
The initial release of NVIDIA NeMo-RL included training support through PyTorch DTensor (otherwise known as FSDP2). This backend enables native integration with the HuggingFace ecosystem, quick experimentation, and scaling with PyTorch native parallelisms (FSDP2, tensor parallel, sequence parallel, and context parallel).
However, when model sizes approach hundreds of billions of parameters, the DTensor path becomes insufficient. Activation memory from large models introduces significant recompute overhead, resulting in infeasibly slow step times. The DTensor path also lacks optimized NVIDIA CUDA kernels and other performance enhancements necessary for optimal throughput. These challenges highlight the need for a more efficient solution, which is exactly what the NVIDIA Megatron-Core library is designed to provide.
Explore the latest NeMo-RL v0.3 release, where you’ll find detailed documentation, example scripts, and configuration files to efficiently post-train large models with Megatron-Core backend support.
Reinforcement learning with the Megatron backend
Built with GPU-optimized techniques and high-throughput performance enhancements, Megatron-Core enables seamless training of massive language models. The library’s 6D parallelism strategy optimizes communication and computation patterns and supports a diverse range of model architectures.
NeMo-RL has added support for Megatron-Core, enabling developers to use these optimizations during post-training. While Megatron-Core offers many low-level settings, configuring them can be overwhelming for those new to the library. NeMo-RL streamlines this process by automatically handling much of the complex tuning behind the scenes and instead presenting users with a simpler, more intuitive set of configuration options.
Getting started with Megatron training
Enabling Megatron-based training is straightforward. Add the policy.megatron_cfg section to your YAML configuration:
policy:
...
megatron_cfg:
enabled: true
activation_checkpointing: false
tensor_model_parallel_size: 1
pipeline_model_parallel_size: 1
...
optimizer:
...
scheduler:
...
distributed_data_parallel_config:
grad_reduce_in_fp32: false
overlap_grad_reduce: true
overlap_param_gather: true
average_in_collective: true
use_custom_fsdp: false
data_parallel_sharding_strategy: "optim_grads_params"
See a complete working example.
All arguments within the config will be forwarded to Megatron during training. After adding the megatron section to your config and setting enabled=True, you’re ready to train a model. Launching training is done in the same way as with DTensor, as described in the README or our guide on reproducing DeepScaleR.
Results
Megatron-based training supports both dense and Mixture of Experts (MoE) models. The following shows a step time breakdown for Group Relative Policy Optimization (GRPO) on a few commonly used models. The timing reported in the table is an average over steps 22-29 of each training run.
| Model | Backend | Nodes | GPUs per node | Total step time (s) | Policy training (s) | Refit (s) | Generation (s) | Get logprobs (s) | Avg. generated tokens per sample |
| Llama 3.1-8B Instruct | Megatron | 1 | 8 | 112 | 28 | 5 | 58 | 18 | 795 |
| PyT DTensor | 1 | 8 | 122 | 38 | 4 | 57 | 19 | 777 | |
| Llama 3.1-70B Base | Megatron | 8 | 8 | 147 | 28 | 14 | 84 | 18 | 398 |
| PyT DTensor* | 8 | 8 | 230 | 97 | 15 | 82 | 28 | 395 | |
| Qwen3 32B** | Megatron | 8 | 8 | 213 | 68 | 7 | 96 | 40 | 3283 |
| Qwen3 30B-A3B** | Megatron | 8 | 8 | 167 | 50 | 12 | 78 | 23 | 3251 |
All runs were conducted with the following settings. Max sequence length 4096, rollout batch size 2048, global batch size 512, and sequence packing enabled (see the subsequent section for details on sequence packing). For the Megatron-Core runs, Llama 3.1 8B was run with only data in parallel. Llama 3.1 70B was run with 4-way tensor and 4-way pipeline parallel. Qwen3 32B was run with 4-way tensor and 2-way pipeline parallel, and Qwen3 30B-A3B was run with 8-way expert and 2-way tensor parallel.
*Llama 70B DTensor results were gathered using dynamic batching rather than sequence packing because of a known out-of-memory issue with sequence packing.
