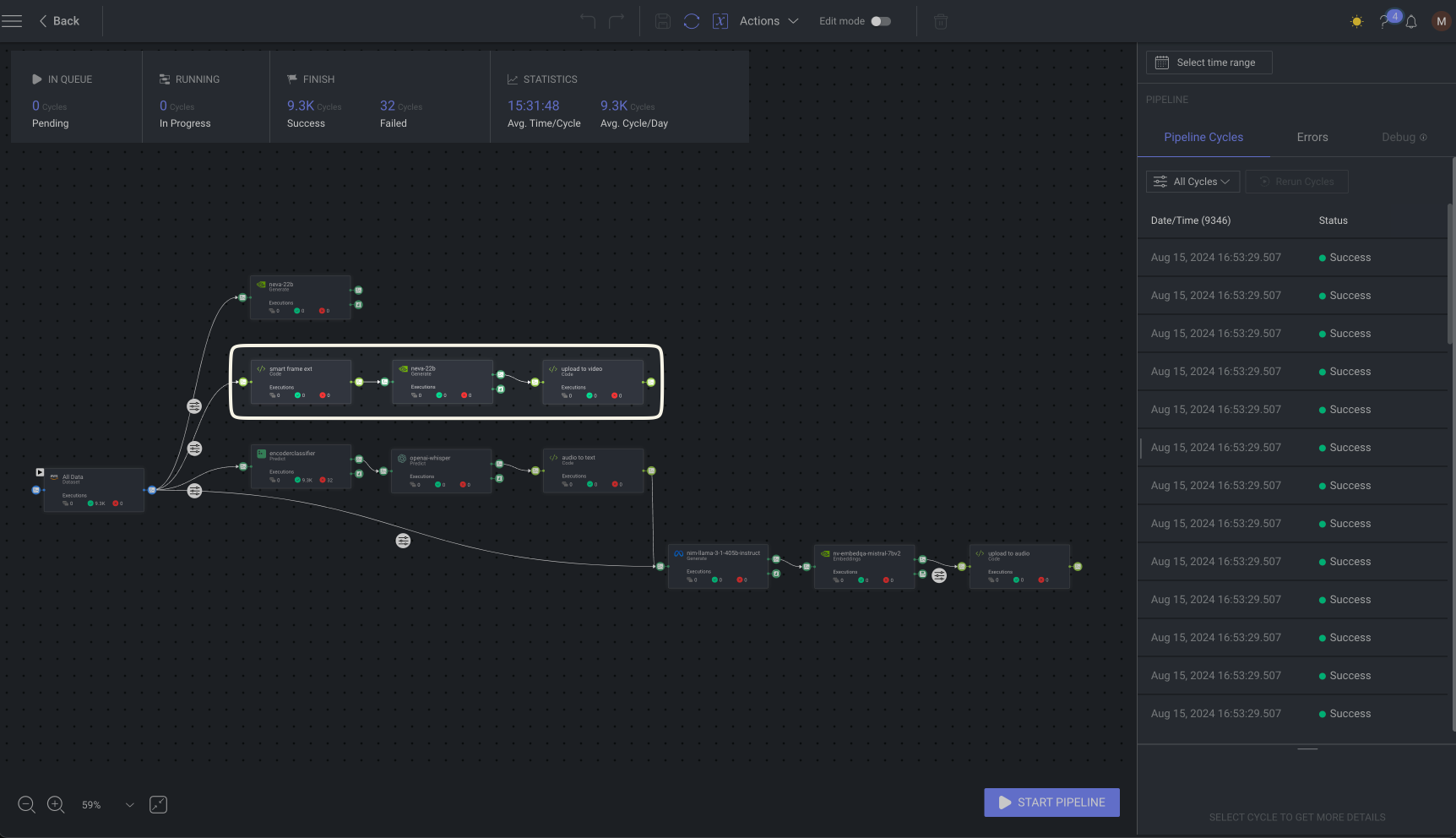
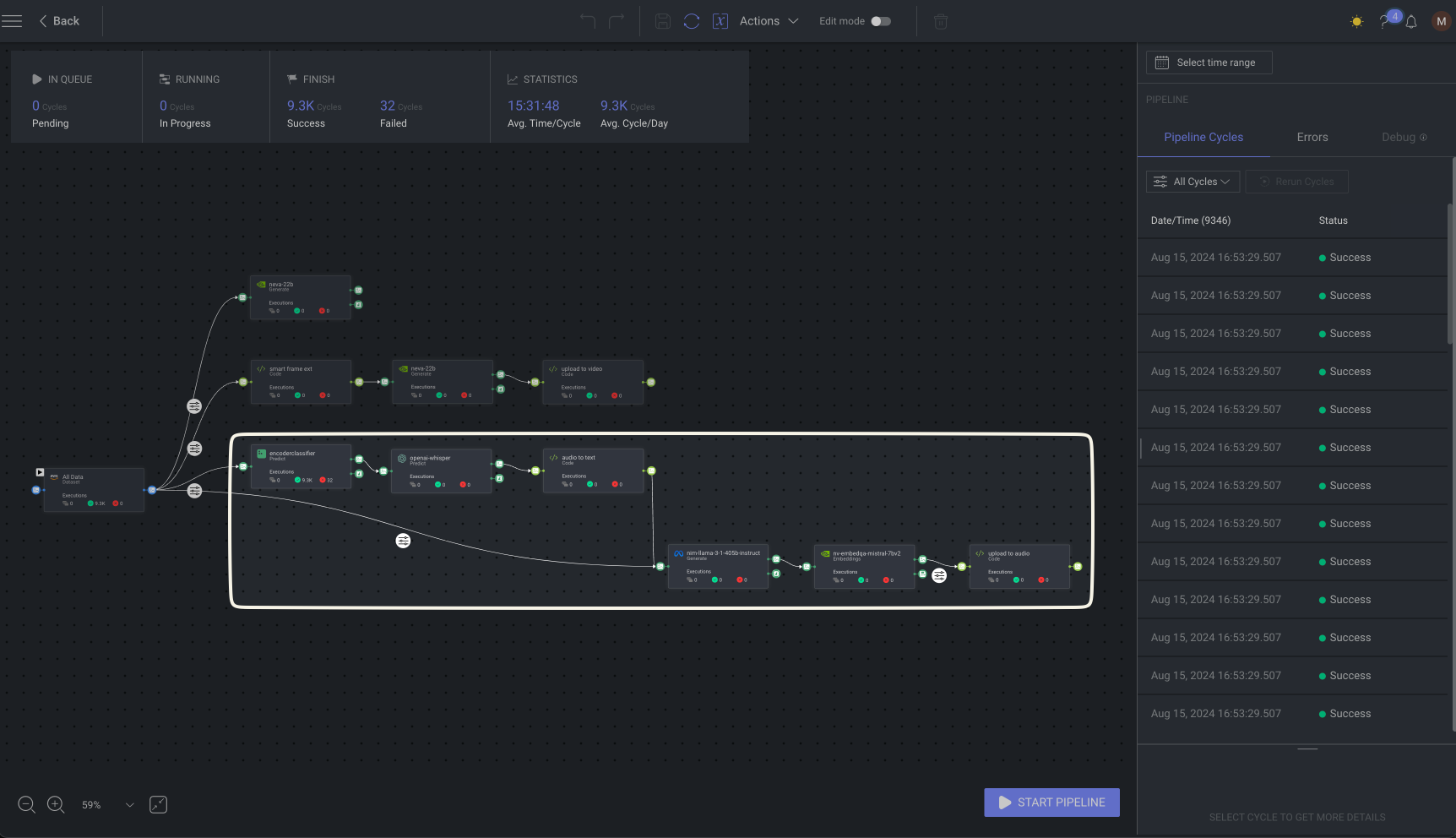
Audio workflow
The audio files are first classified through the Encoder Classifier node, which uses SpeechBrain for language identification and automatic speech recognition (ASR).
When the languages are detected, the node connects to OpenAI’s Whisper for transcription, transforming spoken words into text. Finally, the Audio-to-Text node enhances the transcriptions by passing them through an LLM, which analyzes the text for accuracy and coherence.
This process ensures that the transcriptions are not only correct but also contextually meaningful, capturing the intended message of the audio. The refined output is then indexed into the Dataloop platform. It then passes the text output into the text workflow, making the data immediately accessible for further AI processing.
