Current audio speech recognition models normally do not perform well in noisy environments. To help solve the problem, researchers from Samsung and Imperial College in London developed a deep learning solution that uses computer vision for visual speech recognition. The model is capable of lipreading, as well as synthesizing audio it sees from the video.
Lipreading is primarily used by people who are deaf or hard-of-hearing. However, there are other applications in which it could be utilized, such as video conferencing in noisy or silent environments.
“Our proposed approach, based on GANs is capable of producing natural sounding, intelligible speech which is synchronized with the video,” the researchers stated in their paper. “To the best of our knowledge, this is the first method that maps video directly to raw audio and the first to produce intelligible speech when tested on previously unseen speakers.”
Using GANs, the model can produce high fidelity audio sequences of realistic speech, even in the case of unseen speakers.
The model is made up of three sub-networks including a generator, which transforms the video frames into waveform, a 3D CNN that generates speech similar to natural speech, and a speech encoder to conserve the speech content of the waveform.
The model is based on the Wasserstein GAN, developed by Facebook AI researchers, which helps minimize the distances between the real and fake distribution.
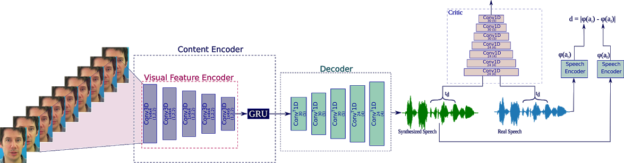
For training, the team used an NVIDIA GeForce 1080 TI GPU, with the cuDNN-accelerated PyTorch deep learning framework.
For inference, the model also relies on an NVIDIA TITAN V GPU. With the GPU, the model can generate audio for a three-second video in 60ms.
Currently, the model works solely on frontal faces. The researchers hope to expand that in future iterations.
“The natural progression of this work will be to reconstruct speech from videos taken in the wild,” the researchers stated.
The work was recently published on ArXiv.
