

Imagine waiting for your flight at the airport. Suddenly, an important business call with a high profile customer lights up your phone. Tons of background noise clutters up the soundscape around you — background chatter, airplanes taking off, maybe a flight announcement. You have to take the call and you want to sound clear.
We all have been in this awkward, non-ideal situation. It’s just part of modern business.
Background noise is everywhere. And it’s annoying.
Now imagine that when you take the call and speak, the noise magically disappears and all anyone can hear on the other end is your voice. No whisper of noise gets through.
This vision represents our passion at 2Hz. Let’s hear what good noise reduction delivers.
Two years ago, we sat down and decided to build a technology which will completely mute the background noise in human-to-human communications, making it more pleasant and intelligible. Since then, this problem has become our obsession.
Let’s take a look at what makes noise suppression so difficult, what it takes to build real time low-latency noise suppression systems, and how deep learning helped us boost the quality to a new level.
Current State of Art in Noise Suppression
Let’s clarify what noise suppression is. It may seem confusing at first blush.
Noise suppression in this article means suppressing the noise that goes from your background to the person you are having a call with, and the noise coming from their background to you, as figure 1 shows.
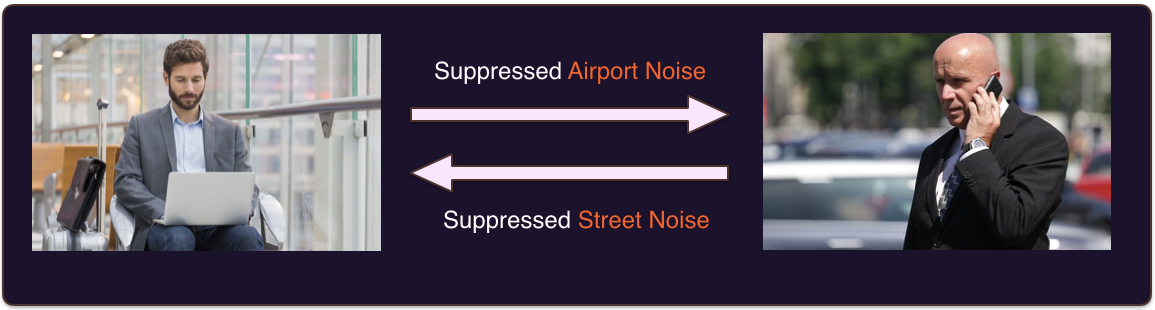
This contrasts with Active Noise Cancellation (ANC), which refers to suppressing unwanted noise coming to your ears from the surrounding environment. Active noise cancellation typically requires multi-microphone headphones (such as Bose QuiteComfort), as you can see in figure 2.
This post focuses on Noise Suppression, not Active Noise Cancellation.
Traditional Approach to Noise Suppression
Traditional noise suppression has been effectively implemented on the edge device — phones, laptops, conferencing systems, etc. This seems like an intuitive approach since it’s the edge device that captures the user’s voice in the first place. Once captured, the device filters the noise out and sends the result to the other end of the call.
The mobile phone calling experience was quite bad 10 years ago. This remains the case with some mobile phones; however more modern phones come equipped with multiple microphones (mic) which help suppress environmental noise when talking.
Current-generation phones include two or more mics, as shown in figure 2, and the latest iPhones have 4. The first mic is placed in the front bottom of the phone closest to the user’s mouth while speaking, directly capturing the user’s voice. Phone designers place the second mic as far as possible from the first mic, usually on the top back of the phone.