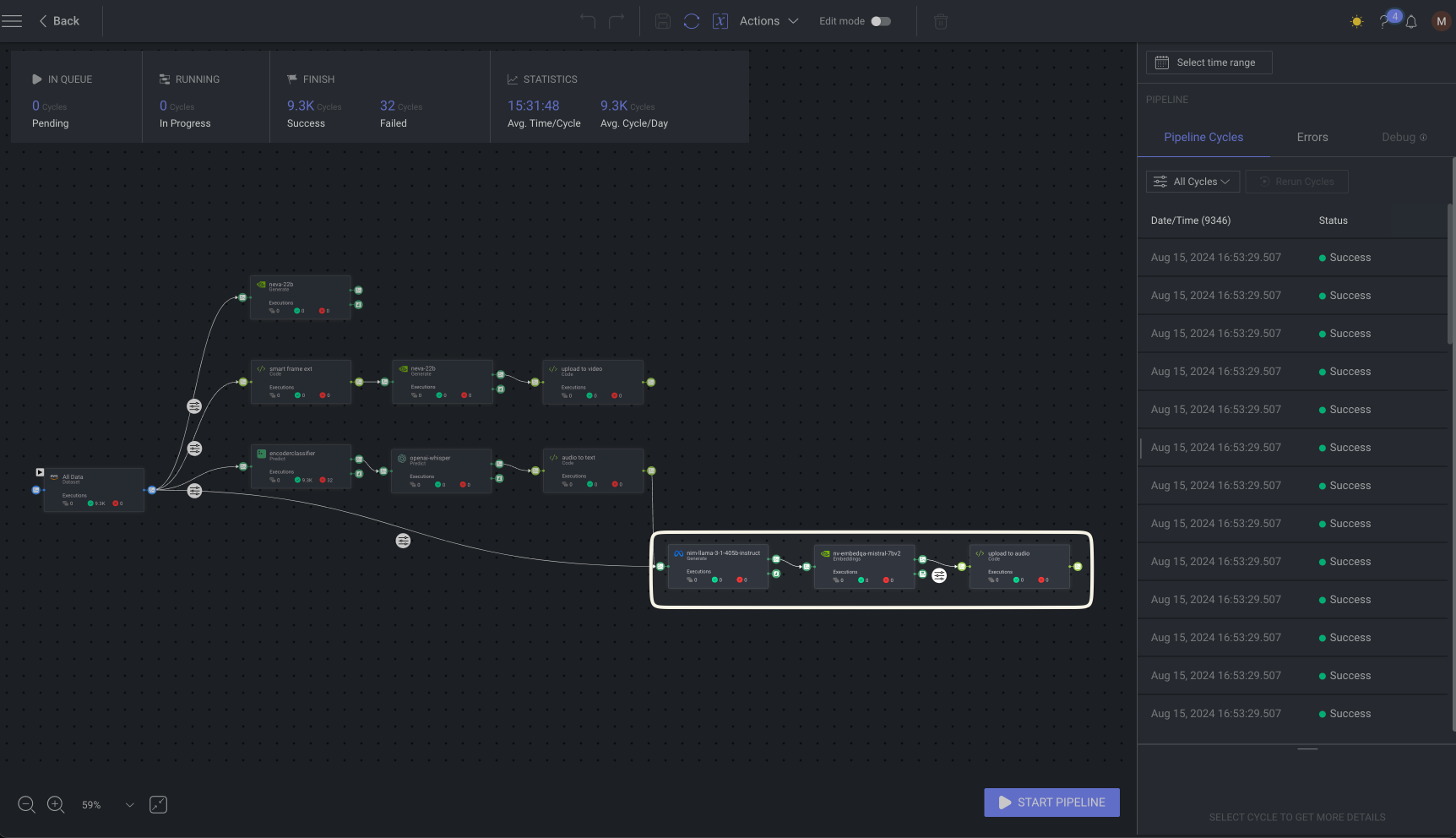
Text workflow
The text workflow starts with the LlaMA 3.1 NIM microservice, which uses tool-calling capabilities to extract named entities. This enables the precise identification of key entities such as company names, dates, and locations.
Following this, the NVIDIA EmbedQA-Mistral-7bv2 model creates semantic embeddings that capture the deeper meaning and context of the text. Finally, the Upload-to-Audio node makes sure that all the processed text data is correctly indexed, bringing the process full circle.
Managing enriched data within Dataloop
After structuring the data, enriched datasets are stored in Dataloop’s data management section, which makes data handling both intuitive and efficient.
