Building, deploying, and managing end-to-end ML pipelines in production, particularly for applications like recommender systems is challenging. Operationalizing ML models, within enterprise applications, to deliver business value involves a lot more than developing the machine learning algorithms and models themselves – it’s a continuous process of data collection and preparation, model building, training or retraining with newer data, model validation, inference serving, and monitoring model performance to ensure the relevance of the results.
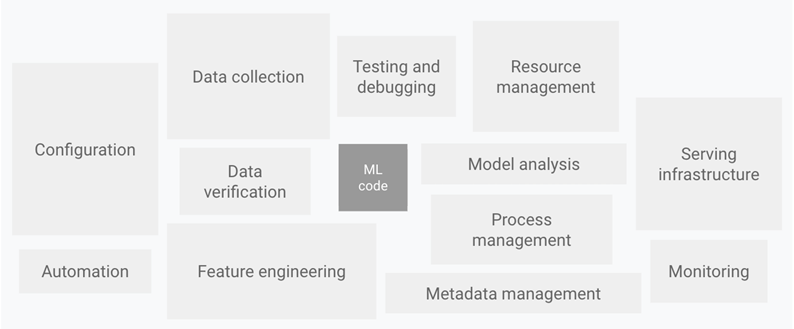
In addition to the challenge of developing the pipeline, you also need to secure and manage the right compute infrastructure to accelerate these steps for a guaranteed quality-of-service (QoS) for your customers. And, each step in the pipeline is unique too so your compute requirements for data preparation and training might be completely different from what’s required to service multiple disparate inference requests. This is both a development and infrastructure management challenge also commonly referred to as the MLOps challenge.
Google Cloud and NVIDIA have collaborated to make MLOps simple, powerful, and cost-effective by bringing together the solution elements to build, serve and dynamically scale your end-to-end ML pipelines with the right-sized GPU acceleration in one place. You can focus on delivering the best value for your end customers while maximizing infrastructure utilization and minimizing operational costs for deploying your AI-enabled services.
GKE + MIG = Portability, Scalability & Productivity for MLOps
Google Kubernetes Engine (GKE) is a managed environment for deploying, scaling and managing containerized ML applications in a secure Google infrastructure. GKE facilitates easy cluster creation, load balancing, autoscaling compute requirements based on demand among other things. Most importantly GKE frees up users from having to manage their own workstations, servers, and VMs while building and deploying ML pipelines – you can focus on the most important value-add tasks of building and training your ML models for your business use-case.
The Google Kubernetes Engine (GKE) now supports the Multi-Instance GPU (MIG) feature enabling each NVIDIA A100 Tensor Core GPU in the new A2 VM instance to be partitioned into as many as seven independent GPU instances, each with its own high-bandwidth memory, cache, and compute cores. GKE can then provision GPU resources for your workloads with greater granularity, share a single GPU for multi-user, multi-model use-cases and automatically scale up or down based on changing needs of your ML pipelines.
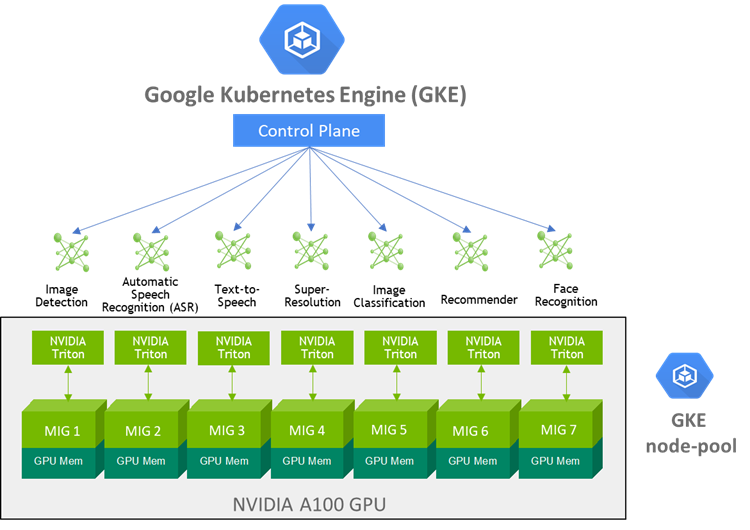
For example, GKE can provision multiple A100 GPU MIG instances to process inference requests for multiple models to be simultaneously executed on the independent MIG partitions within a single A100 GPU to maximize utilization. As the compute required for your deployed ML pipelines increase (e.g. a sudden surge in inference requests to service), GKE can automatically scale to additional node-pools with MIG partitions. In addition, the NVIDIA Collective Communication Library (NCCL) further optimizes multi-GPU, multi-node communications within the GKE cluster to ensure high bandwidth, high throughput, and low latency.