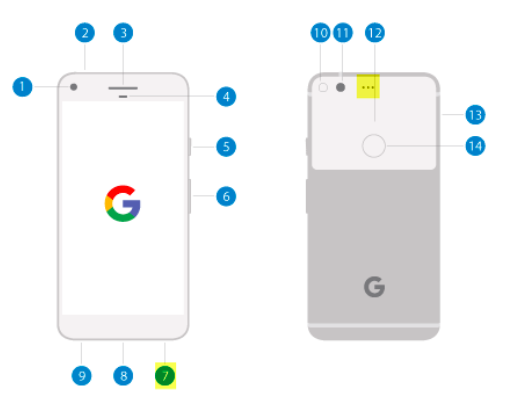
Both mics capture the surrounding sounds. The mic closer to the mouth captures more voice energy; the second one captures less voice. Software effectively subtracts these from each other, yielding an (almost) clean Voice.
This sounds easy but many situations exist where this tech fails. Imagine when the person doesn’t speak and all the mics get is noise. Or imagine that the person is actively shaking/turning the phone while they speak, as when running. Handling these situations is tricky.
Two and more mics also make the audio path and acoustic design quite difficult and expensive for device OEMs and ODMs. Audio/Hardware/Software engineers have to implement suboptimal tradeoffs to support both the industrial design and voice quality requirements…
Given these difficulties, mobile phones today perform somewhat well in moderately noisy environments.. Existing noise suppression solutions are not perfect but do provide an improved user experience.
The form factor comes into play when using separated microphones, as you can see in figure 3. The distance between the first and second mics must meet a minimum requirement. When the user places the phone on their ear and mouth to talk, it works well.
However the “candy bar” form factor of modern phones may not be around for the long term. Wearables (smart watches, mic on your chest), laptops, tablets, and and smart voice assistants such as Alexa subvert the flat, candy-bar phone form factor. Users talk to their devices from different angles and from different distances. In most of these situations, there is no viable solution. Noise suppression simply fails.
Moving from Multi-microphone design to Single-microphone
Multi-microphone designs have a few important shortcomings.
- They require a certain form factor, making them only applicable to certain use cases such as phones or headsets with sticky mics (designed for call centers or in-ear monitors).
- Multi-mic designs make the audio path complicated, requiring more hardware and more code. In addition, drilling holes for secondary mics poses an industrial ID quality and yield problem.
- Audio can be processed only on the edge or device side. Thus the algorithms supporting it cannot be very sophisticated due to the low power and compute requirement.
Now imagine a solution where all you need is a single microphone with all the post processing handled by software. This allows hardware designs to be simpler and more efficient.
It turns out that separating noise and human speech in an audio stream is a challenging problem. No high-performance algorithms exist for this function.
The traditional Digital Signal Processing (DSP) algorithms try to continuously find the noise pattern and adopt to it by processing audio frame by frame. These algorithms work well in certain use cases. However, they don’t scale to the variety and variability of noises that exist in our everyday environment.
There are two types of fundamental noise types that exist: Stationary and Non-Stationary, shown in figure 4.
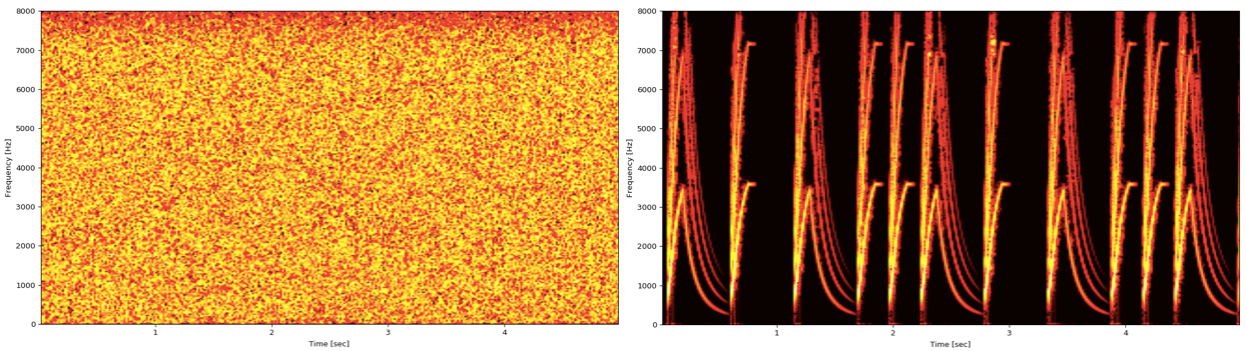
Think of stationary noise as something with a repeatable yet different pattern than human voice. Traditional DSP algorithms (adaptive filters) can be quite effective when filtering such noises.