**Qwen3 32B and 30B-A3B DTensor fail due to a known assertion error. See the issue.
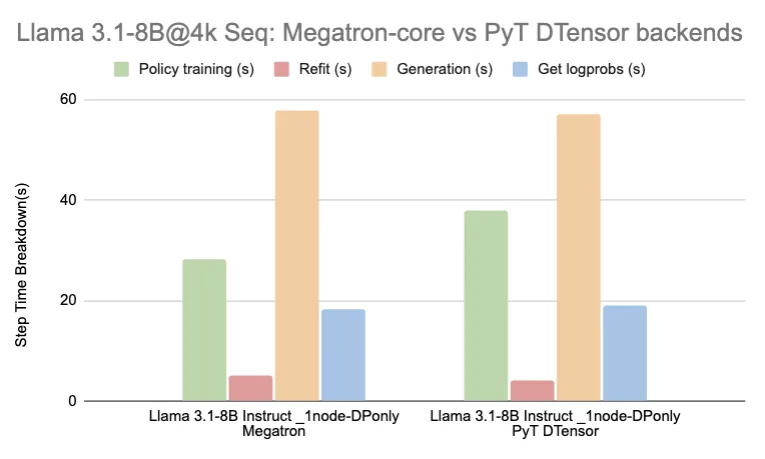

By using performance optimizations provided by Megatron-Core, we achieved superior training performance relative to DTensor with the same convergence properties, as shown.

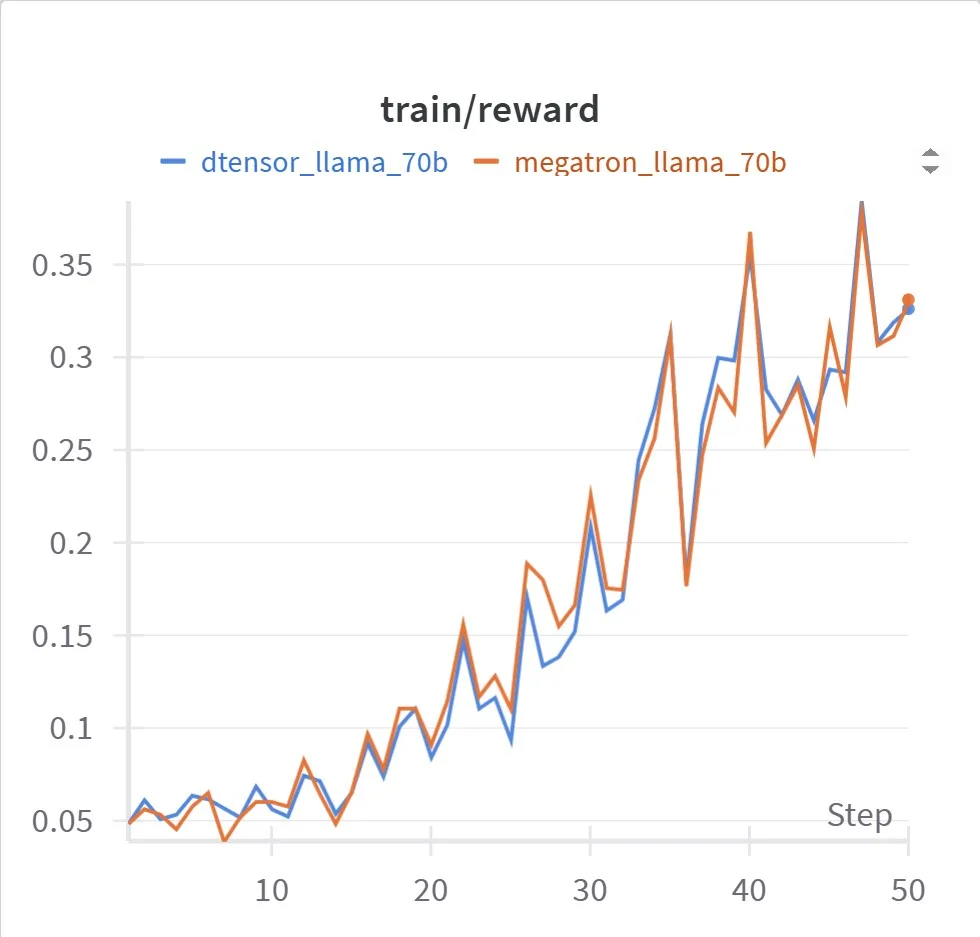
The following commands were used to generate these reward curves:
## 8B -- requires a single node
## dtensor
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_8B.yaml \
loss_fn.use_importance_sampling_correction=True
## megatron
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_8B_megatron.yaml \
policy.sequence_packing.enabled=True loss_fn.use_importance_sampling_correction=True
## 70B -- requires 8 nodes
## dtensor
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_8B.yaml \
policy.model_name=meta-llama/Llama-3.1-70B policy.tokenizer.name=meta-llama/Llama-3.1-70B-Instruct \
policy.generation.vllm_cfg.tensor_parallel_size=4 policy.max_total_sequence_length=4096 \
cluster.num_nodes=8 policy.dtensor_cfg.enabled=True policy.dtensor_cfg.tensor_parallel_size=8 \
policy.dtensor_cfg.sequence_parallel=True policy.dtensor_cfg.activation_checkpointing=False \
loss_fn.use_importance_sampling_correction=True
## megatron
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_70B_megatron.yaml \
policy.model_name=meta-llama/Llama-3.1-70B policy.tokenizer.name=meta-llama/Llama-3.3-70B-Instruct \
policy.sequence_packing.enabled=True loss_fn.use_importance_sampling_correction=True
These runs use some performance and convergence enhancements to ensure that we achieve both optimal throughput and convergence.
