Today, smartphones, the most popular device for taking pictures, can capture images as large as 4K UHD (3840×2160 image), more than 25 MB of raw data. Even considering the embarrassingly low HD resolution (1280×720), a raw image requires more than 2.5 MB of storage. Storing as few as 100 UHD images would require almost 3 GB of free space.
Clearly, if you store data this way, you quickly run out of space. This is where image compression comes in handy. The well-known JPEG format allows you to shrink the size of an image by an order of magnitude, from 30 MB to 3 MB.
For deep learning computer vision applications, where training datasets of several million samples are common, compression and efficient storage of image data are more important than ever. Industry-standard datasets, such as ImageNet and COCO, use the JPEG format to store data. Thanks to that, ImageNet occupies just 150 GB instead of a staggering 32 TB of uncompressed data.
Compression is great—it allows you to save a lot of disk space. Unfortunately, it highlights another challenge, one that is particularly noticeable in computer vision–related, deep learning applications: image decompression is a compute-intensive task. It is, in fact, the most time-consuming task of data processing pipelines, up to the point where JPEG decoding can starve your training running on GPUs.
Having faced this problem firsthand, we developed NVIDIA Data Loading Library (DALI) to accelerate image decoding, augmenting and preprocessing of pipelines. It alleviates this CPU bottleneck. DALI accelerates image decoding by leveraging nvJPEG, a CUDA library for JPEG decoding. Not only that, you could take your data processing pipeline, from decoding through augmentation up to the training, to the next level of performance.
Recently we introduced the A100 GPU, which is based on the NVIDIA Ampere architecture. It adds a hardware JPEG decoder to further raise the performance bar. It is a dedicated hardware block responsible for decoding JPEG images.
Prior architectures didn’t have such hardware units, and JPEG decoding was a pure software (CUDA) solution that used CPU and GPU-programmable SM units. With a dedicated hardware unit, decoding no longer competes for CUDA cores with other compute-intensive tasks such as forward and backward feed during training of neural networks.
It is exposed through the nvJPEG library which is a part of CUDA toolkit. For more information, see Leveraging the Hardware JPEG Decoder and NVIDIA nvJPEG Library on NVIDIA A100 GPUs. As a DALI user, you automatically benefit from hardware-accelerated decoding with no code changes at your end, as DALI and NVJPEG integration is abstracted away.
Using JPEG hardware decoder with DALI makes this JPEG hardware decoder functionality easily accessible for deep learning applications. If you use the DALI ImageDecoder with a mixed backend, you don’t have to change your code. Get the latest DALI version for CUDA 11 and enjoy NVIDIA Ampere architecture-powered, hardware-accelerated, JPEG decoding.
The following code example shows a DALI pipeline that loads images and decodes them using GPUs:
class SimplePipeline(Pipeline): def __init__(self, batch_size, num_threads, device_id): super().__init__(batch_size, num_threads, device_id, seed = 12) self.input = ops.FileReader(file_root = image_dir) self.decode = ops.ImageDecoder(device = 'mixed', output_type = types.RGB) def define_graph(self): jpegs, labels = self.input() images = self.decode(jpegs) return images, labels
Hybrid GPU decoder
With DALI, you can go one step further and combine the hardware, software, and CUDA-based approaches to JPEG decoding, running them in parallel to obtain even higher throughput. Figure 1 shows how one such pipeline could work.

You can split the work by adjusting the hw_decoder_load parameter to decide how much of the decoding load goes to the hardware decoder and how much is done by GPU-accelerated CUDA approach at the same time.
Keep in mind that the results depend on the existing GPU workload (how much the GPU already must do) and can be adjusted empirically to maximize throughput for every use case.
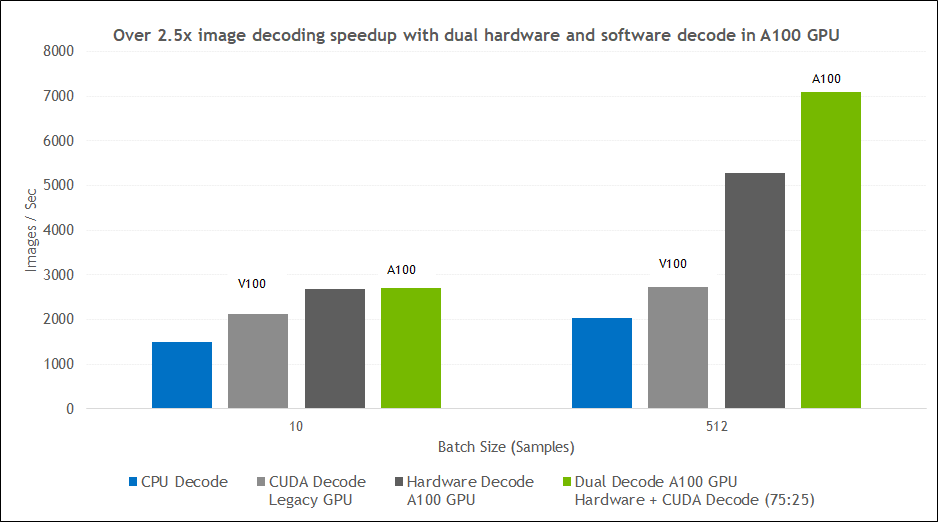
Figure 2 provides numbers for a 75:25 ratio split. However, when the GPU is already occupied with some other work such as forward propagation and backpropagation, you might find the sweet spot by offloading a larger part of the image decoding task to the hardware decoder, like 80% or even more.