Non-stationary noises have complicated patterns difficult to differentiate from the human voice. The signal may be very short and come and go very fast (for example keyboard typing or a siren). Refer to this Quora article for more technically correct definition.
If you want to beat both stationary and non-stationary noises you will need to go beyond traditional DSP. At 2Hz, we believe deep learning can be a significant tool to handle these difficult applications.
Separating Background Noise with Deep Learning
A fundamental paper regarding applying Deep Learning to Noise suppression seems to have been written by Yong Xu in 2015.
Yong proposed a regression method which learns to produce a ratio mask for every audio frequency. The produced ratio mask supposedly leaves human voice intact and deletes extraneous noise. While far from perfect, it was a good early approach.
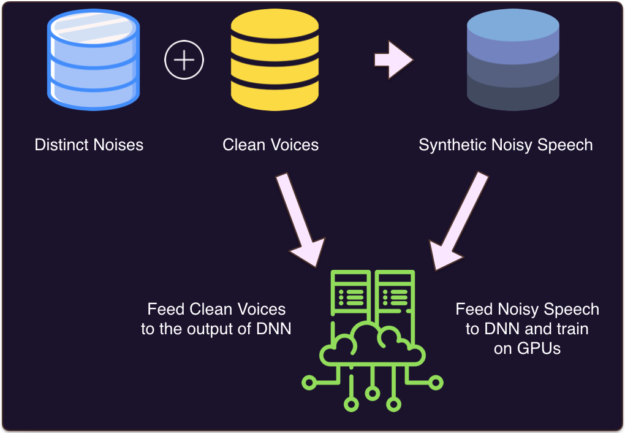
In subsequent years, many different proposed methods came to pass; the high level approach is almost always the same, consisting of three steps, diagrammed in figure 5:
- Data Collection: Generate big dataset of synthetic noisy speech by mixing clean speech with noise
- Training: Feed this dataset to the DNN on input and the clean speech on the output
- Inference: Produce a mask (binary, ratio or complex) which will leave the human voice and filter out noise
At 2Hz, we’ve experimented with different DNNs and came up with our unique DNN architecture that produces remarkable results on variety of noises. The average MOS score (mean opinion score) goes up by 1.4 points on noisy speech, which is the best result we have seen. This result is quite impressive since traditional DSP algorithms running on a single microphone typically decrease the MOS score.
Voice Latency. Is Real Time DNN possible?
Low latency is critical in voice communication. Humans can tolerate up to 200ms of end-to-end latency when conversing, otherwise we talk over each other on calls. The longer the latency, the more we notice it and the more annoyed we become.
Three factors can impact end-to-end latency: network, compute, and codec. Usually network latency has the biggest impact. Codec latency ranges between 5-80ms depending on codecs and their modes, but modern codecs have become quite efficient. Compute latency really depends on many things.
Compute latency makes DNNs challenging. If you want to process every frame with a DNN, you run a risk of introducing large compute latency which is unacceptable in real life deployments.
Compute latency depends on various factors:
Compute platform capabilities
Running a large DNN inside a headset is not something you want to do. There are CPU and power constraints. Achieving real-time processing speed is very challenging unless the platform has an accelerator which makes matrix multiplication much faster and at lower power.
DNN architecture
The speed of DNN depends on how many hyper parameters and DNN layers you have and what operations your nodes run. If you want to produce high quality audio with minimal noise, your DNN cannot be very small.
For example, Mozilla’s rnnoise is very fast and might be possible to put into headsets. However its quality isn’t impressive on non-stationary noises.