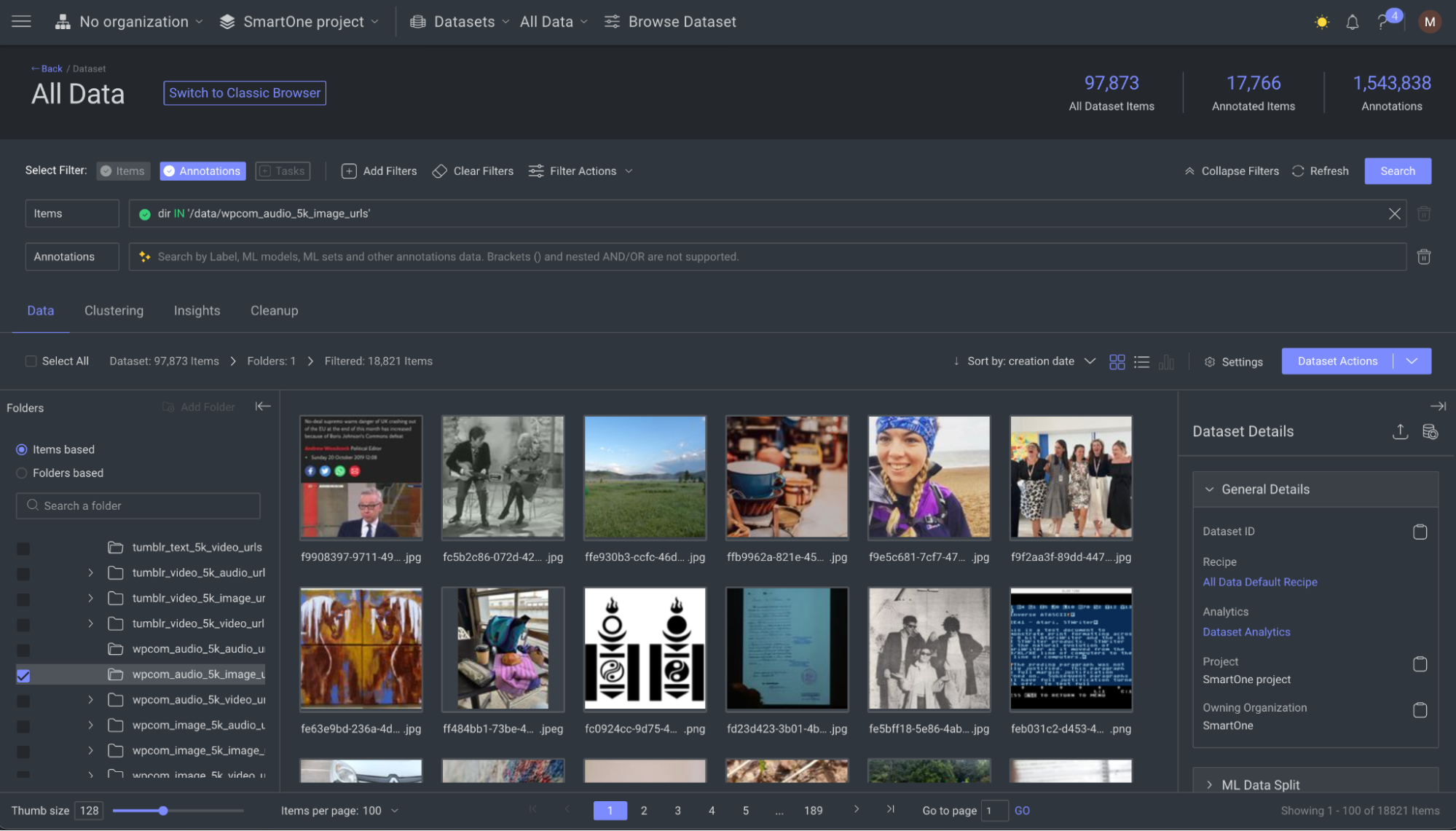
You can visualize, explore, and make real-time data-driven decisions on every file, no matter its type. right from the dataset browser. Dataloop simplifies querying, versioning, and curating datasets, so you can scale confidently and ensure that every piece of data is AI-ready, without delays or headaches.
Conclusion
The integration of NVIDIA NIM in Dataloop’s platform offers enterprises a multitude of advantages, including streamlined deployment, accelerated iteration capabilities, high-performance data processing, and seamless incorporation of industry-leading models.
As the solution evolves and scales, we aim to continue enhancing its multimodal capabilities. While the system currently processes video, audio, image, and text data with remarkable accuracy and efficiency, we see exciting opportunities to expand into more complex data types, such as 3D, sensor, tabular, and geospatial data.
These advancements will open doors for AI applications in diverse fields—ranging from autonomous vehicles and robotics to environmental monitoring and smart cities—where even more intricate datasets can be prepared and enriched for AI model training and unique use cases.
If you’re interested in the technical side of NIM microservices on Dataloop and want to learn how to accelerate NVIDIA model deployment and streamline your AI workflows, see AI Development Partnership.
For a strategic, data-driven outlook, see AI Business Leaders Partnership. That page has case studies and insights on how the collaboration between NVIDIA and Dataloop can enhance AI projects and drive business growth.
