
By Sandra Skaff
This week top Robotics researchers have gathered in Montreal, Canada to present their cutting edge research. Our NVAIL partners were among the researchers presenting this research. We highlight here the work of MIT, NYU, and UPenn, which rely on NVIDIA platforms for real-time inference.
MIT – Variational End-to-End Navigation and Localization
The work in the paper was inspired by observing three main properties in human drivers, according to the authors. These are their ability to navigate previously unseen roads, their ability to localize themselves within the environment, and their ability to reason when what they perceive does not align with what the map tells them. Humans can understand the underlying road topology from the map and use visual inputs of the environment to localize between those two. Therefore humans can make decisions when their visual perception is not aligned with the information observed from localization sensors.
Inspired by human abilities, the authors set out to develop a deep learning system which enables an autonomous vehicle to learn how to use navigational information with an end-to-end autonomous driving system. The navigational information is in the form of routed and unrouted maps and is used along with raw sensory data to enable both navigation and localization in complex driving environments as shown in the figure below.
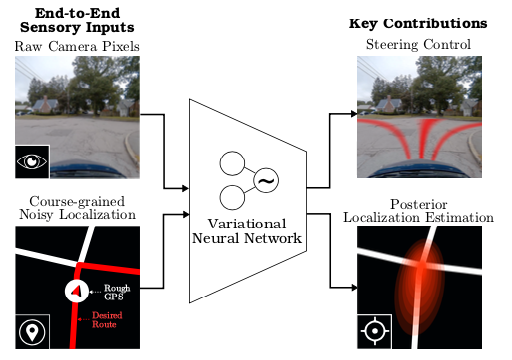
The algorithm takes as input patches from images from three cameras, front, right, and left, as well as an unrouted map image. These images are fed into parallel convolutional pipelines then merged into fully-connected layers, which are consequently used to learn a Gaussian Mixture Model (GMM) over steering control. A routed map, when available, is fed into a separate convolutional pipeline and merged with the middle fully connected layer to learn a deterministic control signal for navigation.
The authors show that their algorithm is capable of outputting control in environments of varying complexity including straight road driving, intersections as well as roundabouts. The algorithm was shown to generalize to new roads and types of intersections that the vehicle has never driven through or seen during training.
The authors also show that the GMM based probabilistic control output can be used to localize the vehicle and as such reduce pose uncertainty and increase its localization confidence. They compute the posterior probability of the pose given a prior computed using poses obtained from the GPS with added uncertainty. The authors conclude that the model is able to increase its localization confidence if the uncertainty in the posterior distribution is lower than that in the prior distribution. This ability to estimate pose and reduce uncertainty is very useful to obtain more precise localization or even in situations in which the vehicle has entirely lost the GPS signal.
The algorithm was trained on NVIDIA V100 GPUs and required ~3 hours for training one model. Inference was performed in real-time on a DRIVE PX2 installed in a Toyota Prius outfitted with drive-by-wire capabilities. The algorithms were implemented in ROS and leveraged the NVIDIA DriveWorks SDK to interface with the vehicle’s sensors.
In the future, the authors plan on pushing the boundaries on autonomy in many ways. Examples include having the vehicle drive in more situations it has not explicitly been trained for, understanding when a sensor or a model is failing, and finding out when a human should help and/or take over control.
MIT was one of three finalist candidates for the Best Conference Paper Award at ICRA 2019. For an overview of this paper, you can check out this video.
NYU – Reconfigurable Network for Efficient Inferencing in Autonomous Vehicles
One of the challenges in autonomous driving is the large number of sensors and consequently data being collected requiring massive amounts of computation and large networks to be trained. To address this challenge, the authors introduced a reconfigurable network which predicts online which sensor provides the most relevant data at a given moment in time. This approach relies on the intuition that only a fraction of the data collected is relevant at a particular moment in time.
The reconfigurable network includes a gating network which is based on the concept of dividing the learning into subtasks, each taken by an expert. The gating network decides which expert to use at a given point in time, which consequently means deciding which sensor data would be consumed by the algorithm. As such, the gating network provides a method to avoid the massive computational costs.
The authors train the reconfigurable network in three steps. First, the expert components are trained as a sensor fusion network in which the gating network uses these experts as the feature extractors for selecting the most relevant sensor. Second, a separate but much smaller gating network is created to mimic the behavior of the first gating network and during training, sparsity is enforced on the output of the gating network to make it only select one expert at any given moment. Third, the reconfigurable network is trained by fine-tuning the experts and the fully connected layers, while using the weights of the gating net estimated in the previous step.
Two versions of the reconfigurable network are trained as shown in the figure below. Note that the Reconf_Select requires less computations because it replaces the concatenation with point-wise summation to combine feature vectors coming out from the experts.


Training the network on 70,000 scenes took ~6 hours on an NVIDIA GeForce GTX 1080 GPU. The network was evaluated on 5,738 test scenes, and inference took a fraction of 1 second for one image on the same GPU. Quantitatively, as evidenced by the test loss, the two proposed versions of the network which select input from one camera achieve the same performance as when inputs from all cameras are used, while requiring three times less computation in FLOPS.
For real-time in vehicle testing, the authors installed an NVIDIA Jetson TX1 along with three Logitech HD Pro cameras on a Traxxas X-Maxx remote control truck. The network had to select one of the three cameras to consume the images from for steering command estimation in real-time in an indoor environment. The algorithm was able to process more than 20 frames/sec online.
To learn more about NYU’s work, watch this video.
UPenn – An Integrated Sensing and Compute System for Mobile Robots
UPenn presented a paper on the Open Vision Computer (OVC), which is an open source computational platform to support high speed, vision guided, GPS-denied, and light-weight autonomous flying robots. OVC was developed in collaboration with the Open Source Robotics Foundation and integrates the sensor and computational elements into a single package.OVC is designed to support a range of computer vision algorithms including visual inertial odometry and stereo, in addition to autonomy related algorithms including path planning and control.
The first version of OVC, OVC1, comprises a sensor subsystem connected to a compute module via a PCIe bus. The sensor subsystem includes a pair of CMOS image sensors and an Inertial Measurement Unit (IMU). The compute module is the NVIDIA Jetson TX2 designed for compute intensive embedded applications with the PCIe bus providing a direct, high speed interface to the TX2’s unified CPU and GPU memory system.
In such a system, the features can be extracted while the images are being streamed from the sensors to the CPU and GPU immediately following the raw images. The authors showed that the system is also capable of processing deep learning based applications such as Single Shot MultiBox Detector (SSD512) for object detection and a variant of the ERFNet architecture for semantic segmentation.
OVC1 weighs less than 200 grams with the TX2 module, and its total power consumption is less than 20 watts. OVC1 was deployed onto the Falcon 250 autonomous flying robot which weighs 1.3 kg. The system was able to successfully traverse hundreds of meters avoiding obstacles including trees and buildings, and return to its start position, without a GPS signal and based on minimal instruction. OVC1 on the Falcon 250 is shown below.

The authors have also come up with a second design of OVC, OVC2, which aims to shrink the form factor and improve performance as shown in the figure below. OVC2 is based on TX2 but the authors are considering Jetson Xavier which offers more capabilities and better performance than the TX2. OVC can be deployed onto a variety of robotics platforms.

UPenn also presented another paper which showcases a real-time stereo depth estimation and sparse depth fusion algorithm which is GPU accelerated and processed on OVC1. This algorithm introduces sparse depth information, which can be obtained from a LIDAR sensor or range camera, into stereo depth estimation and outperforms state of the art on the Middlebury 2014 and KITTI 2015 benchmark datasets.