Audio sampling rate
The performance of the DNN depends on the audio sampling rate. The higher the sampling rate, the more hyper parameters you need to provide to your DNN.
By contrast, Mozilla’s rnnoise operates with bands which group frequencies so performance is minimally dependent on sampling rate. While an interesting idea, this has an adverse impact on the final quality.
Narrowband audio signal (8kHz sampling rate) is low quality but most of our communications still happens in narrowband. This is because most mobile operators’ network infrastructure still uses narrowband codecs to encode and decode audio.
Since narrowband requires less data per frequency it can be a good starting target for real-time DNN. But things become very difficult when you need to add support for wideband or super-wideband (16kHz or 22kHz) and then full-band (44.1 or 48kHz). These days many VoIP based Apps are using wideband and sometimes up to full-band codecs (the open-source Opus codec supports all modes).
In a naive design, your DNN might require it to grow 64x and thus be 64x slower to support full-band.
How to test Noise Suppression algorithms?
Testing the quality of voice enhancement is challenging because you can’t trust the human ear. Different people have different hearing capabilities due to age, training, or other factors. Unfortunately, no open and consistent benchmarks exist for Noise suppression, so comparing results is problematic.
Most academic papers are using PESQ, MOS and STOI for comparing results. You provide original voice audio and distorted audio to the algorithm and it produces a simple metric score. For example, PESQ scores lie between -0.5 – 4.5, where 4.5 is a perfectly clean speech. PESQ, MOS and STOI haven’t been designed for rating noise level though, so you can’t blindly trust them. You must have subjective tests as well in your process.
ETSI Room
A more professional way to conduct subjective audio tests and make them repeatable is to meet criteria for such testing created by different standard bodies.
The 3GPP telecommunications organization defines the concept of an ETSI room. If you intend to deploy your algorithms into real world you must have such setups in your facilities. ETSI rooms are a great mechanism for building repeatable and reliable tests; figure 6 shows one example.

The room offers perfect noise isolation. It also typically incorporates an artificial human torso, an artificial mouth (a speaker) inside the torso simulating the voice, and a microphone-enabled target device at a predefined distance.
This enables testers to simulate different noises using the surrounding speakers, play voice from the “torso speaker”, and capture the resulting audio on the target device and apply your algorithms. All of these can be scripted to automate the testing.
Outbound Noise vs Inbound Noise
Noise suppression really has many shades.
Imagine you are participating in a conference call with your team. Four participants are in the call, including you. There can now be four potential noises in the mix. Everyone sends their background noise to others.
Traditionally, noise suppression happens on the edge device, which means noise suppression is bound to the microphone. You get the signal from mic(s), suppress the noise, and send the signal upstream.
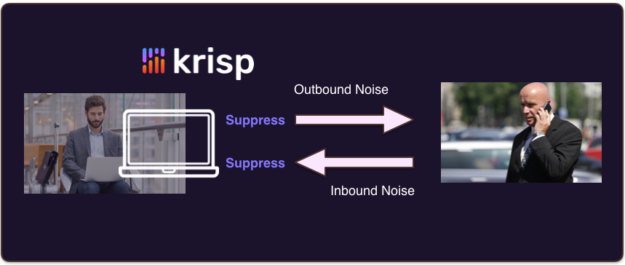
Since a single-mic DNN approach requires only a single source stream, you can put it anywhere. Now imagine that you want to suppress both your mic signal (outbound noise) and the signal coming to your speakers (inbound noise) from all participants.
We built our app, Krisp, explicitly to handle both inbound and outbound noise (figure 7).
The following video demonstrates how non-stationary noise can be entirely removed using a DNN.
The problem becomes much more complicated for inbound noise suppression.
