Baidu announced their latest production-quality speech synthesis system that can imitate thousands of human voices from people across the globe.
Deep Voice 1 focused on being the first real-time text-to-speech system and Deep Voice 2, with substantial improvements on Deep Voice 1, had the ability to reproduce several hundred voices using the same system.
“Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training ten times faster,” according to the researchers. The company says the new version can learn 10,000 voices with just a half an hour of data each.
Using TITAN Xp GPUs and Tesla P100s, they trained their single-speaker synthesis system on an internal English speech data set consisting of 20 hours of data and their multi-speaker synthesis system on the VCTK (108 speakers and ~44 hours) and LibriSpeech (2,484 speakers with ~820 hours) data sets.
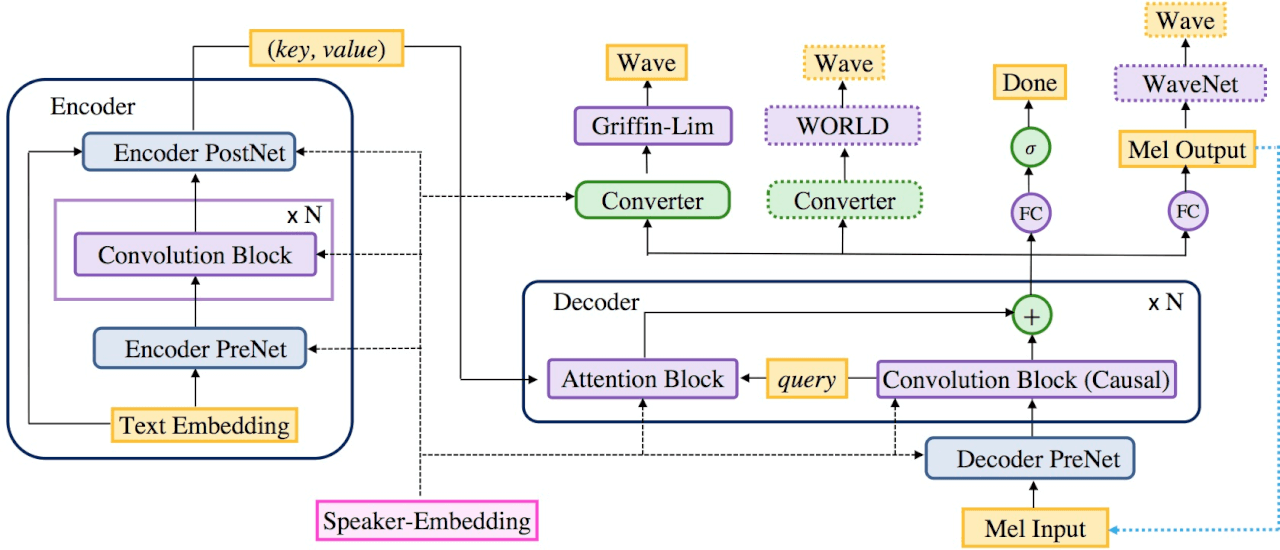
For more details about the architecture, read their paper “Deep Voice 3: 2000-Speaker Neural Text-to-Speech”.
In order to deploy their text-to-speech system in a cost-effective way, the system must be able to handle as much traffic as alternative systems on a comparable amount of hardware. To do so, they used a single Tesla P100 GPU which they mention can handle ten million queries per day.
Read more >
New Speech Synthesis System Can Imitate Thousands of Accents

Oct 24, 2017
Discuss (0)
AI-Generated Summary
- Baidu has announced its latest speech synthesis system, Deep Voice 3, which can imitate thousands of human voices from around the world.
- Deep Voice 3 is a significant improvement over its predecessors, with the ability to learn 10,000 voices with just 30 minutes of data each and training ten times faster than state-of-the-art neural speech synthesis systems.
- The system was trained using powerful GPUs, including NVIDIA's TITAN Xp and Tesla P100, and can handle a large volume of queries, with a single Tesla P100 GPU capable of handling ten million queries per day.
AI-generated content may summarize information incompletely. Verify important information. Learn more