
Machine learning harnesses computing power to solve a variety of ‘hard’ problems that seemed impossible to program using traditional languages and techniques. Machine learning avoids the need for a programmer to explicitly program the steps in solving a complex pattern-matching problem such as understanding speech or recognizing objects within an image. NVIDIA aims to bring machine learning to Vulkan programmers though the Cooperative Matrix vendor extension.

Machine learning-based applications train a network of simulated neurons, a neural network, by feeding it a large number of examples and then giving feedback on the generated responses until the network achieves a desired task. This is similar to teaching a human baby to recognize words and pictures through reading them picture books!
Once trained, the network can be deployed in an application, fed real-world data and generating or inferencing useful responses in real-time. The amount of compute power needed to run a trained neural network in real-time is intense and parallelizable. This is why the compute power of GPUs substantially accelerate inferencing on many platforms that have a GPU available, from mobile phones to supercomputers.
These applications often call into a software inferencing engine highly-optimized to run the necessary inferencing calculations through the GPU as quickly as possible, such as NVIDIA’s TensorRT. The latest generations of GPUs, such as those based on NVIDIA’s Turing and Volta architectures, even have dedicated processing blocks to run those inferencing operations significantly faster than using the traditional processors found in previous GPUs.

Inferencing in Real Time
Real-time graphics applications such as gaming comprise an important emerging use of neural network inferencing. Machine learning is potentially useful in a wide variety of ways to make games more realistic and immersive, including:
- Making non-player characters behave and respond more believably
- Modeling complex in-game systems and dynamics that respond realistically to player actions
- Dynamically synthesizing beautiful and complex environments
These represent just a few of the groundbreaking possibilities.
The inferencing operations in an interactive application such as a game coexist alongside numerous other real-time tasks juggled by the game engine. These inferencing operations are often delicately intertwined in the various real-time engine loops, such as graphics rendering, physics simulation, user interaction, and much more. This makes integrating a large standalone inferencing engine such as TensorRT difficult to integrate into a game. Having two independent run-time engines that can only communicate in a coarse-grained way, unable to easily share assets and resources in the game, is difficult to manage for efficiency and performance.
Enabling the developer to access inferencing acceleration from the same API that they are already using to control everything else flowing through the GPU seems like a much better solution for games. If that developer desires to access state-of-the-art GPU rendering and compute functionality in a way that doesn’t lock them to a single platform, then that API is Vulkan!
NVIDIA has led the industry in developing and deploying inferencing acceleration on GPUs. Now we are turning our attention to enabling developers to access machine learning acceleration through the Vulkan cross-platform GPU API. We have developed a vendor extension to bake inferencing into Vulkan. NVIDIA is making proposals to the Vulkan working group at Khronos—the standards consortium which manages Vulkan—to help the industry cooperatively create a true multi-vendor solution to machine learning acceleration within the Vulkan open standard.
Cooperative Matrix Extension
So, what could Vulkan inferencing acceleration look like?
If you analyze the basic mathematical operations needed for neural network inferencing, you’ll find that execution time is dominated by multiplying together large matrices, typically at a low numerical precision—16-bit floating point or less. However, the traditional mechanisms that Vulkan provides for spreading work over the GPU’s parallel processors focus on graphics pipeline operations and are not ideal for processing this new tensor data type.
Programmers can and do use existing Vulkan functionality to accelerate large matrix multiplies, but typically end up with complex code that has to describe each individual math operation as well as how to efficiently feed those operations with data. This code often ends up being optimized for specific GPUs, making it hard to support and port efficiently to other GPUs. More importantly, such low-level code robs the GPU vendor of the opportunity to optimize tensor operations in their Vulkan driver or even use dedicated tensor acceleration hardware.
This problem is easily solved by providing one new primitive operator—matrix multiplies. By making matrices an opaque data type, we can enable GPU vendors to optimize the matrix multiply operator in a way that best suits their hardware, while enabling the developer to write much simpler inferencing code that can be easily and efficiently ported across multiple platforms. This is consistent with Vulkan’s philosophy of providing the programmer with low level, explicit control of GPU resources.