You need to deal with acoustic and voice variances not typical for noise suppression algorithms. For example, your team might be using a conferencing device and sitting far from the device. This means the voice energy reaching the device might be lower. Or they might be calling you from their car using their iPhone attached to the dashboard, an inherently high-noise environment with low voice due to distance from the speaker. In another scenario, multiple people might be speaking simultaneously and you want to keep all voices rather than suppressing some of them as noise.
When you place a Skype call you hear the call ringing in your speaker. Is that *ring* a noise or not? Or is *on hold music* a noise or not? I will leave you with that.
Moving to the Cloud
By now you should have a solid idea on the state of the art of noise suppression and the challenges surrounding real-time deep learning algorithms for this purpose. You’ve also learned about critical latency requirements which make the problem more challenging. The overall latency your noise suppression algorithm adds cannot exceed 20ms — and this really is an upper limit.
Since the algorithm is fully software-based, can it move to the cloud, as figure 8 shows?
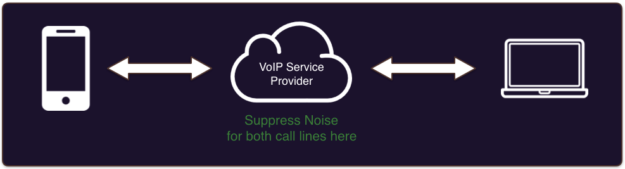
The answer is yes. First, cloud-based noise suppression works across all devices. Secondly, it can be performed on both lines (or multiple lines in a teleconference). We think noise suppression and other voice enhancement technologies can move to the cloud. This wasn’t possible in the past, due to the multi-mic requirement. Mobile Operators have developed various quality standards which device OEMs must implement in order to provide the right level of quality, and the solution to-date has been multiple mics. However, Deep Learning makes possible the ability to put noise suppression in the cloud while supporting single-mic hardware.
The biggest challenge is scalability of the algorithms.
Scaling 20x with Nvidia GPUs
If we want these algorithms to scale enough to serve real VoIP loads, we need to understand how they perform.
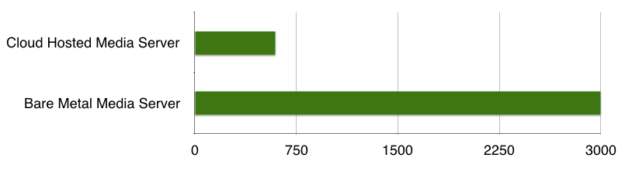
Large VoIP infrastructures serve 10K-100K streams concurrently. One VoIP service provider we know serves 3,000 G.711 call streams on a single bare metal media server, which is quite impressive.
There are many factors which affect how many audio streams a media server such as FreeSWITCH can serve concurrently. One obvious factor is the server platform. Cloud deployed media servers offer significantly lower performance compared to bare metal optimized deployments, as shown in figure 9.
Server side noise suppression must be economically efficient otherwise no customer will want to deploy it.
Our first experiments at 2Hz began with CPUs. A single CPU core could process up to 10 parallel streams. This is not a very cost-effective solution.
We then ran experiments on GPUs with astonishing results. A single Nvidia 1080ti could scale up to 1000 streams without any optimizations (figure 10). After the right optimizations we saw scaling up to 3000 streams; more may be possible.
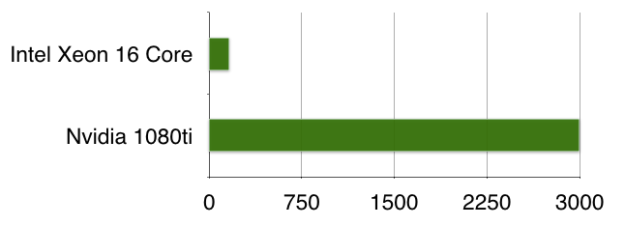
The original media server load, including processing streams and codec decoding still occurs on the CPU. One additional benefit of using GPUs is the ability to simply attach an external GPU to your media server box and offload the noise suppression processing entirely onto it without affecting the standard audio processing pipeline.