- Sequence packing: Multiple sequences are packed to the
max_total_sequence_length. Sequence packing reduces the number of padding tokens and is particularly useful when there are large variations in sequence length. For Llama 70B, enabling sequence packing yields an approximate 1x reduction in overall step time with no impact on convergence. This enhancement is supported for the Megatron-Core and DTensor backends. For more details on sequence packing in NeMo-RL, refer to our documentation. - Importance sampling: NeMo-RL uses different frameworks for inference and training to achieve the best performance; however, there may be small differences in token probabilities between training and inference. One way to mitigate this issue is to use importance sampling, which assigns a weight to each sample that is a function of the inference and training probabilities. Enabling importance sampling reduces the variance between runs and enables better match convergence between Megatron-Core and DTensor policies. For more information on importance sampling in NeMo-RL, refer to our documentation.
Long sequence support
We can also use context parallelism with Megatron-Core and DTensor for long-context training. For example, the following shows current performance results for Llama 3.3 70B at 16k sequence length using the Megatron backend. Even longer sequence lengths are supported, and performance optimizations for long context training are ongoing.
| Model | Max sequence length | Nodes | GPUs per node | Context parallel size | Total step time (s) | Policy training (s) | Refit (s) | Generation (s) | Get logprobs (s) | Avg. generated tokens per sample |
| Llama 3.3-70B Instruct | 16,384 | 16 | 8 | 4 | 445 | 64 | 17 | 287 | 75 | 749 |
Table 2: Performance of Llama 3.3-70B Instruct with 16K long context window with Megatron backend
Other notable features
In addition to the Megatron training backend, NeMo-RL V0.3 introduces several exciting features that help democratize efficient post-training on a wide range of models:
- Async rollouts: Users can now switch on the vLLM async engine by setting
policy.generation.async_engine=True, which speeds up multi-turn RL by 2-3x. - Non-colocated generation (DTensor backend): Users now have the option to place the training and generation backends on different sets of GPUs. This can be useful if training and generation have incompatible parallelisms/world sizes, or if the memory after offloading for training or generation is not low enough with colocation. See the 0.3.0 release notes for more details.
Coming soon
Stay on the lookout for the following features coming very soon:
- Efficient, larger MOE model support using the Megatron backend to run models on the order of hundreds of billions of parameters, including DeepSeek-V3 and Qwen3-235B-A22B.
- Highly optimized refit.
- FP8 generation support.
- Megatron and DTensor VLM support.
- Non-colocated generation with the Megatron-Core backend.
Conclusion
In this post, we showed how NeMo-RL v0.3 with Megatron-Core backend significantly improves reinforcement learning training throughput compared to PyTorch DTensor, especially for large models like Llama 70B. With GPU-optimized kernels, 4D parallelism, and features like sequence packing and importance sampling, NeMo-RL ensures both efficiency and convergence across model scales. We also showed how long-context training is supported, delivering strong performance even at 16k sequence lengths.
Explore the NVIDIA NeMo RL documentation, example configs, and scripts to start post-training your large models with Megatron-Core optimizations.