NVIDIA’s VK_NV_cooperative_matrix Vulkan vendor extension enables programmers to specify matrix operators of the form D = A*B+C in which the sizes of the matrices are MxNxK. (A = MxK, B = KxN, C&D=MxN); where M is the number of rows and N is the number of columns. Programmers select a precision of 16- or 32-bit floating point. We have found this to be a surprisingly clean and elegant programming model with good performance and usability for inferencing acceleration.
But why is the extension called “Cooperative Matrix”? This refers to how the extension ensures efficient parallel processing on the GPU. Explaining this requires that we need to use a few Vulkan terms:
- Individual parallel tasks that run on a single compute unit of a GPU are called invocations
- The data on that compute unit is the local workgroup.
- Invocations running compute shaders can share data in the local workgroup via shared memory.
- Vulkan 1.1 introduced an important new feature called subgroups which enables a subset of invocations to share data in a set of powerful parallel operations at a significantly higher performance than shared memory.
The new matrix type defined by the Cooperative Matrix Vulkan extension spreads the required matrix storage and computations across a set of invocations, typically a subgroup, and all the invocations in the subgroup cooperate efficiently to compute the result. Vulkan shaders can then use and combine these efficient cooperative matrix operations into larger inferencing solutions. Additionally, if the GPU includes dedicated hardware for high-speed matrix operations, such as the Tensor Cores on Turing GPUs, then the Cooperative Matrix extension can tap into the power of this acceleration with no application changes.
Implementing the Extension
The following code snippet illustrates how you might employ the extension. You begin by enabling the extension:
#extension GL_NV_cooperative_matrix : enable
Then you can use the extension in a manner similar to this example:
// On each iteration, load a row of cooperative matrices from matrix A,
// load a column of cooperative matrices from matrix B, and multiply all
// pairs of those matrices.
for (uint chunkK = 0; chunkK < K; chunkK += TILE_K) {
fcoopmatNV<16, gl_ScopeSubgroup, lM, lK> matA[C_ROWS];
[[unroll]] for (uint i = 0; i < C_ROWS; ++i) {
uint gi = TILE_M * tileID.y + lM * i;
uint gk = chunkK;
coopMatLoadNV(matA[i], inputA.x, strideA * gi + gk, strideA, false);
}
fcoopmatNV<16, gl_ScopeSubgroup, lK, lN> matB;
[[unroll]] for (uint j = 0; j < C_COLS; ++j) {
uint gj = TILE_N * tileID.x + lN * j;
uint gk = chunkK;
coopMatLoadNV(matB, inputB.x, strideB * gk + gj, strideB, false);
[[unroll]] for (uint i = 0; i < C_ROWS; ++i) {
result[i][j] = coopMatMulAddNV(matA[i], matB, result[i][j]);
}
}
}
Performance
NVIDIA has created a benchmark application in addition to the specifications and drivers. You can find the source in the Cooperative Matrix Github repo. Using the Vulkan extension revealed significant speedups versus code using traditional Vulkan scalar math operations by seamlessly and efficiently harnessing the power of Turing Tensor Cores, as shown in figure 1.