Batching with CUDA
Let’s examine why the GPU scales this class of application so much better than CPUs.
CPU vendors have traditionally spent more time and energy to optimize and speed-up single thread architecture. They implemented algorithms, processes, and techniques to squeeze as much speed as possible from a single thread. Since most applications in the past only required a single thread, CPU makers had good reasons to develop architectures to maximize single-threaded applications.
On the other hand, GPU vendors optimize for operations requiring parallelism. This came out of the massively parallel needs of 3D graphics processing. GPUs were designed so their many thousands of small cores work well in highly parallel applications, including matrix multiplication.
Batching is the concept that allows parallelizing the GPU. You send batches of data and operations to the GPU, it processes them in parallel and sends back. This is a perfect tool for processing concurrent audio streams, as figure 11 shows.
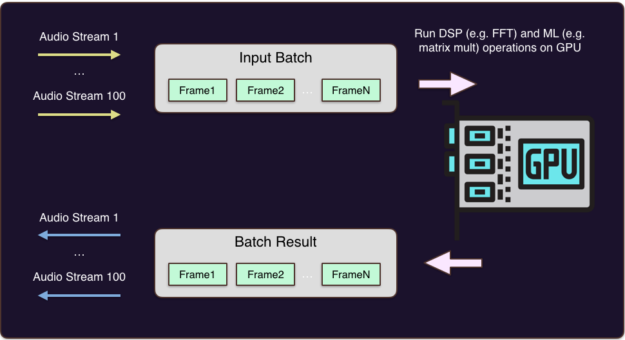
We’ve used NVIDIA’s CUDA library to run our applications directly on NVIDIA GPUs and perform the batching. The below code snippet performs matrix multiplication with CUDA.
void kernelVectorMul(RealPtr dst, ConstRealPtr src1, ConstRealPtr src2, const size_t n)
{
const size_t i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < n)
dst[i] = src1[i] * src2[i];
}
void Utils::vectorMul(RealPtr dst, ConstRealPtr src1, ConstRealPtr src2, const size_t n)
{
dim3 gridSize(n / getDeviceMaxThreadsX() + 1, 1, 1);
dim3 blockSize(getDeviceMaxThreadsX(), 1, 1);
kernelVectorMul <<< gridSize, blockSize >>> (dst, src1, src2, n);
}
void Utils::vectorMul(Vector& dst, const Vector& src1, const Vector& src2)
{
vectorMul(dst.getData(), src1.getData(), src2.getData(), dst.getSize());
}
void Utils::matrixMulRowByRow(Matrix& dst, const Matrix& src1, const Matrix& src2)
{
vectorMul(dst.getData(), src1.getData(), src2.getData(), dst.getSize());
}
The below code performs Fast Fourier Transform with CUDA.
FFT::StatusType FFT::computeBackwardBatched(ComplexTypePtr src, RealTypePtr dst)
{
StatusType s = cufftExecC2R(backward_handle_, reinterpret_cast<cufftComplex*>(src), dst);
dim3 gridSize((getBatchSize() * getForwardDataSize()) / thr_max_ + 1, 1, 1);
dim3 blockSize(thr_max_, 1, 1);
float val = getForwardDataSize();
kernelDivide <<< gridSize, blockSize >>> (dst, val, getBatchSize() * getForwardDataSize());
return s;
}
FFT::StatusType FFT::computeBackwardBatched(ComplexVector& src, Vector& dst)
{
return computeBackwardBatched(src.getData(), dst.getData());
}
Download Krisp for Mac
If you want to try out Deep Learning based Noise Suppression on your Mac – you can do it with Krisp app.
What’s Next?
Audio is an exciting field and noise suppression is just one of the problems we see in the space. Deep Learning will enable new audio experiences and at 2Hz we strongly believe that Deep Learning will improve our daily audio experiences. Check out Fixing Voice Breakups and HD Voice Playback blog posts for such experiences.