
Data is the fuel of modern business, but relying on older CPU-based Apache Spark pipelines introduces a heavy toll. They’re inherently slow, require large infrastructure, and lead to massive cloud expenditure. As a result, GPU-accelerated Spark is becoming a leading solution, providing lightning-fast performance using parallel processing. This improved efficiency reduces cloud bills and saves valuable development hours.
Building on this foundation, we introduce a smart and efficient way to migrate existing CPU-based Spark workloads running on Amazon Elastic MapReduce (EMR). Project Aether is an NVIDIA tool engineered to automate this transition. It works by taking existing CPU jobs and optimizing them to run on GPU-accelerated EMR using the RAPIDS Accelerator for performance benefits.
What is Project Aether?

Project Aether is a suite of microservices and processes designed to automate migration and optimization for the RAPIDS Accelerator, effectively eliminating manual friction. This aims to reduce migration time from CPU to GPU Spark Jobs through:
- A prediction model for potential GPU speedup using recommended bootstrap configurations.
- Out-of-the-box testing and tuning of GPU jobs in a sandbox environment.
- Smart optimization for cost and runtime.
- Full integration with Amazon EMR supported workloads.
Amazon EMR Integration
Now supporting the Amazon EMR platform, Project Aether automates the management of GPU test clusters and the conversion and optimization of Spark steps. Users can use the services provided to migrate existing EMR CPU Spark workloads to GPUs.
Setup and configuration
To get started, you’ll need to meet the following prerequisites.
- Amazon EMR on EC2: AWS account with GPU instance quotas
- AWS CLI: Configured with aws configure
- Aether NGC: Request access, configure credentials with ngc config set, and follow Aether installation instructions.
Configure Aether for EMR
Once the Aether package is installed, configure the Aether client for the EMR platform using the following commands:
# Initialize and list config
$ aether config init
$ aether config list
# Select EMR platform and region
$ aether config set core.selected_platform emr
$ aether config set platform.emr.region <region>
# Set required EMR s3 paths
$ aether config set platform.emr.spark_event_log_dir <s3_path_for event_logs>
$ aether config set platform.emr.cluster.artifacts_path <s3_path_for uploading_aether_artifacts>
$ aether config set platform.emr.cluster.log_path <s3_path_for_cluster_log_uri>
Example Aether EMR migration workflow
The Aether CLI tool provides several modular commands for running the services. Each command displays a summary table and tracks each run in the job history database. At any point, refer to “4. Migrate: Report and Recommendation” for viewing the tracked jobs. Use the --help option for more details on each aether command.
The example EMR workflow requires starting with an existing Spark step with step ID s-XXX that ran on a CPU EMR cluster with a cluster ID j-XXX. For more information on submitting steps to EMR clusters, refer to the Amazon EMR documentation.
The migration process is broken down into four core phases: predict, optimize, validate, and migrate.