The following code example shows a pipeline that offloads 75% of the image decoding task to the hardware decoder:
class SimplePipeline(Pipeline): def __init__(self, batch_size, num_threads, device_id): super().__init__(batch_size, num_threads, device_id, seed = 12) self.input = ops.FileReader(file_root = image_dir) self.decode = ops.ImageDecoder(device = 'mixed', output_type = types.RGB, hw_decoder_load=0.75) def define_graph(self): jpegs, labels = self.input() images = self.decode(jpegs) return images, labels
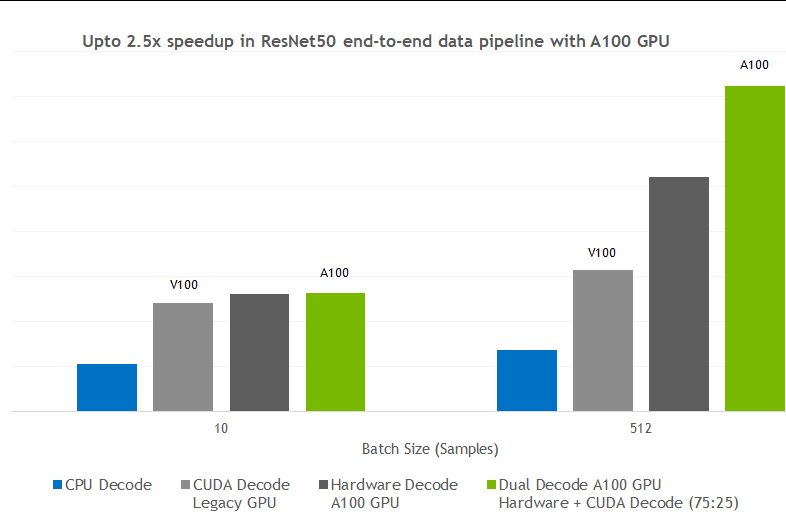
Figure 2 shows the kind of performance boost that you can expect when switching decoding with DALI from CPU to various GPU-based approaches. The tests were performed for different batch sizes, for the CPU libjpeg-turbo solution, Volta CUDA decoding, A100 hardware JPEG decoder, and A100 dual hardware and CUDA decoder.
Test configuration for Figures 2 and 4:
- NVIDIA V100 GPU: CPU – E5-2698 v4@2GHz 3.6GHz Turbo (Broadwell) HT On, GPU – Tesla V100-SXM2-16GB(GV100) 1*16160 MiB 1*80 SM, GPU Video Clock 1312, 4 threads used in DALI pipeline
- NVIDIA A100 GPU: CPU – Platinum 8168@2GHz 3.7GHz Turbo (Skylake) HT On, GPU – A100-SXM4-40GB(GA100) 140557 MiB 1108 SM, GPU Video Clock 1095, 4 threads used in DALI pipeline
- CPU: CPU – Platinum 8168@2GHz 3.7GHz Turbo (Skylake) HT On, Dataset – training set of ImageNet, 4 threads used in DALI pipeline
Figure 3 shows a typical ResNet50-like image classification pipeline.

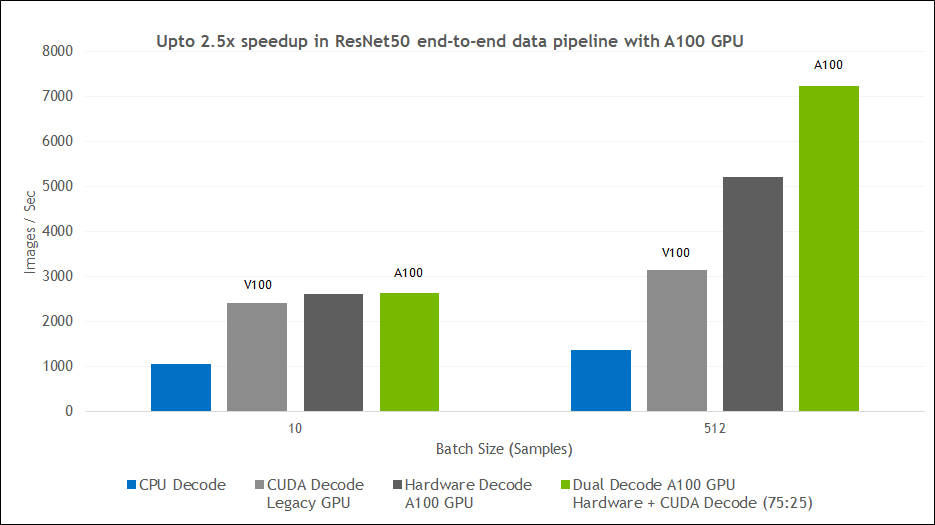
Figure 4 shows the end-to-end data pipeline speedup for the ResNet-50 model. The overall pipeline speedup looks identical to the decoding speedup in Figure 2 earlier.
Here are a couple of takeaways:
- Decoding is the most compute-intensive aspect of data preprocessing pipeline for image-based workloads. By accelerating that, your entire pipeline sees the benefits.
- End-to-end training throughput is heavily dependent on how fast you can supply your GPUs with data (the output of the pipeline). DALI is purpose-built for ensuring that your GPUs are constantly fed with data. For information about how to determine if your data pipeline is CPU-bottlenecked and how DALI can help, see Case Study: ResNet50 with DALI.
Summary
Download the latest version of prebuilt DALI binaries with NVIDIA Ampere architecture support (version 0.22 or newer). DALI supporting Ampere HW JPEG decoder will be available in upcoming NGC deep learning framework containers.
For a detailed list of new features and enhancements, read the latest release notes. For a deep dive into DALI and what’s on the roadmap, watch the GTC 2020: Fast Data Pre-Processing with NVIDIA Data Loading Library (DALI) tech talk. Source code and Jupyter notebooks are available in NVIDIA/DALI GitHub repo, as well in DALI User Guide.
We welcome your feedback and suggestions for new features.