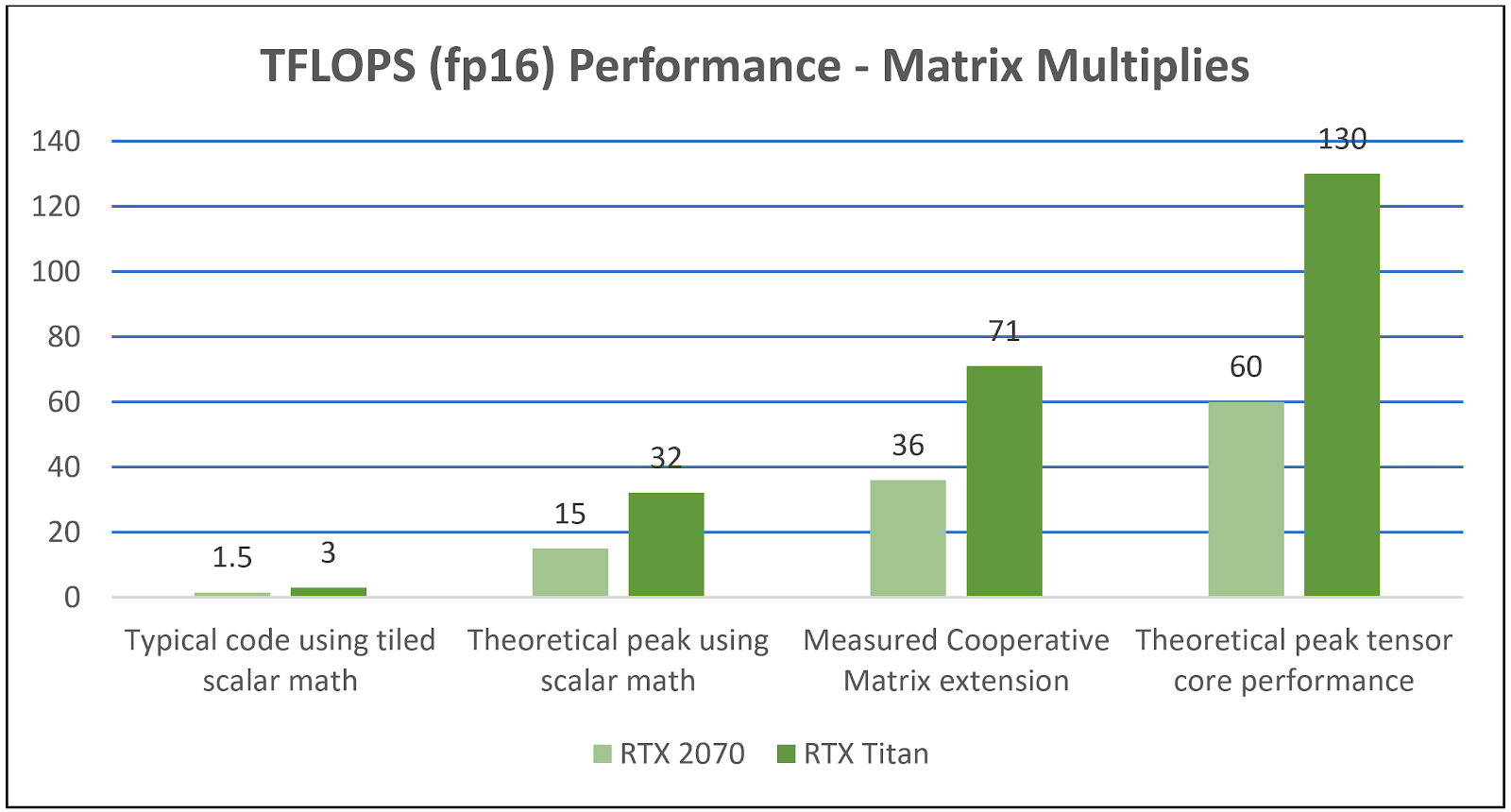
Try It Yourself
If the Cooperative Matrix Vulkan extension is interesting to you, you can try it out right now! It is shipping for Turing-based GPUs in NVIDIA driver versions 419.09 (Windows) and 418.31.03 (Linux) available here:https://developer.nvidia.com/vulkan-driver. Links to all the relevant specifications are here: https://github.com/KhronosGroup/Vulkan-Docs/issues/923. Please provide your feedback to us if you try it out.
We would love to hear about your experiences as we work with the industry, through Khronos, to bring cross-vendor inferencing solutions to the Vulkan standard. Please leave a comment below if you have questions or other feedback.