1. Predict: Qualification
Determine a CPU Spark job’s viability for GPU acceleration and generate initial optimization recommendations.
The qualification tool uses the QualX machine learning system’s XGBoost model to predict potential GPU speedup and compatibility based on workload characteristics derived from the CPU event log.
om the CPU event log.
Input:
- CPU event log obtained from EMR step and cluster API, or provided directly.
Output:
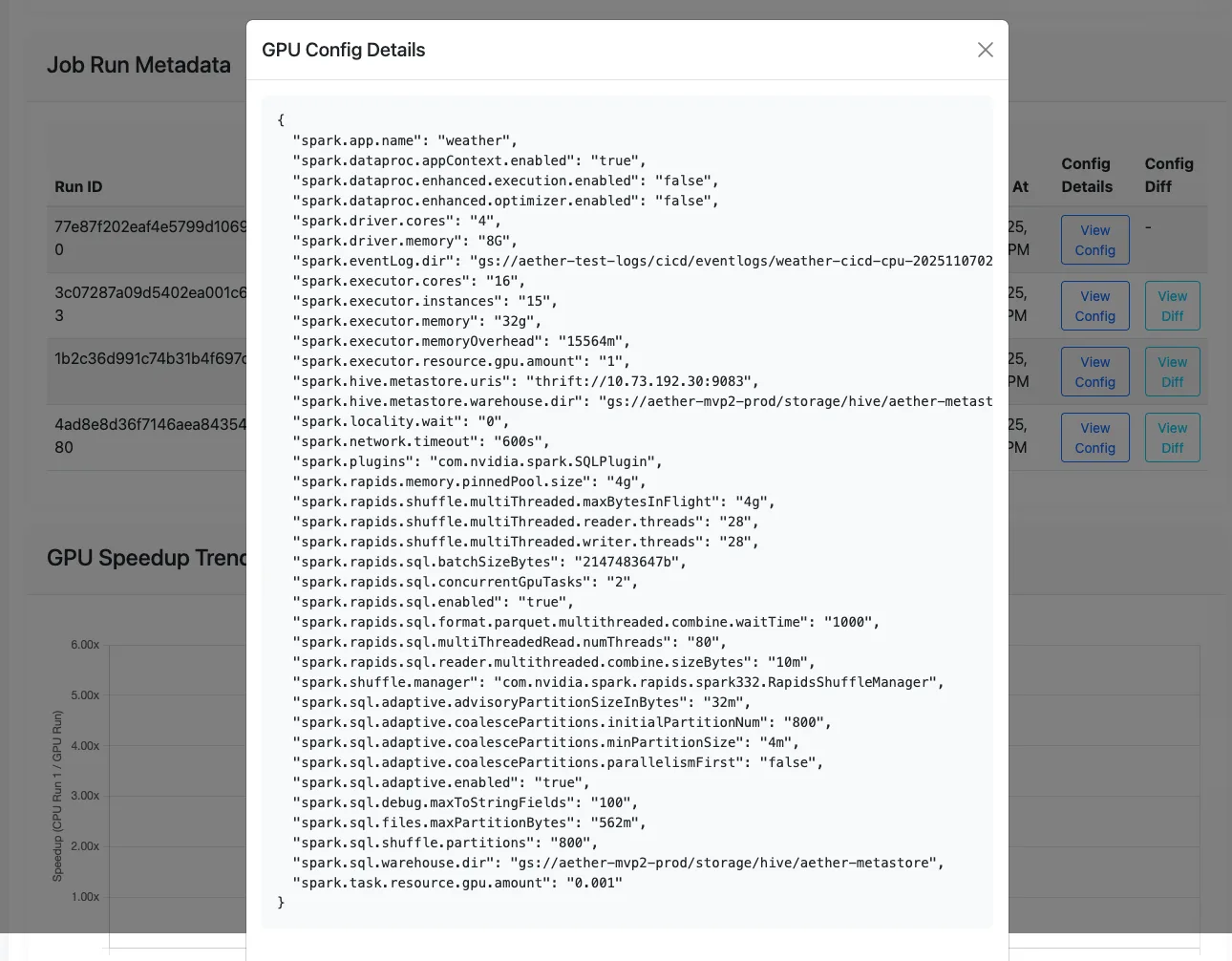
- Recommended Spark configuration parameters generated by the AutoTuner.
- Recommended GPU cluster shape with instance types and counts optimized for cost savings.
- Aether Job ID to track this job and any subsequent job runs.
Commands:
# Option 1: Use Platform IDs
$ aether qualify --platform_job_id <cpu_step_id> --cluster_id <cpu_cluster_id>
# Option 2: Provide event log path directly
$ aether qualify --event_log <s3_or_local_event_log_path>
2. Optimize: Automatic testing and tuning
Achieve optimal performance and cost savings by testing the job on a GPU cluster and iteratively tuning the Spark configuration parameters.
Create the GPU test cluster with the Cluster service, then optimize the GPU job with the tune service, which iteratively runs submit and profile:
- Submit: The job submission service submits the Spark job to a GPU cluster with the specified configurations.
- Profile: The profile service uses the profiling tool to process the GPU event logs to analyze bottlenecks and generate new Spark configuration parameters to increase performance and/or reduce cost.
Input:
- Recommended Spark configuration parameters from qualify output for the GPU job.
- Recommended GPU cluster shape from qualify output to create the GPU cluster.
Output:
- Best GPU configuration is selected from the run with the lowest duration among all tuning iterations.
Commands:
A. Create a test EMR GPU cluster:
# Option 1: Use the recommended cluster shape ID with a default cluster configuration
$ aether cluster create --cluster_shape_id <recommended_cluster_shape_id_from_qualify>
# Option 2: Provide a custom configuration file
$ aether cluster create --cluster_shape_id <recommended_cluster_shape_id_from_qualify> --config_file <custom_cluster_yaml_file>
B. Submit the GPU step to the cluster:
# Submit the job to the cluster using config_id and cluster_id
$ aether submit --config_id
<recommended_spark_config_id_from_qualify> --cluster_id
<gpu_cluster_id_from_create>
C. Profile the GPU run to generate new recommended Spark configs:
# Profile the job using the step_id and cluster_id
$ aether profile --platform_job_id <gpu_step_id_from_submit>
--cluster_id <gpu_cluster_id_from_create>
D. Tune the job iteratively (submit + profile loop):
# Tune the job for 3 iterations
$ aether tune --aether_job_id <aether_job_id> --cluster_id
<gpu_cluster_id_from_create> --min_tuning_iterations 3
3. Validate: Data integrity check
Confirm the GPU job’s output integrity by ensuring its results are identical to the original CPU job.
The validate service compares key row metrics retrieved from the event logs, specifically focusing on rows read and rows written, between the best GPU run and the original CPU run.