NVIDIA Solution Stack to Develop & Deploy End-to-End Machine Learning Pipelines
To develop ML application pipelines that are scalable and are optimized to leverage the full benefits of the MIG capabilities for GPU utilization on Google Cloud, NVIDIA offers several GPU-accelerated end-to-end application-specific frameworks – NVIDIA Merlin for end-to-end recommendation systems, NVIDIA Jarvis for multimodal conversational AI services, and NVIDIA RAPIDS for data analytics pipelines. All NVIDIA optimized frameworks, SDKs, pre-trained models, and performance-optimized libraries can be accessed from NGC Catalog, a hub for GPU-accelerated software.
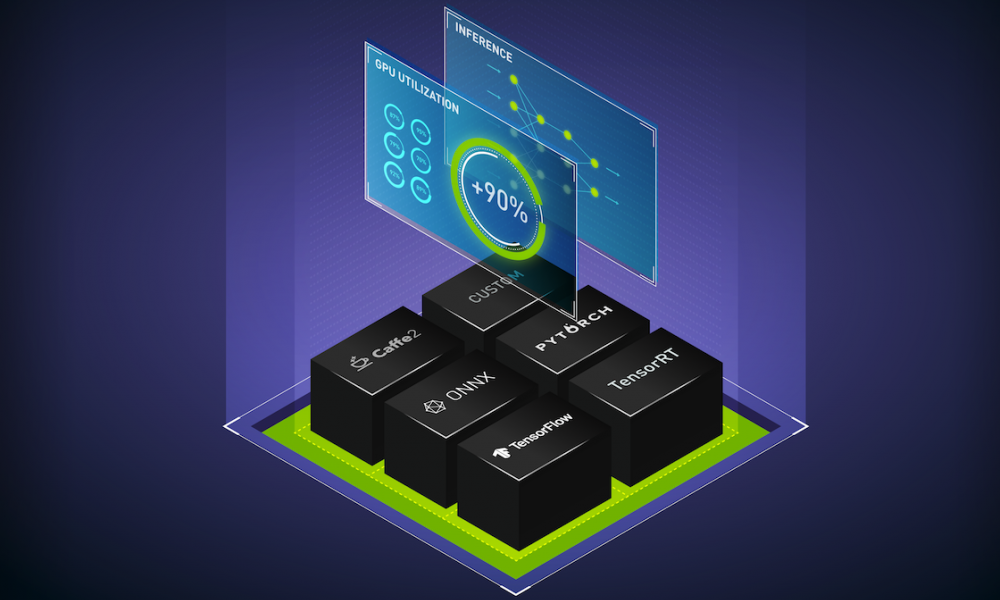
Deploying the ML pipelines into production at scale on a GKE managed cluster is further simplified with NVIDIA Triton Inference Server software. This open-source inference serving software lets teams deploy trained AI models from any framework (TensorFlow, TensorRT, PyTorch, ONNX Runtime, or a custom framework), from local storage or Google Cloud’s managed storage products on any GPU- or CPU-based infrastructure. Triton Inference Server software is now directly available on the GCP Marketplace to seamlessly deploy, serve, monitor performance and dynamically scale multiple AI inference requests on MIG-enabled GKE clusters.
Bringing it All Together
GKE’s managed Kubernetes services combined with the flexibility of the A100 MIG feature and NVIDIA’s GPU-optimized solution stack for accelerating ML pipelines helps address both the development and infrastructure management challenges of productizing end-to-end ML pipelines.
To see these technologies in action with a real example, check out this GTC21 Session – “Gain Competitive Advantage using MLOps: Kubeflow and NVIDIA Merlin and Google Cloud” to learn how GKE, NVIDIA A100 MIG, and NVIDIA’s GPU-optimized solution stack can be used to build and deploy an end-to-end recommender system.