Command:
# Validate the CPU and GPU job metrics
$ aether validate --aether_job_id <aether_job_id>
4. Migrate: Report and recommendation
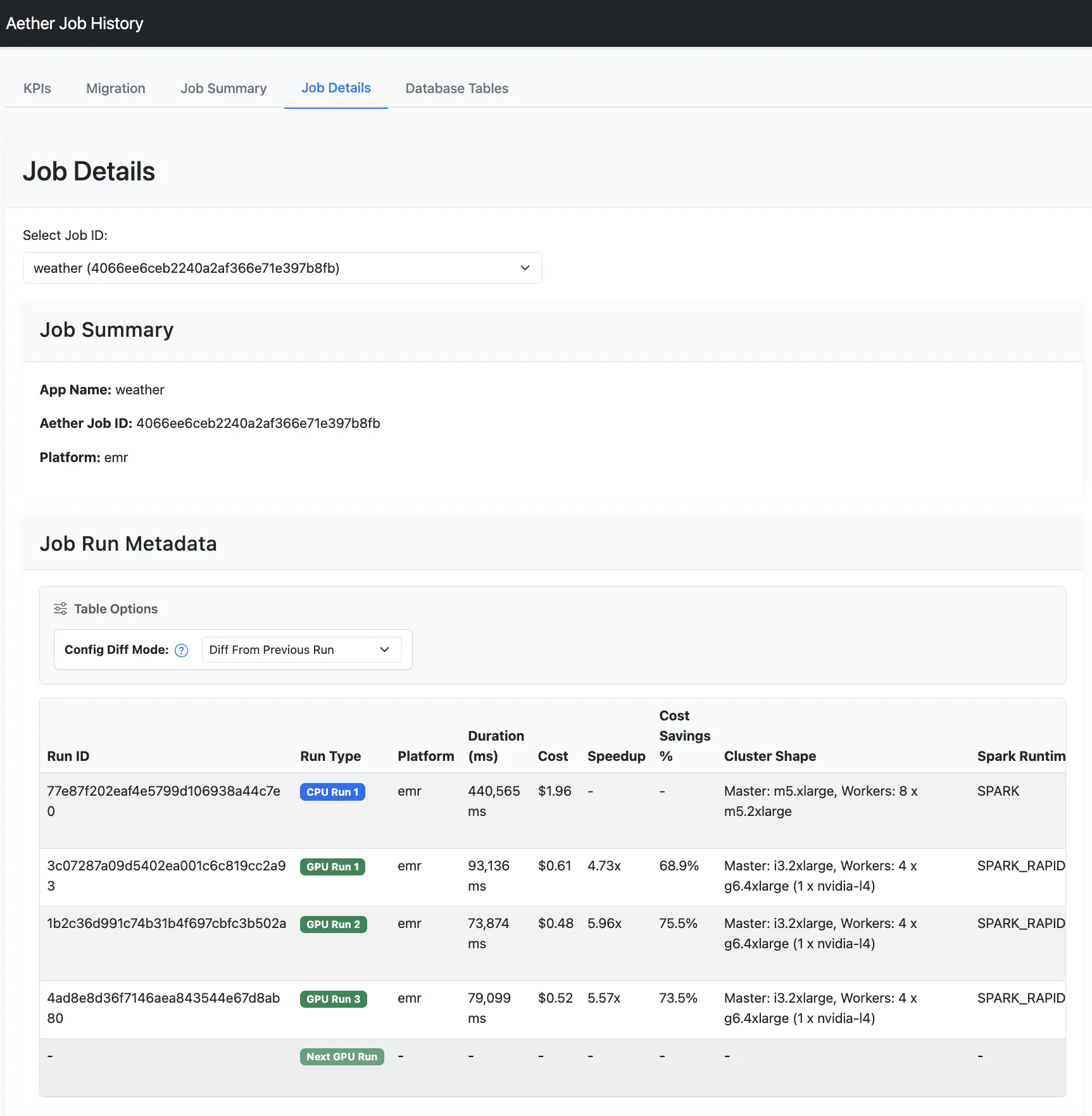
View detailed reports of the tracked jobs in the job history database, and see per-job migration recommendations with the optimal Spark configuration parameters and GPU cluster configurations.
The report service provides CLI and UI options to display:
- Key performance indicators (KPIs): The total speedup and total cost savings across all jobs.
- Job list: Per-job speedup, cost savings, and migration recommendations.
- Job details: All job run (original CPU run and GPU tuning runs) metrics and details for a job.
Commands:
# List all job reports
$ aether report list
# View all job runs for a specific job
$ aether report job --aether_job_id <aether_job_id>
# Start the Aether UI to view the reports in a browser
$ aether report ui
5. Automated run
Combine all of the individual services above into a single automated Aether run command:
# Run full Aether workflow on CPU event log
$ aether run --event_log <s3_or_local_event_log_path>
Conclusion
Project Aether is a powerful tool for accelerating big data processing, reducing the time and cost associated with migrating and running large-scale Apache Spark workloads on GPUs.
To try it out for large-scale migrations of Apache Spark workloads, apply for Project Aether access. To learn more about the RAPIDS plugin, see the documentation for RAPIDS Accelerator for Apache Spark.









